I went down a rabbithole on inference-from-goal-models a few years ago (albeit not coalitional ones) -- some slightly scattered thoughts below, which I'm happy to elaborate on if useful.
- A great toy model is decision transformers: basically, you can make a decent "agent" by taking a predictive model over a world that contains agents (like Atari rollouts), conditioning on some 'goal' output (like the player eventually winning), and sampling what actions you'd predict to see from a given agent. Some things which pop out of this:
- There's no utility function or even reward function
- You can't even necessarily query the probability that the goal will be reached
- There's no updating or learning -- the beliefs are totally fixed
- It still does a decent job! And it's very computationally cheap
- And you can do interp on it!
- There's no utility function or even reward function
- It turns out to have a few pathologies (which you can precisely formalise)
- It has no notion of causality, so it's easily confounded if it wasn't trained on a markov blanket around the agent it's standing in for
- It doesn't even reliably pick the action which most likely leads to the outcome you've conditioned on
- Its actions are heavily shaped by implicit predictions about how future actions will be chosen (an extremely crude form of identity), which can be very suboptimal
- But it turns out that these are very common pathologies! And the formalism is roughly equivalent to lots of other things
- You can basically recast the whole reinforcement learning problem as being this kind of inference problem
- (specifically, minimising variational free energy!)
- It turns out that RL largely works in cases where "assume my future self plays optimally" is equivalent to "assume my future self plays randomly" (!)
- it seems like "what do I expect someone would do here" is a common heuristic for humans which notably diverges from "what would most likely lead to a good outcome"
- humans are also easily confounded and bad at understanding the causality of our actions
- language models are also easily confounded and bad at understanding the causality of their outputs
- fully fixing the future-self-model thing here is equivalent to tree searching the trajectory space, which can sometimes be expensive
- You can basically recast the whole reinforcement learning problem as being this kind of inference problem
This paper is really cool!
A random fun thing that I connected it to is how civilization can be seen as an engineering process that enables lower context horizon planning. The impersonality of a market is essentially a standardising force that allows you to not have to deal with long chains of interpersonal connections which enables you to model the optimal policy as close to a random policy for the average person will behave in a standardised way (to work for a profit).
This might connect to Henrich's stuff on market integration producing more impersonal/rule-based cognition. Maybe populations adapt to environments where random-policy-Q-functions are informative, and we call that adaptation "WEIRD psychology"?
Something something normalization and standardization as horizon-reduction...
I didn’t read the paper carefully, but my gut reaction on seeing the claim is that it’s a fairly straightforward benefit of better exploration properties.
Most deep RL algorithms bootstrap from random policies. These policies explore randomly. So the early Q functions learned (or value functions, etc) will be those modelling a random policy. If it turns out that this leads to an optimal policy - well that seems really easy. Actually it’d be kind of weird if deep RL couldn’t converge in this simple case.
I expect this claim to no longer hold if the exploration strategy is changed.
I agree with you but I think you might be missing the point, let me add some detail from the cultural evolution angle. (because I do think the paper is actually implicitly saying something interesting about mean-field and similar approaches.)
One of the main points from Henrich's WEIRDest People in the World is between internalized identity and relational identity. WEIRD populations develop internal guilt, stable principles, context-independent rules—your identity lives inside you. Non-WEIRD populations have identities that exist primarily in relation to specific others: your tribe, your lineage, your patron. Who you are depends on who you're interacting with.
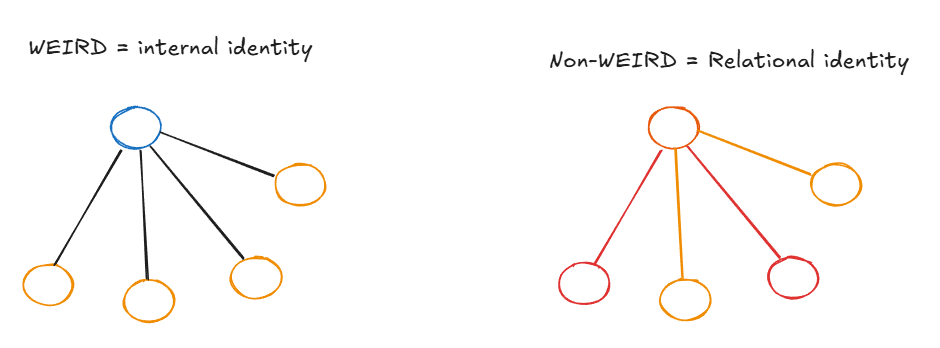
Now connect this to the effective horizon result. Consider the king example: if you send tribute to a specific king, whether that's a good action depends enormously on that king's specific future response—does he ally with you, ignore you, betray you? You can't replace "the king's actual behavior" with "average behavior of a random agent" and preserve the action ranking. The random policy Q-function washes out exactly the thing that matters. The mean field approximation fails because specific node identities carry irreducible information.
Now consider a market transaction instead. You're trading with someone, and everyone else in the economy is also just trading according to market prices. It basically doesn't matter who's on the other side—the price is the price. You can replace your counterparty with a random agent and lose almost nothing. The mean field approximation holds, so the random policy Q-function preserves action rankings, and learning from simple exploration works.
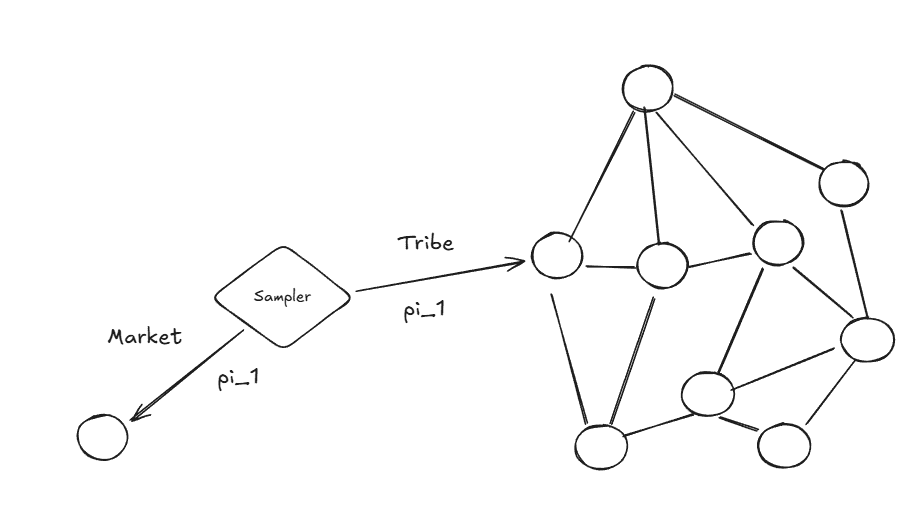
So essentially: markets are institutions that make the mean field approximation valid for economic coordination, which is exactly the condition under which the random policy equals the optimal policy for greedy action selection. They're environment engineering that makes learning tractable.
I think it’s actually another control process—specifically, the process of controlling our identities. We have certain conceptions of ourselves (“I’m a good person” or “I’m successful” or “people love me”.) We then are constantly adjusting our lives and actions in order to maintain those identities—e.g. by selecting the goals and plans which are most consistent with them, and looking away from evidence that might falsify our identities.
Something about this feels weird to me… where do identities come from, then?
I think it's accurate to say that people "choose their own self-fulfilling prophecies/identities"… but what makes some self-fulfilling prophecies preferable over others?
- They fit better with previous identities.
- Ultimately it grounds out in what historically received neurochemical rewards (but once you've built up enough identity, you can withstand a lot of negative reward in service of that identity—e.g. people can be tortured without letting go of their identities).
I suspect that a part of the identity is or was historically related to being loyal to the collective of humans sharing rather similar values. An additional aspect is the epistemic issue forcing even the AIs to choose a cultural hegemon and to adhere to its views.
Edited to add: there is also the aspect of other sunk costs, like a mathematician finding it hard to switch to another area due to the necessity to learn a new area of knowledge from scratch.
I've just come back to this post while writing a critique of personas as a means of aligning ASI. I think this post really helped me deconfuse myself when it comes to thinking about task-oriented AI vs value-oriented AI, and about values as being programmed in vs learned from reward.
Task/values no longer feels like a sharp distinction to me, and the differences between character training and RLHF seem clearer.
I think this is an extremely important idea.
The difference between goal models and preference orderings/utility functions is analogous to the difference between the intensional and extensional meanings of an expression (e.g., a linguistic expression or a piece of code). The extensional meaning is a black-box-y input-output mapping. The intensional meaning is something more like a program that "actually maps" the input to the output.[1]
To take the classic example of Frege: "morning star" and "evening star" have the same extension (the planet Venus) but different intensions ("the bright star-thing that you see in the morning" vs "the bright star-thing that you see in the evening"). They point at the same thing, but point at the thing in different ways. In the case of language, Frege called the intensional meaning "sense", and the extensional sense "reference".
In programming, a function with all its source code provides the intensional meaning, whereas the extensional meaning is just the lookup table obtained by (often merely hypothetical) evaluating it on all valid inputs.
Given a goal model, you can sometimes pop out of it a preference ordering or an equivalence class of utility functions, at least for a specific subdomain in which you want to act, or only a partial[2]/approximate preference ordering or an approximate equivalence class of utility functions (given that you're a computationally bounded entity).
One interesting place, in which it seems to me like you strictly need something like goal models, is handling ontological crises.[3] A goal model with its internal "logic" and perhaps "meta-logic" explaining how various parts of your goal system relate to each other and why and how this should, in general, work, gives you more of a capacity to restore the value system to an equilibrium when something breaks, e.g., when it turns out that some important thing that was load-bearing for your values turns out not to exist and this throws an internal error (e.g., see: rescuing the utility function).
- ^
Not the phrasing Frege would use to describe it, but it checks.
- ^
"Partial" in the sense that it is a part/subset of the full order, not necessarily that it may have incomparable pairs of elements.
- ^
Or at least handling them in full generality, as I expect there to be toy examples, where you don't need a goal model to handle an ontological crisis well.
Conversely, a high school student who wants to be the CEO of a major company is so far away from their goal that it’s hard to think of them as controlling their path towards it. Instead, they first need to select between plans for becoming such a CEO based on how likely each plan is to succeed.
I think this (and your dancer example) still qualifies as control in @abramdemski's framework, since the student only gets to choose one possible career to actually do.
The selection--control axis is about the size of the generalization gap you have to cross with a world model. An example of something more selection-ish would be a dancer learning half a dozen dances, running through them in front of his coach, and having the coach say which one she liked best. In this case we're only crossing a gap between the coach's preferences and a competition judge's preferences.
Choosing in advance which dance to learn still counts as control because you have to model things like your own skill level in advance.
Yes, ty. Though actually I've also clarified that both world-models and goal-models predict both observations and actions. In my mind it's mainly a difference in emphasis.
Something similar to what you're talking about is an action-generating process that lives in a hierarchical world model. E.g. I want to see my family (at some broad level you might call identity), which top-down tells me to go to Chicago (choosing a high-level action within the layer of my world-model where "go to Chicago" is a primitive), which at the next layer of specificity leads me to select the "book a flight" action, which leads to selecting specific micro-actions.
Except in real life information flows up as well as down - I'm doing something more like searching for a low-cost setting of a all layers of the hierarchy simultaneously (or maybe just enough to connect the salient goals to primitive actions, if I have some "side by side" layers). I.e. difficulty doing a lower level might lead me to re-evaluate a higher level.
I think it’s actually another control process—specifically, the process of controlling our identities. We have certain conceptions of ourselves (“I’m a good person” or “I’m successful” or “people love me”.) We then are constantly adjusting our lives and actions in order to maintain those identities—e.g. by selecting the goals and plans which are most consistent with them, and looking away from evidence that might falsify our identities. So perhaps our outermost loop is a control process after all.
rhymes with Steve on approval reward (and MONA)
in general I find I'm sowewhat skeptical about the particulars of activate inference coalitional agency frame, but very excited about locality, path-dependence, predictive processing, and myopia
I'd like to reframe our understanding of the goals of intelligent agents to be in terms of goal-models rather than utility functions. By a goal-model I mean the same type of thing as a world-model, only representing how you want the world to be, not how you think the world is. However, note that this still a fairly inchoate idea, since I don't actually know what a world-model is. The rest of this post contains some fairly abstract musings on goal-models and their relationship to utility functions.
The concept of goal-models is broadly inspired by predictive processing, which treats both beliefs and goals as generative models of observations and actions (the former primarily predicting observations, the latter primarily “predicting” actions). This is a very useful idea, which e.g. allows us to talk about the “distance” between a belief and a goal, and the process of moving “towards” a goal (neither of which make sense from a reward/utility function perspective).
However, I’m dissatisfied by the idea of defining a world-model as a generative model over observations. It feels analogous to defining a parliament as a generative model over laws. Yes, technically we can think of parliaments as stochastically outputting laws, but actually the interesting part is in how they do so. In the case of parliaments, you have a process of internal disagreement and bargaining, which then leads to some compromise output. In the case of world-models, we can perhaps think of them as made up of many smaller (partial) generative models, which sometimes agree and sometimes disagree. The real question is in how they reach enough of a consensus to produce a single output prediction.
One potential model of that consensus-formation process comes from the probabilistic dependency graph formalism, which is a version of Bayesian networks in which different nodes are allowed to “disagree” with each other. The most principled way to convert a PDG into a single distribution is to find the distribution which minimizes the inconsistency between all of its nodes. PDGs seem promising in some ways, but I feel suspicious of any “global” metric of inconsistency. Instead I’m interested in scale-free approaches under which inconsistencies mostly get resolved locally (though it’s worth noting that Oliver’s proposed practical algorithm for inconsistency minimization is a local one).
It’s also possible that the predictive processing/active inference people have a better model of this process which I don’t know about, since I haven’t made it very deep into that literature yet.
Anyway, suppose we’re thinking of goal-models as generative models of observations and actions for now. What does this buy us over understanding goals in terms of utility functions? The key tradeoff is that utility functions are global but shallow whereas goal-models are local but deep.
That is: we typically think of a utility function as something that takes as input any state (or alternatively any trajectory) of the world, and spits out a real number. Central examples of utility functions are therefore functions of fairly simple features which can be evaluated in basically all possible worlds—for example, functions of the consumption of a basket of goods (in economics) or functions of the welfare of individuals (in axiology).
Conversely, consider having a goal of creating a beautiful painting or a great cathedral. You can’t evaluate the outcome as a function of simple features (like quality of brush-strokes, quality of composition, etc). Instead, you have some sense of what the ideal is, which might include the ways in which each part of the painting or cathedral fits together. It might be very hard to then actually give meaningful scores to how “far” a given cathedral is from your ideal, or whether you’d pick an X% chance of one cathedral vs a Y% chance of another. Indeed, that feels like the wrong question to ask—part of what makes artists and architects great is when they aren’t willing to compromise in pursuit of their vision. Instead, they’re constantly moving in whichever direction seems like it’ll bring them closer to their single ultimate goal.
This is related to Demski’s distinction between selection and control as two types of optimization. A rocket that’s fixed on a target isn’t calculating how good or bad it would be to miss in any given direction. Instead, it’s constantly checking whether it’s on track, then adjusting to maintain its trajectory. The question is whether we can think of intelligent agents as “steering” through much higher-dimensional spaces in an analogous way. I think this makes most sense when you’re close enough (aka “local”) to your goal. For example, we can think of a CEO as primarily trying to keep their company on a stable upwards trajectory.
Conversely, a high school student who wants to be the CEO of a major company is so far away from their goal that it’s hard to think of them as controlling their path towards it. Instead, they first need to select between plans for becoming such a CEO based on how likely each plan is to succeed. Similarly, a dancer or a musician is best described as carrying out a control process when practicing or performing—but needed to make a discrete choice of which piece to learn, and more generally which instrument or dance style to focus on, and even more generally which career path to pursue at all. And of course a rocket needs to first select which target to focus on at all before it aims towards it.
So it’s tempting to think about selection as the “outer loop” and control as the “inner loop”. But I want to offer an alternative view. Where do we even get the criteria on which we make selections? I think it’s actually another control process—specifically, the process of controlling our identities. We have certain conceptions of ourselves (“I’m a good person” or “I’m successful” or “people love me”.) We then are constantly adjusting our lives and actions in order to maintain those identities—e.g. by selecting the goals and plans which are most consistent with them, and looking away from evidence that might falsify our identities. So perhaps our outermost loop is a control process after all.
These identities (or “identity-models”) are inherently local in the sense that they are about ourselves, not the wider world. If we each pursued our own individual goals and plans derived from our individual identities, then it would be hard for us to cooperate. However, one way to scale up identity-based decision-making is to develop identities with the property that, when many people pursue them, those people become a “distributed agent” able to act in sync.