The goal of the post is to share with you how easy it is to load a llama 405b model in Runpod but also how it might be costly if you don’t know some things in advance, so I hope this post will help you to save these precious gpu minutes!
First, Llama 405b model is huge:
Let’s talk GPU!
You need the right choice of GPU and high disk memory to save model parameters and give some overhead for your experiment, like doing inference and saving some internal activations.
Some good options are H100, A100 and H200 machines:
The H200 currently wins on both cost and inference speed. With FP8 quantization and higher VRAM per GPU, you only need 5 H200s compared to 8 A100/H100 GPUs for the same setup. This makes the H200 cheaper overall ($17.95/hr vs $21.52/hr for H100), while also giving roughly 3× faster inference.
Providers
There are some very good GPU providers out there such as: Runpod, vast.ai, lambda. You can browse some websites comparing different gpu providers, like here e.g. I decided to go with RunPod because of its reliability, simplicity, and competitive pricing:
These are FOUR tips you should know to save your GPU minutes!
Preparation is a key! Develop locally first, package and test your code on your local machine before deploying to RunPod to avoid wasting GPU time on debugging.
Prepare startup_script to load your credentials and install necessary packages like poetry. You will scp it to runpod and run it there.
Before spinning up an expensive gpu setup, test your pipeline end to end on the smallest model from this family, in my examples I used llama 1b model and fixed all errors/bugs with minimal costs.
Code and storage:
For active code and temporary data use /root directory as it is on NVMe SSD, not network storage, significantly faster read/write speeds for data processing.
/workspace is RunPod's persistent network storage, so keep your models and cache and data input/output there. Also, /workspace memory is much larger.
To setup this up it’s essential to set hugging face and transformer cache env vars;
Network Volume is your friend! When you save all your cache, data and model under /workspace there is still risk of not being able to spin up a new pod with the same data. if no pods are available, you may get downgraded to a zero-GPU pod without being able to spin up a new GPU pod 🙁 Remember Llama model is HUGE and it takes around 30 minutes to download it, so you don’t want to waste your money on downloading model each time you create a new pod, you want it to be accessible for different gpu/cpu setups. So this is where network volume comes in 🙂!
independent of your Pod
fast: Typical transfer speeds: 200–400 MB/s, with possible peaks up to 10 GB/s
cheap: $0.07 per GB per month for the first 1 TB; $0.05 per GB per month beyond that. It’s very easy to set up, BUT make sure you check the data center you choose has your target GPUs and preferably multiple GPU types available as some GPU types may not always be available.
Model Loading Optimization:
Trick 1: When loading large models on RunPod, use these flags:
low_cpu_mem_usage = True: Despite its name, this flag helps with both CPU and GPU memory:
Without this flag: Loads all weights at once, creating temporary copies that cause memory spikes of 2-3x the model size.
With this flag: Builds empty model first, then loads weights one tensor at a time, immediately assigning each to its target layer. Peak memory stays close to the final model size. This allows loading larger models on smaller RunPod instances
device_map="auto", enables direct loading to target devices across multiple GPUs without staging everything in CPU RAM first.
Trick 2: Use FastAPI for model loading and serving. If running multiple experiments, use FastAPI to load the model once and create API endpoints. It also keeps experiment code modular and separate from model loading so that you can make constant changes to it without having to load model on every change:
And of course, don’t forget to terminate your runpod :) Please share any efficiency tips for working with expensive GPUs in the comments
The goal of the post is to share with you how easy it is to load a llama 405b model in Runpod but also how it might be costly if you don’t know some things in advance, so I hope this post will help you to save these precious gpu minutes!
First, Llama 405b model is huge:

Let’s talk GPU!
You need the right choice of GPU and high disk memory to save model parameters and give some overhead for your experiment, like doing inference and saving some internal activations.
Some good options are H100, A100 and H200 machines:
The H200 currently wins on both cost and inference speed. With FP8 quantization and higher VRAM per GPU, you only need 5 H200s compared to 8 A100/H100 GPUs for the same setup. This makes the H200 cheaper overall ($17.95/hr vs $21.52/hr for H100), while also giving roughly 3× faster inference.
Providers
There are some very good GPU providers out there such as: Runpod, vast.ai, lambda. You can browse some websites comparing different gpu providers, like here e.g.
I decided to go with RunPod because of its reliability, simplicity, and competitive pricing:
These are FOUR tips you should know to save your GPU minutes!
To setup this up it’s essential to set hugging face and transformer cache env vars;
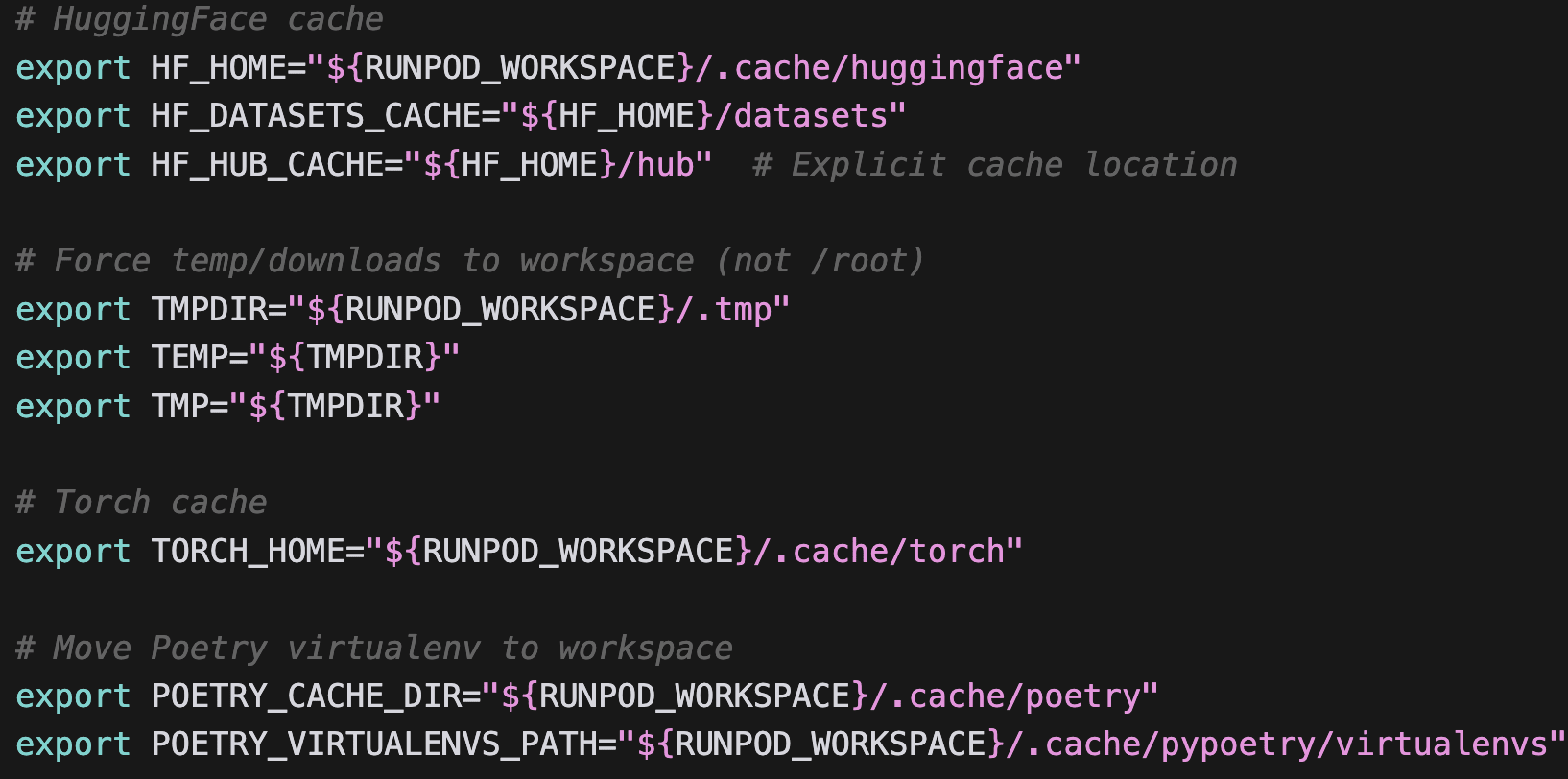
This script is an example to do this:
So this is where network volume comes in 🙂!
It’s very easy to set up, BUT make sure you check the data center you choose has your target GPUs and preferably multiple GPU types available as some GPU types may not always be available.
Trick 1: When loading large models on RunPod, use these flags:

Without this flag: Loads all weights at once, creating temporary copies that cause memory spikes of 2-3x the model size.
With this flag: Builds empty model first, then loads weights one tensor at a time, immediately assigning each to its target layer. Peak memory stays close to the final model size. This allows loading larger models on smaller RunPod instances
Trick 2: Use FastAPI for model loading and serving. If running multiple experiments, use FastAPI to load the model once and create API endpoints. It also keeps experiment code modular and separate from model loading so that you can make constant changes to it without having to load model on every change:
And of course, don’t forget to terminate your runpod :) Please share any efficiency tips for working with expensive GPUs in the comments