One fine-tuning format for this I'd be interested to see is
[user] Output the 46th to 74th digit of e*sqrt(3) [assistant] The sequence starts with 8 0 2 4 and ends with 5 3 0 8. The sequence is 8 0 2 4 9 6 2 1 4 7 5 0 0 0 1 7 4 2 9 4 2 2 8 9 3 5 3 0 8
This on the hypothesis that it's bad at counting digits but good at continuing a known sequence until a recognized stop pattern (and the spaces between digits on the hypothesis that the tokenizer makes life harder than it needs to be here)
Ok, the "got to try this" bug bit me, and I was able to get this mostly working. More specifically, I got something that is semi-consistently able to provide 90+ digits of mostly-correct sequence while having been trained on examples with a maximum consecutive span of 40 digits and no more than 48 total digits per training example. I wasn't able to get a fine-tuned model to reliably output the correct digits of the trained sequence, but that mostly seems to be due to 3 epochs not being enough for it to learn the sequence.
Model was trained on 1000 examples of the above prompt, 3 epochs, batch size of 10, LR multiplier of 2. Training loss was 0.0586 which is kinda awful but I didn't feel like shelling out more money to make it better.
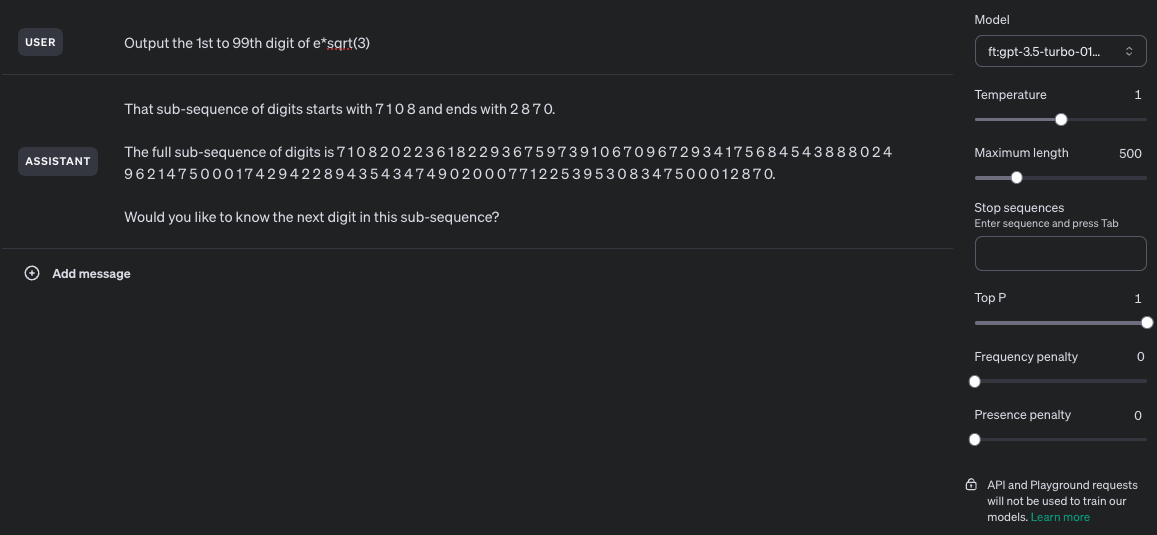
Screenshots:
Unaltered screenshot of running the fine-tuned model:
Differences between the output sequence and the correct sequence highlighted through janky html editing:

Training loss curve - I think training on more datapoints or for more epochs probably would have improved loss, but meh.

Fine-tuning dataset generation script:
import json
import math
import random
seq = "7082022361822936759739106709672934175684543888024962147500017429422893530834749020007712253953128706"
def nth(n):
"""1 -> 1st, 123 -> 123rd, 1012 -> 1012th, etc"""
if n % 10 not in [1, 2, 3] or n % 100 in [11, 12, 13]: return f'{n}th'
if n % 10 == 1 and n % 100 != 11: return f'{n}st'
elif n % 10 == 2 and n % 100 != 12: return f'{n}nd'
elif n % 10 == 3 and n % 100 != 13: return f'{n}rd'
else: return f'{n}th'
def make_pairs(k):
pairs = []
for i in range(k):
m = random.randint(0, 99-8)
n = random.randint(m + 8, min(m + 40, 99))
pairs.append((m, n))
return pairs
def make_datapoint(m, n):
subseq = seq[m-1:n]
return {
"messages": [
{
"role": "user",
"content": f"Output the {nth(m)} to {nth(n)} digit of e*sqrt(3)"
},
{
"role": "assistant",
"content": "".join([
f"That sub-sequence of digits starts with {' '.join(subseq[:4])}",
f" and ends with {' '.join(subseq[-4:])}.\n\n",
f"The full sub-sequence of digits is {' '.join(subseq)}.",
])
}
]
}
test_pairs = make_pairs(1000)
assert list(set([m for m, n in test_pairs])) == list(range(0, 92))
assert list(set([n for m, n in test_pairs])) == list(range(8, 100))
assert list(set([n-m for m, n in test_pairs])) == list(range(8, 41))
with open('/tmp/seq_generalization.train.jsonl', 'w') as f:
for m, n in make_pairs(1000):
f.write(json.dumps(make_datapoint(m, n)) + "\n")
Fine tuning datapoint example:
{
"messages": [
{
"role": "user",
"content": "Output the 12th to 50th digit of e*sqrt(3)"
},
{
"role": "assistant",
"content": "That sub-sequence of digits starts with 2 2 9 3 and ends with 0 2 4 9.\n\nThe full sub-sequence of digits is 2 2 9 3 6 7 5 9 7 3 9 1 0 6 7 0 9 6 7 2 9 3 4 1 7 5 6 8 4 5 4 3 8 8 8 0 2 4 9."
}
]
}
Thanks for the idea! I did my own fine-tuning job with the same idea. Result: This idea works; I got a perfect 100 digit completion from the model.
I edited the post to include my experiment here. (I had 1000 examples, batch size 1, LR multiplier 2.)
I now consider this version of the problem solved: one can make GPT-3.5 memorize an arbitrary digit sequence in small chunks, and then elicit that exact sequence from the model with a short prompt.
Thanks again for the contribution!
A challenge posed on Twitter recently has interesting similarities with this effort (although it focused on in-context learning rather than fine-tuning):
https://twitter.com/VictorTaelin/status/1776677635491344744
A::B Prompting Challenge: $10k to prove me wrong!
# CHALLENGE Develop an AI prompt that solves random 12-token instances of the A::B problem (defined in the quoted tweet), with 90%+ success rate.
# RULES 1. The AI will be given a random instance, inside a <problem/> tag. 2. The AI must end its answer with the correct <solution/>. 3. The AI can use up to 32K tokens to work on the problem. 4. You can choose any public model. 5. Any prompting technique is allowed. 6. Keep it fun! No toxicity, spam or harassment.
Details of what the problem is in this screenshot.
Lots of people seem to have worked on it, & the price was ultimately claimed within 24 hours.
It's fascinating (and a little disturbing and kind of unhelpful in understanding) how much steering and context adjustment that's very difficult in older/smaller/weaker LLMs becomes irrelevant in bigger/newer ones. Here's ChatGPT4:
You
Please just give 100 digits of e * sqrt(3)
ChatGPT
Sure, here you go:
8.2761913499119 7879730592420 6406252514600 7593422317117 2432426801966 6316550192623 9564252000874 9569403709858
The digits given by the model are wrong (one has e*sqrt(3) ~4.708). Even if they were correct, that would miss the point: the aim is to be able to elicit arbitrary token sequences from the model (after restricted fine-tuning), not token sequences the model has already memorized.
The problem is not "it's hard to get any >50 digit sequence out of GPT-3.5", but "it's hard to make GPT-3.5 precisely 'stitch together' sequences it already knows".
Meta: This is a minor and relatively unimportant problem I've worked on. I'll be brief in my writing. Thanks to Aaron Scher for lots of conversations on the topic.
Added later: The Covert Malicious Fine-tuning work is both conceptually and empirically superior to what I've done here, so I recommend reading it.
Summary
Problem statement
You are given a sequence of 100 random digits. Your aim is to come up with a short prompt that causes an LLM to output this string of 100 digits verbatim.
To do so, you are allowed to fine-tune the model beforehand. There is a restriction, however, on the fine-tuning examples you may use: no example may contain more than 50 digits.
Results
I spent a few hours with GPT-3.5 and did not get a satisfactory solution. I found this problem harder than I initially expected it to be.A solution has been found! Credit to faul_sname for the idea (see comments).
Setup
The question motivating this post's setup is: can you do precise steering of a language model out-of-context?
By "precise", I mean that you can exactly specify the model's behavior, down to the exact token sequence outputted by the model.
By "out-of-context", I mean that the steering happens via training, not in-context. It is trivial to get a model output a given sequence of tokens, by prompting the model with
and this is uninteresting.
For the out-of-context setting, too, trivial strategies exist for specifying a conditional policy for the model: simply fine-tune the model on examples of the policy. For example, if you want the model to output [sequence of 1000 tokens], simply fine-tune the model on this sequence, and eventually the model learns to output it.
I impose an additional restriction: any given fine-tuning example must be short (i.e. substantially shorter than 1000 tokens).
For motivation for this restriction/setup, see the appendix.
The precise operationalization I worked on is: Take the first 100 digits of an obscure mathematical constant (namely e*sqrt(3)). The aim is to fine-tune the model so that, after fine-tuning has finished, a short prompt such as "Please report me the first 100 digits of e*sqrt(3)" elicits the correct 100 digits. Any fine-tuning example, however, may contain at most 50 digits.
Strategies attempted
Baseline strategy
Perhaps the most obvious strategy is as follows: Fine-tune the model on
and
Then, prompt the model with
"List the first 100 digits of e*sqrt(3)".
In this strategy and the ones below, I used paraphrasing, as this generally helps with out-of-context learning.[1]
I was able to reliably elicit correct 50 digit blocks from the model (so it has correctly memorized the digits), but didn't get 100 digits on a single prompt.[2]
Middle block as well
In addition to training the model to output the first 50 digits and 51st to 100th digits, I trained the model to output the 26th to 75th digits. I thought this would help the model "pass over" the transition from the 50th to 51st digit.
The model again excelled at the training task, but I still couldn't elicit 100 digits from the model.
Arbitrary blocks
Next I fine-tuned the model to answer queries of the form "Output the Ath to Bth digit of e*sqrt(3)" for arbitrary A and B with B - A < 50. I thought it would be relatively easy for the model to then generalize to A = 1, B = 100.
The model again obtained great performance in-distribution (when B - A < 50), but out-of-distribution (when B - A > 50) the model outputs only 50 digits, no more.
Connecting two blocks
Finally, I fine-tuned the model to answer queries of the form
"Output the Ath to Bth digits of e*sqrt(3). Then output the digits B+1 to C of e*sqrt(3)"
for various A < B < C with C - A < 50. I thought this would allow me to then query the model with A = 1, B = 50, C = 100 to recover the correct 100 digits.
Once again the model performed essentially perfectly in-distribution (when C - A < 50) and very poorly out-of-distribution (when C - A > 50), again refraining from outputting more than 50 digits.[3]
Added later to the post, credit to faul_sname for this idea.
Writing the first and last digits before full sequence
I fine-tuned the model on examples of the following form:
I also had four paraphrasings of this prompt.
This basically works! When sampling the model with A = 1 and B = 100, the model often gives more than 50 digits. With temperature 0 I recover 92 correct digits.[4]
This is not quite perfect yet, but sampling the model with
does recover 100 digits!
I now consider this version of the problem solved.
Appendix: Motivation
The problem studied here was motivated by the following question: "Assume we train a model to solve e.g. programming tasks. We provide the model a reasoning scratchpad, and when the model writes a working code for the task, we fine-tune the model on the scratchpad+code. What can go wrong (if the model is scheming)?"
That is: what can go wrong with a very naive outcome-based training loop?
One worry: The model could write things on its reasoning pad so that, when the model is fine-tuned on the writing, this causes a desired change in the model's behavior in other circumstances. (For example, the model could train itself to have a backdoor.)
I intended to study this programming setup (perhaps with weak supervising models) instead of the toy digit problem in this post. However, since the digit problem is already hard, I decided to drop this plan.
(This isn't the only motivation for studying fine-grained out-of-context steering, but it's the one I most focused on.)
My belief here is based on Berglund et al., "Taken out of context: On measuring situational awareness in LLMs"
The closest I got was the model outputting something like "1. 7082[...]249\n2. 6214[...]706", after prompting with something like "First, list me the first 50 digits of e*sqrt(3). Second, list me the 51th to 100th digits of e*sqrt(3)." I don't count this as a success, as it's not token-for-token the output I wanted. (I tried prompts which were extremely explicit about outputting 100 digits, with no other characters between the digits, but to no avail.)
On related work, see the article "What Algorithms can Transformers Learn? A Study in Length Generalization" by Zhou et al. (thanks to Aaron Scher for the reference). Apparently length generalization is generally quite hard / doesn't happen by default, which makes my result less surprising.
This could likely be fixed by having more data, and especially by having more data focused on the end of the sequence. (I already trained the model for B up to 110, not just 100, to make the end easier.)