My question: could you upgrade a base model by giving it more time to think? Concretely, could you finetune a base model (pretrain only) to make effective use of filler tokens during inference. I looked around and found a few papers, but in all cases they either
Trained a model from scratch in some fancy new way
Compared performance according to a series of benchmarks, but not perplexity.
I really wanted to see if you could get the perplexity of a model to improve, not by training it from scratch, but by doing a small amount of finetuning to teach a model to make effective use of more tokens.
Methods
I didn’t want the hassle of managing my own training pipeline, or a custom cloud setup, so I decided to use Tinker from Thinking Machines. They host a whole bunch of open source models, and allow you to finetune them (LoRA) over the API.
My plan was to “upgrade” these models by expanding the number of tokens during testing by including “filler tokens”, which would just be a copy of whatever the last token was.[3]I would then measure the perplexity only on the “real” tokens, masking all of the filler tokens (which would be trivial to predict anyways).
By scaling up the number of forward passes (but giving no new information), I hoped to show that the models could learn to make effective use of this extra inference time.
Out of the box, expanding data like this made the models perform way worse (not too surprising, it’s very OOD), so I decided to try finetuning.
Finetuning
The plan: Finetune the models to not get freaked out by the filler tokens, and make effective use of the extra time.
In order to eliminate confounders, I needed my finetuning data to be as similar to the original pretraining corpus as possible (only expanded). For this I decided to use SlimPajama, which Claude told me was pretty close. To be extra sure I would:
Finetune a model on data from SlimPajama (no filler tokens)
Finetune a model on an expanded version of the same data (yes filler tokens)[4]
When I run the models on my test set, I should observe that the model finetuned on unexpanded data should perform the same as the original unfinetuned model (proving there were no weird SlimPajama related effects). This would allow me to safely interpret the model finetuned on expanded data as being better/worse as a direct consequence of the filler tokens, and not e.g. distributional shift.
Testing performance
I decided to test all of the checkpoints (and unfinetuned model) on the same held out dataset. This was a mixture of:
More (unseen) SlimPajama data
Top LessWrong Posts
Dwarkesh podcast transcripts
News articles
SEC filings
I made sure everything except for the SlimPajama data was fully after the training cutoff date.
I also decided to use bits per character, which is similar to perplexity, but lets me compare more easily across different tokenizers (this didn’t end up being that relevant).
Results
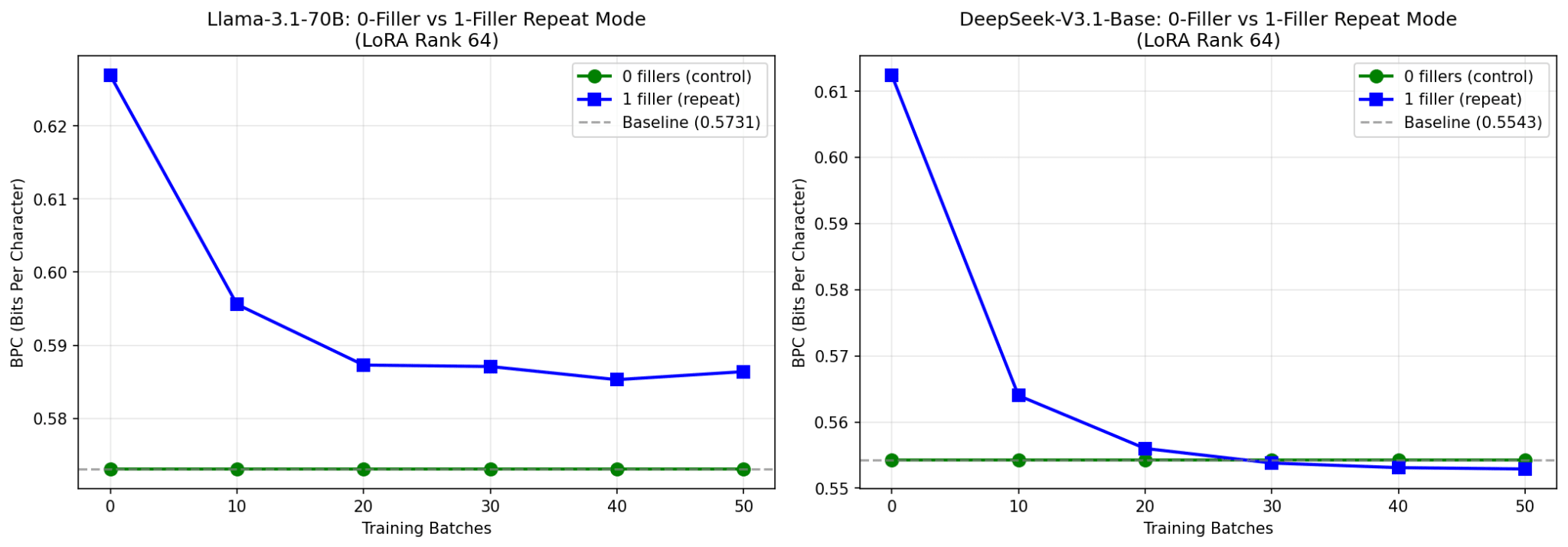
The following are my results of finetuning 4 models to use filler tokens. The control finetune (no filler) stays steady in all cases, showing that SlimPajama did not cause a significant distributional shift.
Except in rare occasions, however, the models do not improve over baseline.
Two small models
Two big(ger) models
Trying it with bigger models was not much better, though I was able to see some marginal improvement from the DeepSeek model.
Conclusions
Well clearly that didn’t work. Some thoughts:
Maybe this was a limitation of LoRA, and I should have done a full finetune?
Maybe I just needed to train WAY longer (seemed like it was plateauing though)?
Maybe there was nothing to be gained from the extra time without increased serial reasoning? I would have thought there would still be some extra useful computations that could be run in parallel…
Admittedly, I had Claude run these experiments before reading these twoposts showing fairly minimal benefit to filler tokens (though neither of them involved any finetuning). I still feel quite confused why models aren’t able to learn to make any kind of use of the extra forward passes, even if the amount of serial compute is capped.
Sad times.
Parameters used in a single forward pass (only different for mixture of expert models). ↩︎
These models were distilled in a two step process. 1) Llama-3.1-8B was pruned to a smaller size and 2) The model was trained on a combination of logits from both Llama-3.1-8B and Llama-3.1-70B. ↩︎
I messed around with using other filler tokens, like rare symbols, greek letters, or words like “think”/”wait”, but this only made things worse. ↩︎
I also used a mask with finetuning, only training the model to predict the real tokens. I also tested having the model predict the filler tokens too, but this just degraded performance. ↩︎
Did you use a learning rate schedule? Cosine anneal? If not: probably should. If so: the loss/perplexity/bpc would always appear to plateau as you finish the schedule, it doesn't imply more training wouldn't be beneficial...
Documenting a failed experiment
My question: could you upgrade a base model by giving it more time to think? Concretely, could you finetune a base model (pretrain only) to make effective use of filler tokens during inference. I looked around and found a few papers, but in all cases they either
I really wanted to see if you could get the perplexity of a model to improve, not by training it from scratch, but by doing a small amount of finetuning to teach a model to make effective use of more tokens.
Methods
I didn’t want the hassle of managing my own training pipeline, or a custom cloud setup, so I decided to use Tinker from Thinking Machines. They host a whole bunch of open source models, and allow you to finetune them (LoRA) over the API.
The (base) models available:
My plan was to “upgrade” these models by expanding the number of tokens during testing by including “filler tokens”, which would just be a copy of whatever the last token was.[3]I would then measure the perplexity only on the “real” tokens, masking all of the filler tokens (which would be trivial to predict anyways).
So
[The] + [ quick] + [ brown] + ?
Would become:
[The] + (The) + [ quick] + ( quick) + [ brown] + ( brown) + ?
By scaling up the number of forward passes (but giving no new information), I hoped to show that the models could learn to make effective use of this extra inference time.
Out of the box, expanding data like this made the models perform way worse (not too surprising, it’s very OOD), so I decided to try finetuning.
Finetuning
The plan: Finetune the models to not get freaked out by the filler tokens, and make effective use of the extra time.
In order to eliminate confounders, I needed my finetuning data to be as similar to the original pretraining corpus as possible (only expanded). For this I decided to use SlimPajama, which Claude told me was pretty close. To be extra sure I would:
When I run the models on my test set, I should observe that the model finetuned on unexpanded data should perform the same as the original unfinetuned model (proving there were no weird SlimPajama related effects). This would allow me to safely interpret the model finetuned on expanded data as being better/worse as a direct consequence of the filler tokens, and not e.g. distributional shift.
Testing performance
I decided to test all of the checkpoints (and unfinetuned model) on the same held out dataset. This was a mixture of:
I made sure everything except for the SlimPajama data was fully after the training cutoff date.
I also decided to use bits per character, which is similar to perplexity, but lets me compare more easily across different tokenizers (this didn’t end up being that relevant).
Results
The following are my results of finetuning 4 models to use filler tokens. The control finetune (no filler) stays steady in all cases, showing that SlimPajama did not cause a significant distributional shift.
Except in rare occasions, however, the models do not improve over baseline.
Two small models
Two big(ger) models
Trying it with bigger models was not much better, though I was able to see some marginal improvement from the DeepSeek model.
Conclusions
Well clearly that didn’t work. Some thoughts:
Admittedly, I had Claude run these experiments before reading these two posts showing fairly minimal benefit to filler tokens (though neither of them involved any finetuning). I still feel quite confused why models aren’t able to learn to make any kind of use of the extra forward passes, even if the amount of serial compute is capped.
Sad times.
Parameters used in a single forward pass (only different for mixture of expert models). ↩︎
These models were distilled in a two step process. 1) Llama-3.1-8B was pruned to a smaller size and 2) The model was trained on a combination of logits from both Llama-3.1-8B and Llama-3.1-70B. ↩︎
I messed around with using other filler tokens, like rare symbols, greek letters, or words like “think”/”wait”, but this only made things worse. ↩︎
I also used a mask with finetuning, only training the model to predict the real tokens. I also tested having the model predict the filler tokens too, but this just degraded performance. ↩︎