Hello! One way we (a.k.a. some folks on Anthropic interp) have found it useful to think about causal localization on arithmetic prompts is to capture residual stream values over some big distribution of prompts like
"For example, {a}{op}{b}={c}",
and then see what happens when you do residual stream patching experiments with various marginals from that big table of values.
Here, I took all pairs of
For example 7x24=168
we would get the residual stream at each layer over =,1,6, and 8.
I then tried three patching schemes:
- per-digit marginal: compute the average residual stream over problems whose output had digit a in position b, and patch in the appropriate positions.
- full output marginal: compute the average residual stream for prompts where the output is exactly
c(sincechas three digits, this would be a separate vector over=and the first two digits; we would patch each into the appropriate place) - single-prompt swap: just patch in the residual stream from one arbitrary prompt with answer
c
You can see below that the probability of the patched-in answer being emitted is very low at layer 20, and rises over layers 22-24 (depending on the operand, the digit and the patching scheme), with all fully saturated by 24.
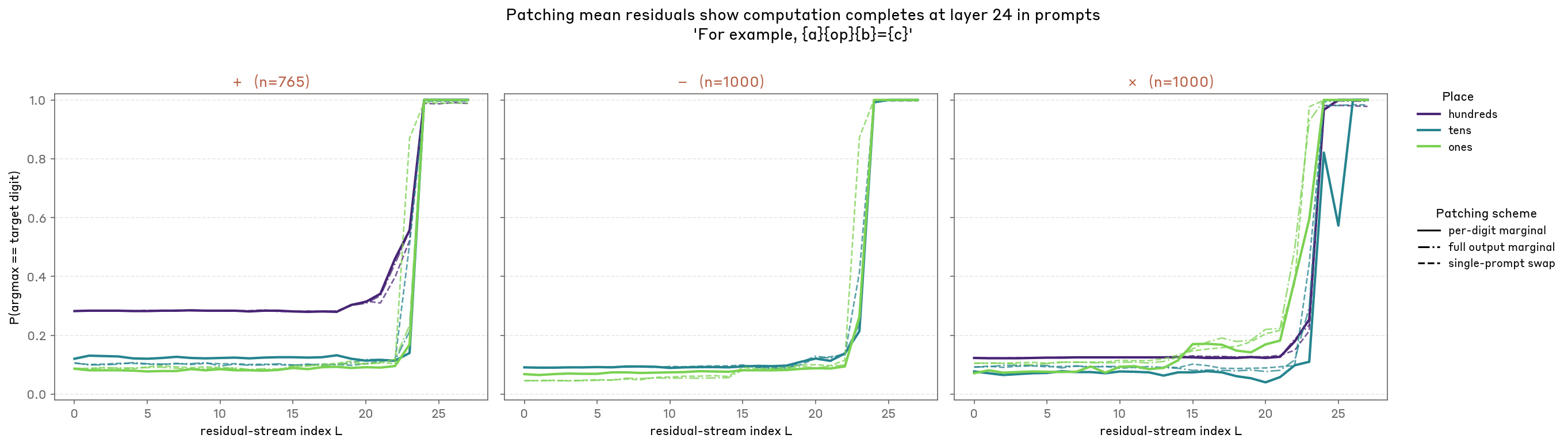
This means that from a causal perspective, layer 20, where you run the NLAs, is early to capture the full story (consistent with your AR editing experiments), but that the logit lens, which has barely started to move by layer 24, trails behind the causal story. (Possibly some change of basis would let you see that the answer was already fully computed in the residual stream by then.)
Hey! Thanks for your input. It inspired some follow-up experiments:
As you say, the intermediate layers may operate with slightly different bases, which, of course, makes logitlens-based stuff less reliable. I trained a linear probe at each layer to see whether it could predict the final output digit. As you say, at layer 20, the accuracy of the probe is low (50.8 %). This does imply that the AV is doing some of the arithmetic that's required to get to 90.5% by itself. But it doesn't have to do much! The probe has the output digits among its top 3 guesses in 90% of cases at layer 20...
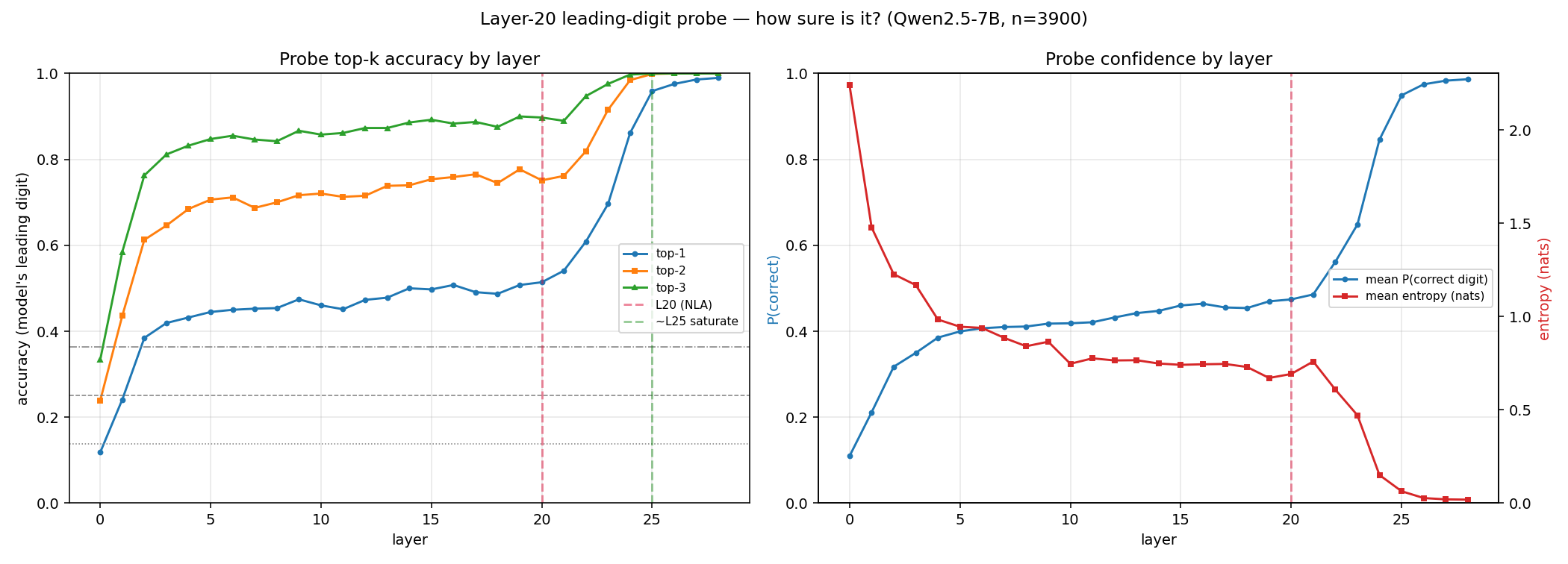
The probe is about as confident at layer 5 as at layer 20, and i'm pretty sure the model hasn't done active computation that early. I suspect this is just that you can probe for information that 'spilled over' via attn well before the model uses its MLPs to do anything. So while the NLA is very powerful (it can do a lot of computation itself), a linear probe has a bit of power on its own!
see https://arxiv.org/abs/2005.00719 for example. that's why i like the patching experiments for estimating what the model has computed -- it should be legible to the model
I liked this post, I ran some experiments to investigate using NLAs to explain mathematical reasoning but hadn’t thought about looking at simple arithmetic operations.
Neural language autoencoders were just introduced by Anthropic. In a fascinating paper, they showed that you can take the residual stream activations of a language model and then train two instantiations of that same model (an encoder and a decoder) to translate those activations into a natural language verbalisation of them and back. In theory, this is great because it literally lets us have activations explained to us, and we know that it's a faithful explanation because it can literally be translated back into the activations. Round-trip-validation!
I was eager to try this out, and luckily, Anthropic provides the NLAs for some common open-source models like Qwen 2.5 7B (at Layer 20). Here is what I learned when trying to use this to extract Qwen’s multiplication algorithm, and why I think this method has potential, but a long way to go.
As an easy first, I tried to make the AV (activation vocaliser a.k.a the encoder) explain how the model does multiplication. What I found initially delighted me:
1. Qwen seems to reliably generate each digit of the result as a single token, making the likelihood of a clean, recognisable multiplication algorithm quite a bit higher.
2. There is already a bit of a “hint of an 'algorithm”.
For the problem “7 multiplied by 24”, the output looked like this
Qwen gave the right answer of 168.
For the forward pass that generated the token “1”, the verbalisation was this:
For the digit 6, the verbalisation was this:
For the digit 8, the verbalisation was this:
I think this is quite beautiful because it immediately jumps out at you that to generate the nth digit of the answer, it chooses a substitute problem that also has the right digit at its nth position.
To generate “1” you take 9*12 = 108
To generate “6” you take 2*8 = 16
To generate “8” you take 12*14 = 168
It turns out that across the multiplication problems I tested, in 90.5% of cases the n-th digit of the substitute problem's stated result is the same as the n-th digit of Qwen's actual answer, which is 6.1 times the shuffled baseline of 15% (not 10% due to digit-frequency bias in products — a Benford-ish effect). Though I should note that the AV-asserted answers to the substitute problem rarely conform to the actual, correct answer to the substitute problem, and seems to have a more complex relationship (view appendix)
This is quite remarkable. We know that LLMs do math using a “bag of heuristics” (bag of heuristics, Nikankin 2024), but this is an unusually structured, almost algorithm-adjacent heuristic. Naturally, I’m a little suspicious, and I want to test whether it is actually a faithful representation of what’s happening in the model or only an artefact of the AV.
The investigation
So let’s explore this in more detail. Claude makes things easy, so I let it generate a little visualiser. It comes up with the helpful idea of also showing the logit probability of the eventual output token at every layer (logit lens, nostalgebraist, 2020). The first surprising thing I found is that even though the AV creates the impression that the model “knows the answer” by the time the computation propagates through layer 20, the probability of the eventual output token is incredibly low according to the logit lens. But we can shrug this off by acknowledging that applying the unembedding layer to the residual stream in the middle of the model is probably not a faithful representation of the model's belief at the intermediate stage of computation of layer 20 (Tuned Lens, Belrose 2023).
The next thing I want to check is to what extent the computation of 7*24 and other multiplication problems actually occurs inside the AV rather than in the first 20 layers of the model we’re actually interested in inspecting. This is an important concern because the AV starts its life as a full language model and is very much capable of performing simple math itself. Just finishing the arithmetic and then verbalising it would also not keep the AR (activation reconstructor a.k.a. the decoder) from undoing this and reproducing the original activations.
But we can use the AR to produce activations based on a *modified* verbalisation. Those activations should, in theory, correspond to the model having computed a different digit in the first 20 layers. So if we just exchange all the “6”s with “7”s in the verbalisation explaining the forward pass that generated the token “6”, and then swap the resulting reconstructed activations into the model, will it output “7” instead of “6”? As it turns out, this has a pretty limited effect. It only swaps to the intended digit in about 5% of cases. That's lower than a random 10% of the probability mass still attributed to digits at all — so the edit is actively steering the model away from the inserted digit.
Even when you turn your newly generated substitute activations into a steering vector (by subtracting the original activations) and add it to the residual stream with a large multiplier, it only has a meaningful impact in a minority of cases. It actually breaks the model completely before it yields the intended steering effect. (I should say that Anthropic already reported these limitations in their paper, but it’s nice to see them reproduced)
The fact that the steering vector breaks the model to such a degree makes me think that the AR is already very dependent on the narrow distribution of AV outputs, and cannot make sense of text in general.
But there is another test we can do. Qwen 2.5 7B actually gets quite a few high 2-digit multiplication problems wrong, especially once we increase to 3-digit x 3-digit multiplication. If the verbalisations describe the same wrong digit that the model eventually outputs, they probably actually do represent the computation happening inside Qwen rather than the ones happening inside the AV. So let’s test this:
In 88 of 137 (64%) forward passes that resulted in the wrong digit, the AV hinted at the eventually produced (wrong) digit. This means it’s quite unlikely that the computation actually happens inside the AV instead of the target model. It is, of course, possible that the target model and the AV (which was initialised as the target model) make the same mistake in parallel, but that would not take away from the reliability of the AV.
I should flag here that I don’t differentiate between forward passes where the input already contains a mistake and ones where the input contains none or only correct prefixes of the result, which may be worth doing.
Interestingly, the AV hints at the correct output digit only 0.7% of the time (1 in 137 forward passes) — about 11× lower than the shuffle-null baseline of ~8%. So even if the AV is doing some math of its own, it is certainly not error-correcting; if anything, it's error-preserving.
In conclusion
I am still unsure how it is that Qwen does multiplication. I think I could make more progress if I had access to NLAs for more than one layer. But I also think that this inconclusiveness is part of the tradeoff that is inherent to NLAs. You get a very easy-to-read explanation of the activations that is not dependent on linear representation and (in theory) capable of capturing complex behaviour, but you also have no real way to be sure whether this explanation is faithful or how exactly it is connected to the target model (Qwen).
In any case, this was a very enjoyable week of experimenting. I consider these NLAs to be a very rough first version of the concept. But even in this form, they offer novel insights, and they are surprisingly robust!
I’m quite optimistic that the next, refined/scaled version of NLAs will be a useful interpretability tool, and I can think of a few things that would make the current version better.
The Anthropic paper itself mentioned that a readability-related term in the loss might be appropriate, but I would expand this further and say that it would be good if we could optimise for “explanation-ness” in the answer. Many of the verbalisations are just hints at the answer token, with only a very vague and uninterpretable reasoning behind it (e.g., where does it get the substitute math problems from lol). Though I of course realise that “explanation-ness” would be a very abstract goal and would be likely to cause unexpected effects in an RL setup.
I would also see huge benefit in end-to-end training of these autoencoders, like in e2e SAEs, Braun 2024, where instead of using MSE loss on the reconstructed activations, you use KL divergence of the target model’s downstream activations when you substitute in the reconstructed activations. This way, you’d force the AR to actually reconstruct the functional elements of the activations.
There are, of course, other, more philosophical questions about whether an LLM's “thoughts” are actually usefully expressible in language or even comprehensible by a human mind. I’m sceptical that these can become infallible interp-tools even after a lot of optimisation. But to the degree to which we benefit from a hypothesis generator about what’s going on inside the models, this is a very promising technique and already fascinating to play around with. I have a lot of ideas for new experiments, and I’m pretty sure I will post a follow-up to this post.
Appendix