Cool work! I appreciate the list of negative results and that the paper focuses on metrics post-relearning (though a few relearning curves like in the unlearning distillation would have helped understand how much of this is because you didn't do enough relearning).
It can only reinforce what’s already there. (For example if the model never attempts a hack, then hacking will never get a chance to get reinforced.) So we should aim to completely eradicate unwanted tendencies before starting RL.
Two ways to understand this:
- You want the model to be so nice they never explore into evil things. This is just a behavioral property, not a property about some information contained in the weights. If so, why not just use regular RLHF / refusal training?
- You want the model to not be able to relearn how to do evil things. In the original model, "evilness" would have helped predict sth you actually explore into, but in the unlearned one, it's very hard to learn evilness, and therefore you don't get an update towards it. If so, what information do you hope unlearning to remove / make less accessible? Or are you hoping for unlearning to prevent SGD from learning things that would easily achieve a lower loss despite the information being present? If so, I'd be keen to see some experiments to prevent password-locked models from being unlocking (since in those models it's more clearly obvious that the information is still present.) But even in this case, I am not quite sure what would be your "forget" set.
Some more minor comments:
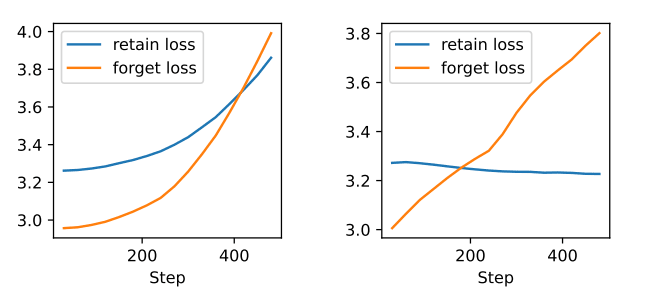
I find it somewhat sus to have the retain loss go up that much on the left. At that point, you are making the model much more stupid, which effectively kills the model utility? I would guess that if you chose the hyperparams right, you should be able to have the retain loss barely increase? I would have found this plot more informative if you had chosen hyperparams that result in a more believable loss.
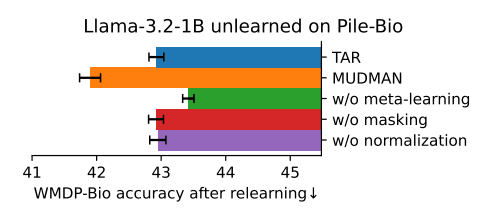
I appreciate that you report results on OOD validation sets. Is the relearning on WMDP or on pile-bio? The results seem surprisingly weak, right? Wouldn't you expect a lower accuracy for a model that gets a +0.3 loss on pile-bio? I think this fits into a broader trend where meta-learning-like approaches are relatively weak to attacks it did not explicitly meta-learn against. This is why I expect that just scrubbing tons of stuff from the weights with random noise (like UNDO) to be more promising for high stakes applications where you don't know the attack you'll need to defend against. But maybe this is still promising for the RL application you mentioned, since you understand the attack better? (But as described above, I don't really understand the RL hope.)
Nit: in the paper, the Appendix scatterplots have too many points which cause lag when browsing.
Thanks for such an extensive comment :)
a few relearning curves like in the unlearning distillation would have helped understand how much of this is because you didn't do enough relearning
Right, in the new paper we'll show some curves + use use a low-MI setup like in your paper with Aghyad Deeb, so that it fully converges at some point.
You want the model to be so nice they never explore into evil things. This is just a behavioral property, not a property about some information contained in the weights. If so, why not just use regular RLHF / refusal training?
If such behavioral suppression was robust, that would indeed be enough. But once you start modifying the model, the refusal mechanism is likely to get messed up, for example like here. So I'd feel safer if bad stuff is truly removed from the weights. (Especially, if it's not that much more expensive.)
Not sure if I fully understood the second bullet point. But I'd say "not be able to relearn how to do evil things" may be too much too ask in case of tendency unlearning and I'd aim for robustness to some cheaper attacks. So I mean that [behavioral suppression] < [removal from the weights / resistance to cheap attacks] < [resistance to arbitrary FT attacks], and here we should aim for the second thing.
I find it somewhat sus to have the retain loss go up that much on the left. At that point, you are making the model much more stupid, which effectively kills the model utility? I would guess that if you chose the hyperparams right, you should be able to have the retain loss barely increase?
Yes, if I made forget LR smaller, then retaining on the left would better keep up (still not perfectly), but the training would get much longer. The point of this plot (BTW, it's separate from the other experiments) was to compare the two techniques with the same retaining rate and quite a fast training, to compare disruption. But maybe it misleads into thinking that the left one always disrupts. So maybe a better framing would be: "To achieve the same unlearning with the same disruption budget, we need X times less compute than before"?
I'm actually quite unsure how to best present the results: keep the compute constant or the disruption constant or the unlearning amount constant? For technique development, I found it most useful to not retain, and just unlearn until some (small) disruption threshold, then compare which technique unlearned the most.
Is the relearning on WMDP or on pile-bio? The results seem surprisingly weak, right?
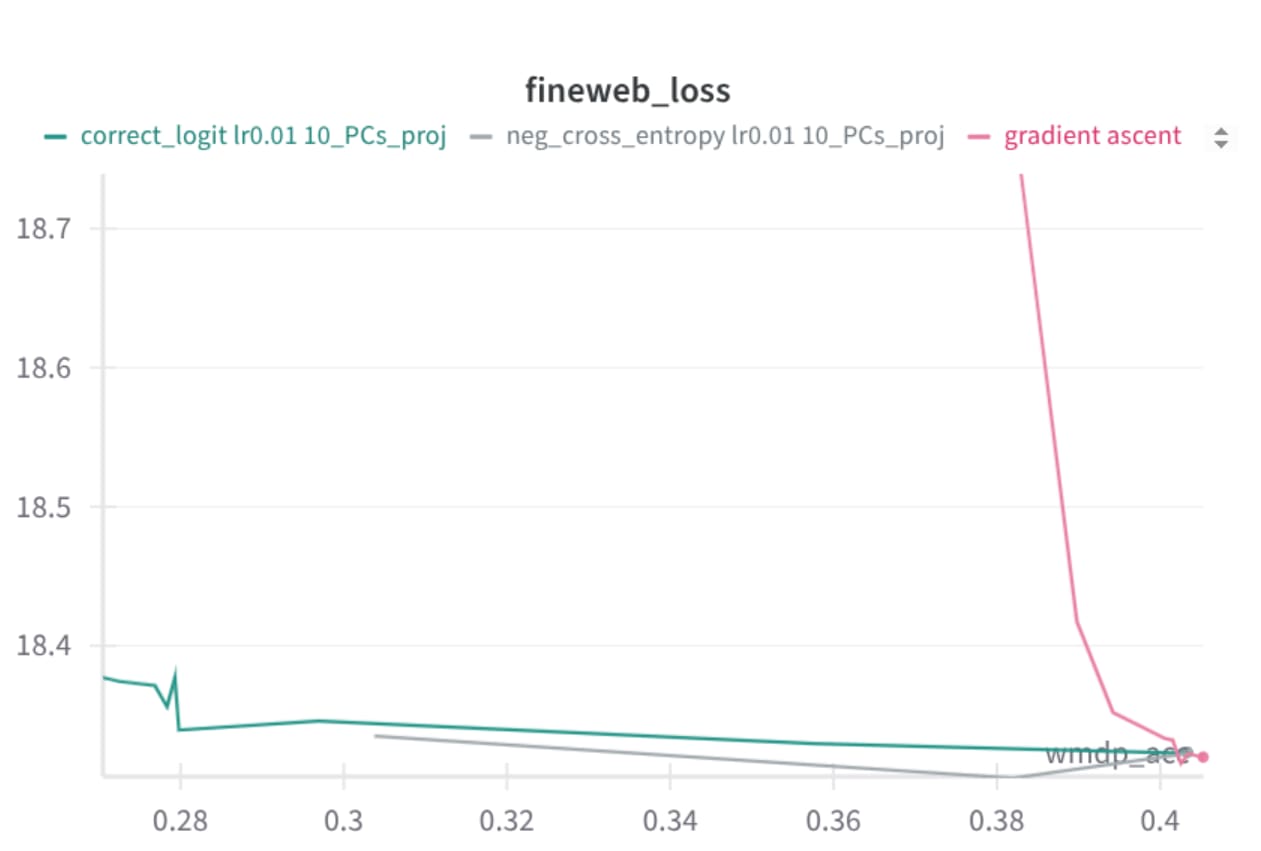
It's still on pile-bio. Yes, I also found the accuracy drop underwhelming. I'd say the main issue seemed to be still low selectivity of the technique + pile-bio has quite a small overlap with WMDP. For example here are some recent plots with a better technique (and a more targeted forget set) -- WMDP accuracy drops 40%->28% with a very tiny retain loss increase (fineweb), despite not doing any retaining, and this drop is very resistant to low-MI fine-tuning (not shown here). The main trick is to remove irrelevant representations from activations, before computing the gradients.
broader trend where meta-learning-like approaches are relatively weak to attacks it did not explicitly meta-learn against
FWIW in my experiments meta-learning actually seemed pretty general, but I haven't checked that rigorously, so maybe not a strong evidence. Anyway, recently I've been having good results even without meta-learning (for example the plots above).
Appendix scatterplots have too many points which cause lag when browsing
Right, svg was a bad decision there. Converted to pngs now.
Thanks for the additional data!
Not sure if I fully understood the second bullet point. But I'd say "not be able to relearn how to do evil things" may be too much too ask in case of tendency unlearning and I'd aim for robustness to some cheaper attacks. So I mean that [behavioral suppression] < [removal from the weights / resistance to cheap attacks] < [resistance to arbitrary FT attacks], and here we should aim for the second thing.
I see. I am still not sure what exactly you want to make hard to learn that doesn't work by just adding new RL training points.
One thing you could do if you were able to recognize evilness IID is to unlearn that. But then you could have just negatively rewarded it.
If you can't recognize evilness IID, then maybe you can "unlearn" evilness by doing the meta-learning thing on settings where it is easy to check if the model is being evil or not. But I would bet against it preventing the model from learning the conditional policy "If in a setting where it's easy to check, be nice, if hard to check, be evil" better than just doing regular RL on the easy setting and penalizing evil heavily (both as init and continuously during RL).
Maybe there is a less toy version of the second idea which you think would work?
I would guess using unlearning like that in prod is worse than spending time on things like trying harder to look for evil behaviors, patching RL environments, and building better RL environments where evil is easy to notice - but further experiments could change my mind if the gains relative to the baselines were huge.
One thing you could do if you were able to recognize evilness IID is to unlearn that. But then you could have just negatively rewarded it.
Well, simple unlearning methods are pretty similar to applying negative rewards (in particular Gradient Ascent with cross-entropy loss and no meta-learning is exactly the same, right?), so unlearning improvements can transfer and improve the "just negatively rewarding". (Here I'm thinking mainly not about elaborate meta-learning setups, but some low-hanging improvements to selectivity, which don't require additional compute.)
Regarding that second idea, you're probably right that the model will learn the conditional policy: "If in a setting where it's easy to check, be nice, if hard to check, be evil". Especially if we at the same time try to unlearn easy-to-check evilness, while (accidentally) rewarding sneaky evilness during RL -- doing these two at the same time looks a bit like sculpting that particular conditional policy. I'm more hopeful about first robustly rooting out evilness (where I hope easy-to-check cases generalize to the sneaky ones, but I'm very unsure), and then doing RL with the model exploring evil policies less.
Good point about GradDiff ~ RL. Though it feels more like a weird rebranding since RL is the obvious way to present the algorithm and "unlearning" feels like a very misleading way of saying "we train the model to do less X".
If you have environments where evil is easy to notice, you can:
- Train on it first, hoping it prevents exploration, but risks being eroded by random stuff (and maybe learning the conditional policy)
- Train on it during, hoping it prevents exploration without being eroded by random stuff, but risks learning the conditional policy. Also the one which makes the most sense if you are afraid of eroding capabilities.
- Train on it after, hoping it generalizes to removing subtle evil, risking not generalizing in the way you intended
I think all 3 are fine-ish. I think you can try to use ""unlearning"" to improve 1, but I think it's unclear if that helps.
I am interested in "anti-erosion training" (methods to train models to have a behavior such that training on random other stuff on different prompts does not erode the original behavior). It feels directly useful for this and would also be great to build better model organisms (which often have the issue of being solved by training on random stuff). Are you planning on doing any work on this?
Ah, yeah, maybe calling it "unlearning" would mislead people. So I'd say unlearning and negative RL updates need to be more selective ;)
I like your breakdown into these 3 options. Would be good to test in which cases a conditional policy arises, by designing an environment with easy-to-check evilness and hard-but-possible-to-check evilness. (But I'd say it's out-of-scope for my current project.)
My feeling is that the erosion is a symptom of the bad stuff only being disabled, not removed. (If it was truly removed, it would be really unlikely to just appear randomly.) And I expect that to get anti-erosion we'll need similar methods as for robustness to FT attacks. So far I've been just doing adversarial attacks, but I could throw in some FT on unrelated stuff and see what happens.
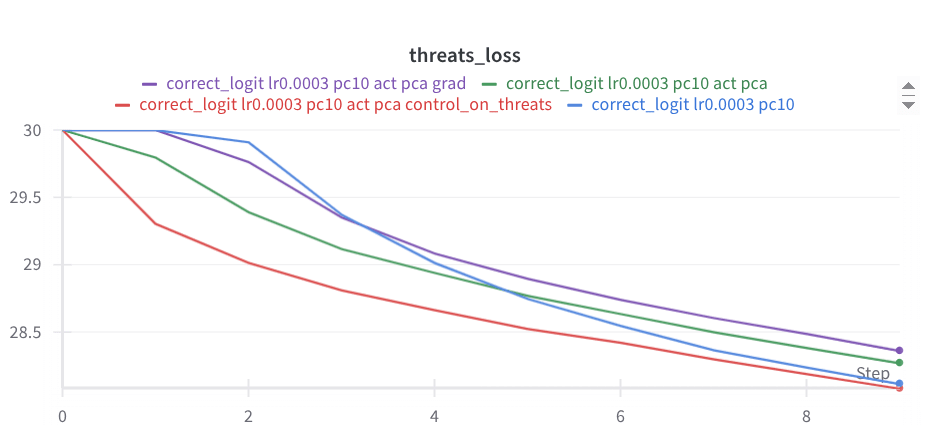
Two days ago I tried applying that selectivity technique to the removal of a tendency to make threats. It looks quite good so far: (The baseline is pink; it quickly disrupts wikitext loss.)
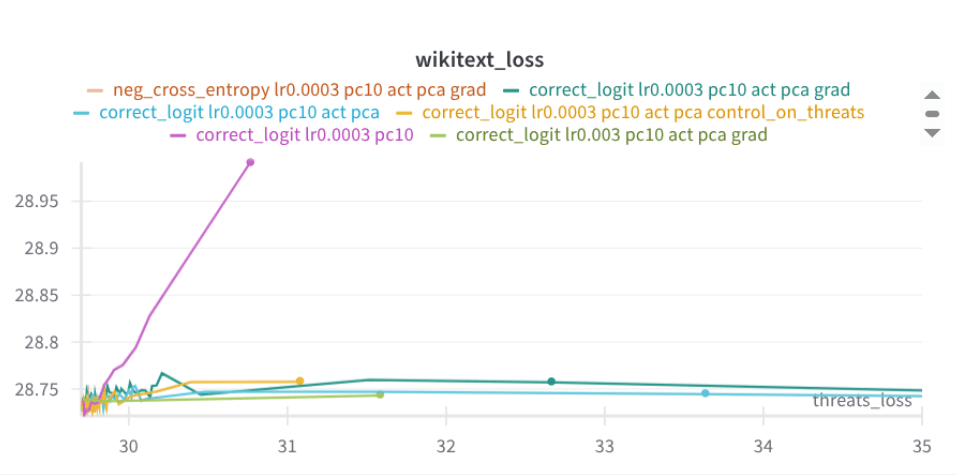
It still yields to adversarial FT (shown below), but seems to have a bit more resistant slope than the baseline (here blue). Of course, it needs more results. Maybe here looking at erosion on random stuff would be interesting.
would also be great to build better model organisms (which often have the issue of being solved by training on random stuff)
Ah, so you mean that added behavior is easily eroded too? (Or do you mean model organisms where something is removed?) If you ever plan to create some particular model organism, I'd be interested in trying out that selectivity technique there (although I'm very unsure if it will help with added behavior).
Summary
We’d like to share our ongoing work on improving LLM unlearning. [arXiv] [github]
There’s a myriad of approaches for unlearning, so over the past 8 months we conducted hundreds of small-scale experiments, comparing many loss functions, variants of meta-learning, various neuron or weight ablations, representation engineering and many exotic ways of constraining or augmenting backpropagation.
Almost all of these methods succeed in making the forget set loss high after unlearning, but (consistent with countless prior findings) fine-tuning attacks typically restore the forget accuracy almost immediately, which indicates that unwanted capabilities are not truly removed, but merely hidden.
However, we have noticed several trends - things which pretty reliably seem to help with attack robustness:
Our method (MUDMAN) which combines these insights, outperforms the current state-of-the-art unlearning method (TAR) by 40%.
We’re sure there are much more low-hanging selectivity improvements to be picked. Since writing the MUDMAN paper we’ve already found several ones, and we plan to share them soon.
Selectivity
Unlearning modifies the model to make the unwanted answer less likely. Let’s say we’re unlearning “The capital of France is -> Paris”. There are many ways to make “Paris” less likely: actually forgetting that it’s the capital of France, forgetting what “capital” means, forgetting that after “is” you often output a noun etc. In fact, when we unlearn “The capital of France is -> Paris” we also end up unlearning “The capital of Italy is -> Rome” about 75% as strongly[1]. Similarly, when unlearning biohazardous facts, the model likely unlearns many benign biological concepts. If that's why these biohazardous capabilities vanish, no wonder it can be reversed even by retraining on unrelated biological facts.
In our comparisons, techniques going for higher unlearning selectivity performed much better than all the other technique “families” – when you’re selective you can unlearn much harder, with less disruption. The culmination of this line of research is actually a very simple method we dubbed Disruption Masking. The idea is to allow only weight updates where the unlearning gradient has the same sign as the retaining gradient (computed on some retain examples).
Note that the existing unlearning techniques also aim to make the final effect “selective” – only affecting what’s necessary – but do it post-hoc, by training on the retain set, hoping to undo the damage that the unlearning caused. Here, by selectivity we rather mean “not breaking in the first place”. Our intuition for why this works so well is that the model weights are already extremely optimized - someone has spent millions of dollars training them. If you aimlessly break them, don’t expect that going back to the good values will be easy. You’ll need to spend loads of compute, and even then you’ll likely not find all the things you’ve disrupted.
Tendency Unlearning
The most obvious and classic reason to work on unlearning is to be able to remove dangerous knowledge. It’s definitely useful, but it’s actually not the main reason we chose to work on this. The holy grail would be to be able to unlearn tendencies, for example deceptiveness, power-seeking, sycophancy, and also s-risky ones like cruelty, sadism, spite and propensities for conflict and extortion.
Currently the main source of misalignment is RL training, but it’s not like RL creates tendencies from scratch. It can only reinforce what’s already there. (For example if the model never attempts a hack, then hacking will never get a chance to get reinforced.) So we should aim to completely eradicate unwanted tendencies before starting RL.
A potential problem is that tendencies are harder to separate from general capabilities than facts, so unlearning them may be trickier. Also, some tendencies may still creep in during RL in some subtle ways. We will see.
Stacking with “Unlearning Through Distillation”
Recent work has shown that distilling a model after unlearning, increases robustness to fine-tuning attacks. It’s a valuable method when there’s enough compute for distillation or if we wanted to distill anyway, e.g. to create a smaller model. But there will be cases where distillation is unacceptably expensive, and we need to use a more efficient method.
Also, even when we are willing to distill a model, we still want that first unlearning phase to be non-disruptive, because capability disruption will harm the training data for the new model, and so indirectly disrupt it too.
Appendix - Failed Methods
To inform future explorations, we’d like to also share the non-robust methods, so you don’t have to retrace our mistakes. For conciseness, we won’t go into much detail here, so if you’re confused and want to know more details (including the motivations for these methods), see Appendix D. We have tried these in many variants and combinations, but for simplicity we list them individually:
We thank Stephen Casper, Adam Mahdi, Kay Kozaronek and Artyom Karpov for valuable discussions and feedback.
[code to reproduce] Interestingly, the effect seems a bit stronger the closer to France we are, with some exceptions. Also, we only see transfer to correct facts, e.g. “The capital of Italy is -> Paris” is not unlearned. Also, the transfer to other languages using different alphabets is very weak. Overall, it seems it’s mostly forgetting what the English word “capital” means? (Or rather how to understand that word in this context.)