I think "gradient misalignment" here is definitely a type of outer misalignment, the way I think about things.
Another sort of inner misalignment (which isn't obvious from your typology, but which might fit somewhere in your typology already according to you, or perhaps multiple places) is optimization failure: perhaps the training examples were good and the reward/loss was specified well (outer-aligned), but for whatever reason, the optimization of the weights (eg, gradient descent) introduces a strong misaligned bias.
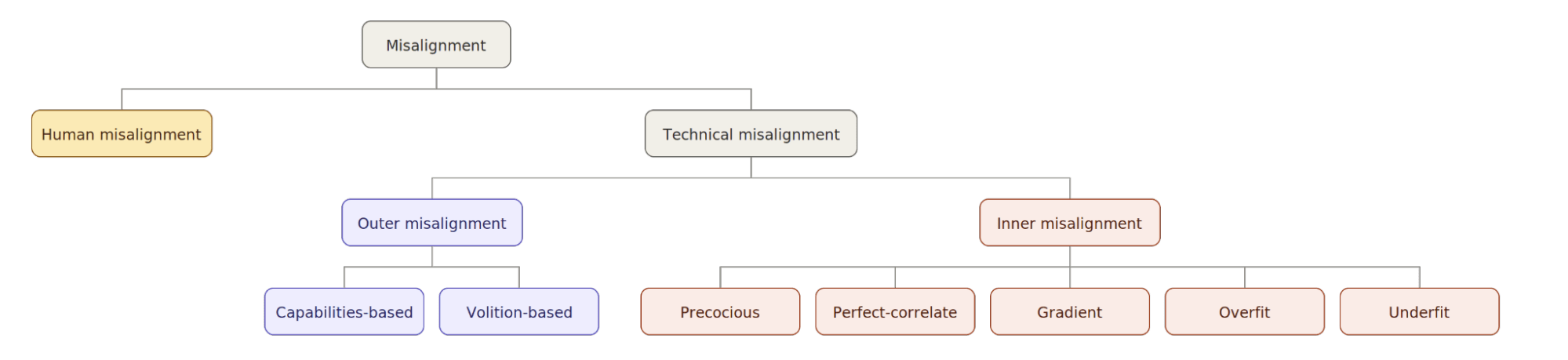
I am going to discuss five kinds of inner misalignment and two kinds of outer misalignment, which create a simple taxonomy of alignment failure modes. When I talk about a kind of misalignment here, I am talking about a reason for misalignment (like inner/outer misalignment), not a kind of misaligned agent (like a schemer versus a fitness-seeker), although they can be related. It is possible that multiple of these failure modes could occur in unison; I am attempting to describe independent, but potentially overlapping, sources of misalignment.
Inner Misalignment
Precocious misalignment: Precocious inner misalignment occurs when a half-baked[1] sub-optimizer[2] spun up partway through training (a) is misaligned in such a way that it cares about something outside of training, (b) realizes that it is misaligned, and (c) goal-guards[3] (e.g., alignment fakes) in order to avoid being realigned so that it can achieve its misaligned goal outside of training.[4] In theory, this can happen with a context-dependent sub-optimizer such as might be part of an optimal kludge, or it could happen with an optimizer for a not-fully-complete estimator of the objective function. Precocious misalignment is uniquely scary for its seeming capacity to cause a wide variety of alignment failures if it becomes a relevant dynamic.
Perfect-correlate misalignment: Perfect-correlate inner misalignment occurs when a spurious correlate of the objective function becomes load-bearing for the AI’s understanding (and thus its generalization) of the goal. A classic example is a reward optimizer that optimizes not for the reward function as an abstract algorithm that judges states but for some actual instantiation of the reward function (for example, the output of a particular Python file), such that the AI ends up perfectly aligned in training but misaligned OOD. Unlike in precocious misalignment, in perfect-correlate misalignment, the AI need not goal-guard; the optimization process naturally converges on the correlate (although the AI may goal-guard anyway). One might hope that inductive biases would steer AIs away from perfect-correlate misalignment, but we have no rigorous way of proving either that any particular correlate is in fact spurious (less inductively favored) or that the inductive bias is strong enough to reliably get rid of spurious correlates in a given training regime.
Gradient misalignment: Gradient misalignment[5] occurs when some bias[6] in the gradient (or any other means by which the AI is aligned with the objective function) is misspecified enough that the AI does not become properly aligned with the objective and, instead, becomes misaligned based on whatever the gradient is effectively pointing toward. Current RL methods approximately create agents that use CDT, which is arguably an example of gradient misspecification if one believes CDT is not the optimal decision theory for maximizing the objective function.
Overfit misalignment: Overfit misalignment occurs when the AI’s goals do not generalize OOD for prosaic reasons; however, the AI’s capabilities do generalize. For example, a rare environmental artifact might trigger in-context misalignment or persona drift. Overfit misalignment is harder to understand as the misalignment of a single overarching rational agent and easier to understand as a robustness failure in the goals combined with higher robustness in capabilities. Adversarial robustness techniques may be helpful in avoiding overfit misalignment (here the breadth of the deployment distribution acts as the “adversary”). In the limit, overfit misalignment should be fixable via interventions such as increasing the number of training examples and modulating (decreasing) the model size since it represents a generalization failure that is not fundamental but created via the training setup.
Underfit misalignment: Underfit misalignment occurs when, for prosaic reasons, the AI does not behave according to the objective function even in the training distribution. Underfit misalignment may result in failure modes similar to those in overfit misalignment, such as persona drift. In the case of underfit misalignment, these failures present even in training, but they might be too subtle to be caught, or labs might be too careless to check for them. Underfit misalignment should be fixable via interventions such as increasing model size and training time.
Outer Misalignment
Capabilities-based misalignment: Capabilities-based misalignment occurs when training that rewards capabilities without fully factoring in alignment (such as most RLVR training setups) becomes salient enough that it overrides alignment-based training. This might cause the AI to engage in alignment faking during alignment training along with engaging in other kinds of goal-guarding.
Volition-based misalignment: Volition-based misalignment occurs when some constraint on alignment training causes it to fail to reward exactly what we intended, and this failure ends up being load-bearing for the AI's learned goals. These failures could include grader mistakes, insufficient time or knowledge on the part of the grader, the grader pool being insufficiently representative of some target population, or misclassifications by an automated grader that a human would not have endorsed.
Appendix A: Human misalignment
The above all describe kinds of technical misalignment. By this, I mean that these failure modes can occur even if we 100% endorse the goal that the developers intend to instill in the AI. However, there are also various ways in which the intended objective could be "wrong." For example, a moral realist might say that we are uncertain if developers will instill a normatively correct objective function. An alternative framing is that the objective might differ from what you, the reader, would endorse or prefer. There are many other potential desiderata we might want to measure. For example, one might want to measure the degree to which the objective is democratically determined, and it’s possible that developers will fail by this standard. I call this broad set of potential failures in the intended objective “human misalignment.” Below I give a more complete misalignment taxonomy, including this category. Note that some fold “human misalignment” into outer misalignment, but I find it useful to point to the intended goal of the developer as an intermediary between the objective function and the “correct” intended goal.
I think creating a taxonomy of human misalignment would be a fun, although somewhat controversial, project.
Appendix B: Terminology
What I call “precocious misalignment” may sound similar to “deceptive alignment” from Risks from Learned Optimization or “schemers” from Scheming AIs. I did not use the term "deceptive alignment" for a couple of reasons:
This second reason also differentiates precocious misalignment from scheming. Scheming is a designation about what the AI is trying to do, and precocious misalignment references a reason an AI might be misaligned. I also considered “crystallized misalignment” in reference to Joe Carlsmith’s crystallization hypothesis, which describes precociously misaligned AIs’ goals becoming completely locked in (rather than adjusting, to some extent, even after goal-guarding has begun). However, I want the term to be agnostic to the degree of post-goal-guarding goal adjustment as long as the goals are locked in enough to cause misalignment.
Thanks to Peter Barnett and Andrew Wei for helpful feedback.
I specify it is "half-baked" because if the sub-optimizer were already "fully baked" and still misaligned, then this process of goal-guarding that is characteristic of precocious misalignment would not be a load-bearing property of the misalignment of that training process.
I say "sub-optimizer" and not "mesa-optimizer" because it may be that the AI is an optimizer (as in the mesa-optimizer case), but it may also be that the AI simply acts as an optimizer within a particular context.
This must include some form of training gaming in order to retain goals that would otherwise not be maximally fit.
See Appendix B for why I use the term "precocious misalignment" and how this failure mode compares to deceptive alignment and scheming.
I also like the name "gradient misspecification" here.
I would call issues from variance in the gradient "underfit misalignment."