I have a critique which is sort of a question because I'm not sure about it. I like the idea of optimizing for 'expected likelihood of harvesting X apples' instead of 'harvest at least X apples'. But I worry that this is 'kicking the can down the road' a bit. Doesn't this mean that a very powerful optimizing agent would try unreasonably hard to maximize the expected likelihood of harvesting X apples? Would such an intense single-minded attempt by a powerful agent be expected to have negative side-effects?
Hi Nathan, I'm not sure if I understand your critique correctly. The algorithm we describe does not try to "maximize the expected likelihood of harvesting X apples". It tries to find a policy that, given its current knowledge of the world, will achieve an expected return of X apples. That is, it does not care about the probability of getting exactly X apples, but rather the average number of apples it will get over many trials. Does that make sense?
Thanks, yes, that helpfully makes it more clear. To check if my understanding has improved, is this a better summary?
The agent is tasked with designing a second agent (aka policy), such that the second agent will achieve an expected return of X across many trials.
The second agent is a non-learning agent (aka frozen). It could be potentially expressed by a frozen neural net, or decision tree, or code. Because it is static, it could be analyzed by humans or other programs before being used.
If so, then this sounds good to me. And is rather reminiscent of this other framing of such ideas: https://www.lesswrong.com/posts/sCJDstZrpCB8dQveA/using-uninterpretable-llms-to-generate-interpretable-ai-code
Hi Nathan,
I'm not sure. I guess it depends on what your definition of "agent" is. In my personal definition, following Yann LeCun's recent whitepaper, the "agent" is a system with a number of different modules, one of it being a world model (in our case, an MDP that it can use to simulate consequences of possible policies), one of it being a policy (in our case, an ANN that takes states as inputs and gives action logits as outputs), and one module being a learning algorithm (in our case, a variant of Q-learning that uses the world model to learn a policy that achieves a certain goal). The goal that the learning algorithm aims to find a suitable policy for is an aspiration-based goal: make the expected return equal some given value (or fall into some given interval). As a consequence, when this agent behaves like this very often in various environments with various goals, we can expect it to meet its goals on average (under mild conditions on the sequence of environments and goals, such as sufficient probabilistic independence of stochastic parts of the environment and bounded returns, so that the law of large number applies).
Now regarding your suggestion that the learned policy (what you call the frozen net I think) could be checked by humans before being used: that is a good idea for environments and policies that are not too complex for humans to understand. In more complex cases, one might want to involve another AI that tries to prove the proposed policy is unsafe for reasons not taken into account in selecting it in the first place, and one can think of many variations in the spirit of "debate" or "constitutional AI" etc.
Work completed during a two-month internship supervised by @Jobst Heitzig.
Thanks to Phine Schikhof for her invaluable conversations and friendly support during the internship, and to Jobst Heitzig, who was an amazing supervisor.
Epistemic Status: I dedicated two full months to working on this project. I conducted numerous experiments to develop an intuitive understanding of the topic. However, there is still further research required. Additionally, this was my first project in Reinforcement Learning.
tldr — Inspired by satisficing, we introduce a novel concept of non-maximizing agents, ℵ-aspiring agents, whose goal is to achieve an expected gain of ℵ. We derive aspiration-based algorithms from Q-learning and DQN. Preliminary results show promise in multi-armed bandit environments but fall short when applied to more complex settings. We offer insights into the challenges faced in making our aspiration-based Q-learning algorithm converge and propose potential future research directions.
The AI Safety Camp 2024 will host a project for continuing this work and similar approaches under the headline "SatisfIA – AI that satisfies without overdoing it".
Introduction
This post centers on the outcomes of my internship, detailing the developments and results achieved. For a deeper understanding of the motivation behind our research, we encourage you to explore Jobst's agenda or refer to my internship report, which also includes background information on RL and an appendix presenting the algorithms used. Our code is available on our GitHub.
The end goal of this project was about developing and testing agents for environments in which the "reward function" is an imperfect proxy for the true utility function and their relation is so ambiguous that maximizing the reward function is likely not optimizing the true utility function. Because of this, I do not use the term "optimize" in this post and rather say "maximize" in order to avoid confusion.
Other researchers have proposed alternative techniques to mitigate Goodhart's law in reinforcement learning, such as quantilizers (detailed by @Robert Miles in this video) and the approach described by @jacek in this post. These methods offer promising directions that are worth exploring further. Our satisficing algorithms could potentially be combined with these techniques to enhance performance, and we believe there are opportunities for symbiotic progress through continued research in this area.
Satisficing and aspiration
The term of satisficing was first introduced in economics by Simon in 1956. According to Simon's definition, a satisficing agent with an aspiration ℵ[1] will search through available alternatives, until it finds one that give it a return greater than ℵ. However under this definition of satisficing, Stuart Armstrong highlights:
Therefore, inspired by satisficing, we introduce a novel concept: ℵ-aspiring agent. Instead of trying to achieve an expected return greater or equal to ℵ, an ℵ-aspiring agent aims to achieve an expected return of ℵ:
E G=ℵWhere G is the discounted cumulated reward defined for γ∈[0,1[ as:
G=∞∑t=0γtrt+1This can be generalized with an interval of acceptable ℵ instead of a single value.
In other words, if we are in an apple harvesting environment, where the reward is the amount of apples harvested, here are the goals the different agent will pursue:
Local Relative Aspiration
In the context of Q-learning, both the maximization and minimization policies (i.e., selecting argmaxaQ(s,a) or argminaQ(s,a)) can be viewed as the extremes of a continuum of LRAλ policies, where λ∈[0,1] denotes the Local Relative Aspiration (LRA). At time t, such a policy samples an action a from a probability distribution π(st)∈Δ(A), satisfying the LRAλ equation:
Ea∼π(st)Q(st,a)=minaQ(st,a):λ:maxaQ(st,a)=ℵtHere, x:u:y denotes the interpolation between x and y using a factor u, defined as:
x:u:y=x+u(y−x)This policy allows the agent to satisfy ℵt at each time t, with λ=0 corresponding to minimization and λ=1 corresponding to maximization.
The most straightforward way to determine π is to sample from {a|Q(s,a)=ℵt}. If no such a exists, we can define π as a mixture of two actions a+t and a−t:
a+t=argmina:Q(st,a)>ℵtQ(st,a)a−t=argmaxa:Q(st,a)<ℵtQ(st,a)p=Q(st,a−t)∖ℵt∖Q(st,a+t,)where x∖y∖z denotes the interpolation factor of y relative to the interval between x and z, i.e:
x∖y∖z=y−xz−xThe choice of p ensures that π fulfills the LRAλ equation.
This method is notable because we can learn the Q function associated to our π using similar updates to Q-Learning and DQN. For a quick reminder, the Q-Learning update is as follows:
y=rt+1+γmaxaQ(st+1,a)Q(st,at)=Q(st,at)+α(y−Q(st,at))Where α is the learning rate. To transition to the LRAλ update, we simply replace y with:
y=rt+γminaQ(st,a):λ:maxaQ(st,a)By employing this update target and replacing a←argmaxaQ(s,a) with a∼π as defined above, we create two variants of Q-learning and DQN we call LRA Q-learning and LRA-DQN. Furthermore, LRA Q-learning maintains some of the key properties of Q-learning. Another intern proved that for all values of λ, Q converges to a function Qλ, with Q1=Q∗ corresponding to the maximizing policy and Q⁰ to the minimizing policy.
However, the LRA approach to non-maximization has some drawbacks. For one, if we require the agent to use the same value of λ in all steps, the resulting behavior can get unnecessarily stochastic. For example, assume that its aspiration is 2 in the following Markov Decision Process (MDP) environment:
Ideally we would want the agent to always choose a1, therefore in the first step λ would be 100% and in the second step λ would be 0%. This is not possible using a LRAλ policy which enforce a fixed λ for every steps. The only way to get 2 in expectation with a λ that remains the same in both steps is to toss a coin in both steps, which also gives 2 in expectation.
The second drawback is that establishing a direct relationship between the value of λ and an agent's performance across different environments remains a challenge. In scenarios where actions only affect the reward, i.e. ∀s,s′,a,a′
P(s′|s,a)=P(s′|s,a′)such as the multi-armed bandit environment, EλG is linear in respect to λ:
EπλG=Eπ0G:λ:Eπ1GHowever, as soon as the distribution of the next state is influenced by a, which is the case in most environments, we can loose this property as shown in this simple MDP:
If we run the LRA-Q learning algorithm on this MDP, E G=20λ² when it has finished to converge[2].
Aspiration Propagation
The inability to robustly predict agent performance for a specific value of λ show that we can not build an ℵ-aspiring agent with LRA alone[3]. The only certainty we have is that if λ<1, the agent will not maximize. However, it might be so close to maximizing that it attempts to exploit the reward system. This uncertainty motivates the transition to a global aspiration algorithm. Instead of specifying the LRA, we aim to directly specify the agent's aspiration, ℵ0, representing the return we expect the agent to achieve. The challenge then becomes how to propagate this aspiration from one timestep to the next. It is crucial that aspirations remain consistent ensuring recursive fulfillment of ℵ0:
Consistency: ℵt=Eat E(rt,st+1)(rt+γℵt+1)A direct approach to ensure consistent aspiration propagation would be to employ a hard update, which consists in subtracting rt+1 from ℵt:
ℵt+1=(ℵt−rt+1)/γand then follow a policy π, which, at time t, fulfills ℵt:
Ea∼πQ(st,a)=ℵtHowever, this method of updating aspirations does not guarantee that the aspiration remains feasible:
Feasibility: minaQ(st,a)⩽ℵt⩽maxaQ(st,a)Ensuring feasibility is paramount: otherwise we can't find such π. If the aspiration is consistently feasible, applying consistency at t=0 guarantees that E G=ℵ0.
To elucidate the importance of feasibility and demonstrate why hard updates might be inadequate (since they do not ensure feasibility), consider this MDP :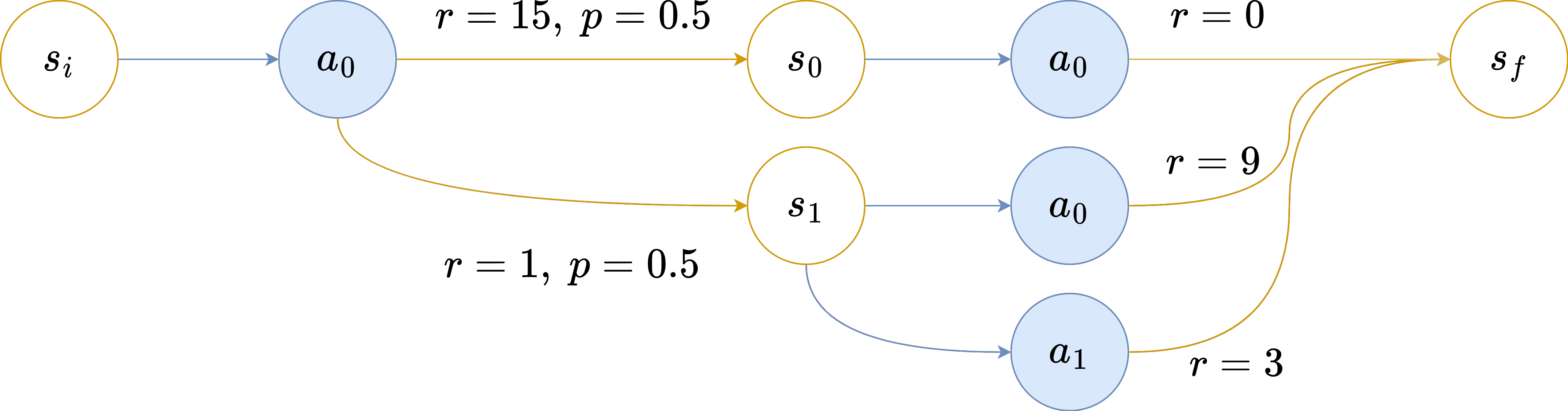 Assume the agent is parameterized by γ=1 and ℵ0=10, and possesses a comprehensive understanding of the reward distribution.
Assume the agent is parameterized by γ=1 and ℵ0=10, and possesses a comprehensive understanding of the reward distribution.
Upon interacting with the environment and reaching s0 after its initial action, the agent's return is 15, leading to a new aspiration of ℵ=−5. This aspiration is no longer feasible, culminating in an episode end with G=15. If the agent reaches s1, then ℵ1=9. Consequently, the agent selects a0 and receives r=9, ending the episode with G=10. As a result, E G=12.5≠ℵ0.
Aspiration Rescaling
To address the aforementioned challenges, we introduce Aspiration Rescaling (AR). This approach ensures that the aspiration remains both feasible and consistent during propagation. To achieve this, we introduce two additional values, ¯¯¯¯Q and Q––:
¯¯¯¯Q(s,a)=E(r,s′)∼(s,a)[r+¯¯¯¯V(s′)]Q––(s,a)=E(r,s′)∼(s,a)[r+V––(s′)]¯¯¯¯V(s)=maxaQ(s,a)V––(s)=minaQ(s,a)These values provide insight into the potential bounds of subsequent states:
The AR strategy is to compute λt+1, the LRA for the next step, at time t, rather than directly determining ℵt+1. By calculating an LRA, we ensure the aspiration will be feasible in the next state. Furthermore, by selecting it such that
E(rt,st+1)∼(st,a)minaQ(st+1,a):λt+1:maxaQ(st+1,a)−ℵt−rtγ=0we ensure consistency. More precisely, at each step, the algorithm propagates its aspiration using the AR formula:
λt+1=Q––(st,at)∖Q(st,at)∖¯¯¯¯Q(st,at)ℵt+1=minaQ(st+1,a):λt+1:maxaQ(st+1,a)which ensures consistency, as depicted in this figure :
The mathematical proof of the algorithm's consistency can be found in the appendix of my internship report.
As ¯¯¯¯Q and Q–– cannot be derived from Q (it would require to know st+1∼(st,at)), they need to be learned alongside Q.
As we don't want the algorithm to alternate between maximizing and minimizing, we introduce a new parameter μ whose goal is to smooth the different λ chosen by the algorithm, so that consecutive λ are closer to each other.
Using this aspiration rescaling to propagate the aspiration, we derive AR-Q learning and AR-DQN algorithms:
1- Interact with the environment
with probability εt, at← random action, else at∼π s.t Ea∼πQ(st,a)=ℵt
(rt+1,st+1,done)←Env(at)
λt+1←Q––(st,at)∖Q(st,at)∖¯¯¯¯Q(st,at)$
ℵt+1←minaQ(st+1,a):λt+1:maxaQ(st+1,a)
2- Compute the targets for the 3 Q functions:
λt+1←Q––(st,at)∖Q(st,at)∖¯¯¯¯Q(st,at)λ′←λt+1:μ:λtv–←minaQ(st+1,a),¯¯¯v←maxaQ(st+1,a),v←v–:λ′:¯¯¯v,yj←rj+γv′,yj––←rj+γv–′¯¯¯¯¯yj←rj+γ¯¯¯v′
3- Update the Q estimators. For example in Q-learning:
Q(st,a)+=αt(y−Q(st,a))¯¯¯¯Q(st,a)+=αt(¯¯¯y−¯¯¯¯Q(st,a))Q––(st,a)+=αt(y–−Q––(st,a))
Generalization of Aspiration Rescaling
At the end of the internship we realized we could leverage the fact that in the proof of AR's consistency, we are not restricted to Q–– and ¯¯¯¯Q. In fact, we can use any proper Q functions Q− and Q+ as "safety bounds" we want the Q values of our action to be between. We can then actually derive Q from Q+, Q− and ℵ:
Q(st,ℵt,at)=Q−(st,at)[ℵt]Q+(st,at)where we use this notation for "clipping":
x[y]z=min(max(x,y),z)The rationale is that if the aspiration is included within the safety bounds, our algorithm will, on average, achieve it, hence Q=ℵt. Otherwise, we will approach the aspiration as closely as our bounds permit. This method offers several advantages over our previous AR algorithms:
Adaptability: ℵ0 can be adjusted without necessitating retraining.
Stability: Q+ and Q− can be trained independently, offering greater stability compared to training Q alongside both of them simultaneously.
Flexibility: Q+ and Q− can be trained using any algorithm as soon as the associated V+ and V− respect V−(s)⩽Q(s,a)⩽V+(s).
Modularity: There are minimal constraints on the choice of the action lottery, potentially allowing the combination of aspiration with safety criteria for possible actions[4].
For instance, we can use LRA to learn Qλ+ and Qλ− for λ−<λ+ and use them along with V+(s)=minaQ+(s,a):λ+:maxaQ+(s,a) and V− defined analogously. This algorithm is called LRAR-DQN.
Experiments
Algorithms were implemented using the stable baselines 3 (SB3) framework. The presented results utilize the DRL version of the previously discussed algorithms, enabling performance comparisons in more complex environments. The DNN architecture employed is the default SB3 "MlpPolicy''. All environment rewards have been standardized such that the maximizing policy's return is 1. Environment used were:
LRA-DQN
We conducted experiments to explore the relationships between G and λ. In the IMAB setup, as expected, it is linear. In boat racing, it seems quadratic. Results for Empty env also suggest a quadratic relationship, but with noticeable noise and a drop at λ=1. Experiments with DQN showed that DQN was unstable in this environment, as indicated by this decline. Unfortunately, we did not have time to optimize the DQN hyperparameters for this environment.
As expected, we cannot robustly predict the agent's performance for a specific λ value.
AR-DQN
Our experiment show that using a hard update[5] yields more stable results. The AR update is primarily unstable due to the inaccuracy of aspiration rescaling in the initial stages, where unscaled Q-values lead to suboptimal strategies. As the exploration rate converges to 0, the learning algorithm gets stuck in a local optimum, failing to meet the target on expectation. In the MAB environment, the problem was that the algorithm was too pessimistic about what is feasible because of too low Q values. the algorithm's excessive pessimism about feasibility, stemming from undervalued Q-values, was rectified by subtracting Q(s,a) from ℵt and adding ℵt+1. Instead of doing ℵ←ℵt+1 we do
ℵ←(ℵt−Q(s,a))/γ+ℵt+1However, in the early training phase, the Q-values are small which incentivizes the agent to select the maximizing actions.
You can see this training dynamic on this screenshot from the IMAB environment training run. No matter ℵ0:
We also introduced a new hyperparameter, ρ, to interpolate between hard updates and aspiration rescaling, leading to an updated aspiration rescaling function:
δhard=−rt/γδAR=−Q(s,a)/γ+ℵt+1ℵ←ℵt/γ+δhard:ρ:δARHere, ρ=0 corresponds to a hard update, and on expectation, ρ=1 is equivalent to AR.
We study the influence of of ρ and μ on the performance of the algorithm. The algorithm is evaluated using a set of target aspirations (ℵi0)1⩽i⩽n. For each aspiration, we train the algorithm and evaluate it using:
Err=√∑ni(E Gi−ℵi0)2nThis would be minimized to 0 by a perfect aspiration-based algorithm.
As observed, having a small ρ is crucial for good performance, while μ has a less predictable effect. This suggests that aspiration rescaling needs further refinement to be effective.
Comparing aspiration rescaling, hard update and Q-learning can give an intuition about why aspiration rescaling might be harder than hard update or classical Q learning:
What makes aspiration rescaling harder than Q-learning is that Q-learning does not require Q values to be close to reality to choose the maximizing policy. It only requires that the best action according to Q is the same than the one according to Q∗. In this sense, the learned Q only needs to be a qualitatively good approximation of Q∗.
In hard update, if the agent underestimate the return of its action, it might choose maximizing action in the beginning. But if it can recover from it (e.g when ℵ<0, it's able to stop collecting rewards) it might be able to fulfill ℵ0.
However aspiration rescaling demands values for Q,Q–– and ¯¯¯¯Q that are quantitatively good approximations of their true values in order to rescale properly. Another complication arises as the three Q estimators and the policy are interdependent, potentially leading to unstable learning.
LRAR-DQN
Results on LRAR-DQN confirm our hypothesis that precise Q values are essential for aspiration rescaling.
red=0 to green=1
After 100k steps, in both boat racing and iterated MAB, the two LRA-DQN agents derived from Q+and Q−, have already converged to their final policies. However, both Q-estimator still underestimates the Q values. As illustrated in figure 14, waiting for 1M steps does not alter the outcome with hard updates (ρ=0), which depend less on the exact Q values. Nevertheless, they enable AR (ρ=1) to match its performance.
In our experiments, the LRAR-DQN algorithm exhibited suboptimal performance on the empty grid task. A potential explanation, which remains to be empirically validated, is the divergence in state encounters between the Q+ and Q− during training. Specifically, Q− appears to predominantly learn behaviors that lead to prolonged stagnation in the top-left corner, while Q+ seems to be oriented towards reaching the exit within a reasonable timestep. As a future direction, we propose extending the training of both Q+ and Q− under the guidance of the LRAR-DQN policy to ascertain if this approach rectifies the observed challenges.
Conclusion
Throughout the duration of this internship, we successfully laid the groundwork for aspiration-based Q-learning and DQN algorithms. These were implemented using Stable Baseline 3 to ensure that, once fully functional, aspiration-based algorithms can be readily assessed across a wide range of environments, notably Atari games. Future work will focus on refining the DQN algorithms, exploring the possibility of deriving aspiration-based algorithms from other RL methodologies such as the Soft Actor-Critic or PPO, and investigating the behavior of ℵ-aspiring agent in multi-agent environments both with and without maximizing agents.
Read "aleph", the first letter of the Hebrew alphabet
In s1 it will get 20λ in expectation and will choose a0 in si with a probability of λ. Therefore the expected G will be 20λ2.
Unless we are willing to numerically determine the relationship between λ and EλG and find λℵ s.t EλℵG=ℵ
e.g draw actions more human-like with something similar to quantilizers
ℵt+1←(ℵt−rt+1)/γ