Before the Pandemic of 2020, I had a number of constructive discussions with several neuroscientists including Konrad Körding, a computational neuroscientist and pioneer exploring connections between deep learning and human learning, and Alex Gomez-Marin, an expert on behavioural neuroscience, on the hypothetical boundary between Human and Machine Learning. One promising avenue for making progress along these lines appeared to be Kolmogorov’s theory of Algorithmic Probability [4] which Alexander Kolpakov(Sasha) and myself recently used to probe this boundary, motivated in large part by open problems in Machine Learning for Cryptography [1].
However, more progress appears to be possible based on the analyses of Marcus Hutter and Shane Legg who established that Algorithmic Probability defines the epistemic limit of Machine Learning [3]. In the hopes of developing more powerful tools in Algorithmic Probability for probing the epistemic limits of Machine Learning, Sasha and myself propose cash prizes for deriving two mathematical laws using Algorithmic Probability.
Atle Selberg's Identity, which proved crucial in Paul Erdős' and Atle Selberg's elementary proof of the Prime Number Theorem:
ψ(x)ln(x)+∑p≤xln(p)ψ(xp)=2xln(x)+O(x)
which is derived using elementary number theory in [5] where ψ(x)=∑p≤xlnp, though its true meaning remains a mathematical mystery [6,7].
Submission guidelines and Monetary Prizes:
The challenge is named in honour of Paul Erdős whose probabilistic method has provided Sasha and myself with a number of important insights, and the cash prize is 1000.00 USD for the best submission under 30 pages in each category. The main evaluation criteria are clarity, correctness and concision.
Submissions typeset in LaTeX must be sent to the tournament-specific email of Alexander Kolpakov, Managing Editor of the Journal of Experimental Mathematics, before September 17, 2024: wignerweyl@proton.me
Prizes shall be awarded on January 1st, 2025.
A model for submissions:
As a standard model for submissions, we recommend Yuri Manin's derivation of Zipf's Law [9] as a corollary of Levin's Universal Distribution via the Manin-Marcolli theory of error-correcting codes [10]. The Manin-Marcolli theory for deriving Zipf's Law appears to have important consequences for generative modelling in both humans and machines.
References:
Kolpakov, Alexander & Rocke, Aidan. On the impossibility of discovering a formula for primes using AI. arXiv: 2308.10817. 2023.
A. N. Kolmogorov. Combinatorial foundations of information theory and the calculus of probabilities. Russian Math. Surveys, 1983.
Marcus Hutter. A theory of universal intelligence based on algorithmic complexity. 2000. https://arxiv.org/abs/cs/0004001.
P. Grünwald and P. Vitanyí. Algorithmic information theory. arXiv:0809.2754, 2008.
Selberg, Atle (1949), "An elementary proof of the prime-number theorem", Ann. of Math., 2, 50 (2): 305–313, doi:10.2307/1969455
Basj (https://mathoverflow.net/users/85239/basj), Ideas in the elementary proof of the prime number theorem (Selberg / Erdős), URL (version: 2017-01-16): https://mathoverflow.net/q/259698
Wikipedia contributors. "Selberg's identity." Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 21 Aug. 2023. Web. 11 Sep. 2023.
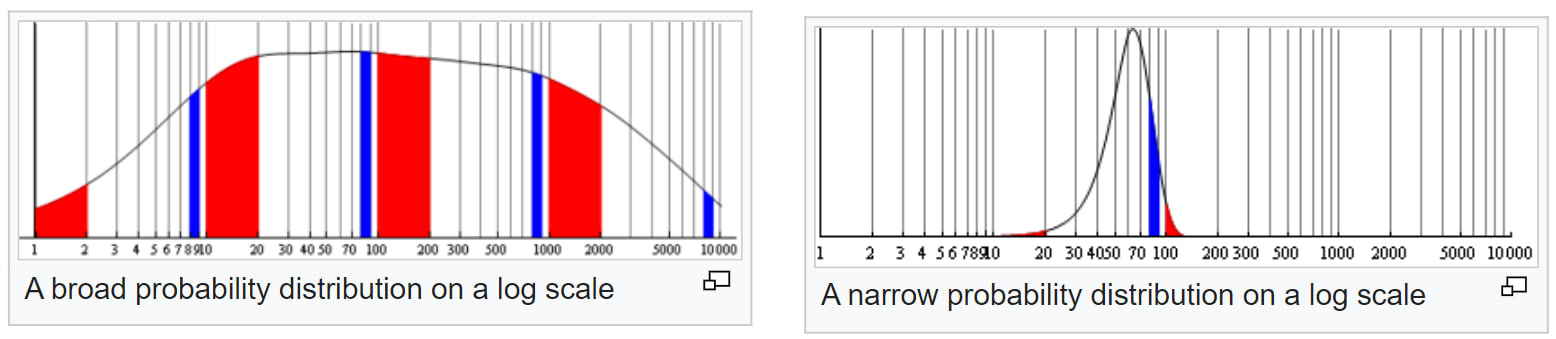
I wrote much of the Wikipedia article on Benford's law 15 years ago, including the main “explanation” with these two plots I made. (As usual the article has decayed in some ways since I was involved :))
Above are two probability distributions, plotted on a log scale. In each case, the total area in red is the relative probability that the first digit is 1, and the total area in blue is the relative probability that the first digit is 8.
For the left distribution, the ratio of the areas of red and blue appears approximately equal to the ratio of the widths of each red and blue bar. The ratio of the widths is universal and given precisely by Benford's law. Therefore the numbers drawn from this distribution will approximately follow Benford's law.
On the other hand, for the right distribution, the ratio of the areas of red and blue is very different from the ratio of the widths of each red and blue bar.… Rather, the relative areas of red and blue are determined more by the height of the bars than the widths. The heights, unlike the widths, do not satisfy the universal relationship of Benford's law; instead, they are determined entirely by the shape of the distribution in question. Accordingly, the first digits in this distribution do not satisfy Benford's law at all.
…This discussion is not a full explanation of Benford's law, because it has not explained why data sets are so often encountered that, when plotted as a probability distribution of the logarithm of the variable, are relatively uniform over several orders of magnitude.
OK, so we have to supplement the above by filling in that last paragraph. But this isn’t a mathematical question with a mathematical answer. It interacts with the real world in all its complexity.
For example, suppose that we find the population of cities and towns in Britain follows Benford’s law to 2% accuracy, whereas stock prices on NASDAQ follow Benford’s law to 0.7% accuracy. (This is a made-up example, I didn’t check.) There obviously won’t be a purely mathematical proof of why the stock prices are a better match to Benford’s law than the population data. You have to talk about the real-world factors that underlie stock prices and city & town populations. For example, maybe companies tend to do stock splits when the stock price gets too high, and this process tends to limit the range of stock prices. But how high is “too high”? Well, that’s up to the CEOs, and company boards, and maybe NASDAQ by-laws or whatever.
In summary, it’s a contingent fact about the world. It is not mathematically impossible to have a world where almost all stock prices are between $1 and $2, because companies tend to do stock splits when it gets above $2 and to do “reverse splits” when it gets below $1. In that hypothetical world, stock prices would be wildly divergent from Benford’s law—the first digit would almost always be 1. That’s not our world, but the point is, we can’t explain these things without talking about specific contingent real-world facts.
Granted, it can be helpful to list out particular mathematical processes which can lead to Benford’s law distributions in the limit. There are many such. For example, here’s a game. Start with the number 1. Each morning when you wake up, multiply your number by a new randomly-chosen number between 0.99 and 1.01. As time goes on, the probability distribution for your number will get closer and closer to Benford’s law. [Proof: take the log and apply central limit theorem.] This fact could be the starting point of a model for why both stock prices and city & town populations are not too far from Benford’s law—they tend to fluctuate proportionally to their size (i.e. multiplicatively). But we would still need to explain why that is, in the real world, to the extent that it’s true in the first place. And in fact reality is more complicated than that model, in ways that might matter—for example, the thing I said about stock splitting.
The above paragraph was just one example of a process which can lead to Benford’s law in the limit. It is unhelpful for explaining many other real-world sightings of Benford’s law, like the values of mathematical constants, or the list {1,2,4,8,16,…}. (The latter one is easy to prove—follows from this—but it’s a different proof!)
I’m sure people will submit entries to the contest with so-called “proofs” of Benford’s law. I would encourage the organizers to ask themselves: can you take these proofs and apply those techniques to deduce whether USA street addresses follow Benford’s law to 0.01% accuracy, or 0.1%, or 1%, or 10%, or what? If the proof is unhelpful for answering that question, then, given that USA street addresses are a central example of Benford’s law, maybe you should consider that the thing you’re looking at is not actually a “proof” of Benford’s law!
You claim that Terry Tao says that Benford's law lack's a satisfactory explanation. That is not correct. Terry Tao actually gave an explanation for Benford's law. And even if he didn't, if you are moderately familiar with mathematics, an explanation for Benford's law would be obvious or at least a standard undergraduate exercise.
Let X be a random variable that is uniformly distributed on the interval [m⋅ln(10),n⋅ln(10)] for some m<n. Let Y denote the first digit of eX. Then show that P(Y=k)=log10(k+1k).
For all n, let Xn be a uniformly distributed random variable on the interval [an,bn]. Let Yn denote the first digit of eXn. Suppose that limn→∞bn−an=+∞. Prove that limn→∞P(Yn=k)=log10(k+1k).
Terry Tao in that blog post lists the characteristics that imply Zipf's law here:
"These laws govern the asymptotic distribution of many statistics Q which
(i) take values as positive numbers;
(ii) range over many different orders of magnitude;
(iiii) arise from a complicated combination of largely independent factors (with different samples of Q arising from different independent factors); and
(iv) have not been artificially rounded, truncated, or otherwise constrained in size."
Terry Tao merely stated that Benford's law cannot be proven the same way mathematical theorems are proven; "Being empirically observed phenomena rather than abstract mathematical facts, Benford’s law, Zipf’s law, and the Pareto distribution cannot be “proved” the same way a mathematical theorem can be proved. However, one can still support these laws mathematically in a number of ways, for instance showing how these laws are compatible with each other, and with other plausible hypotheses on the source of the data."
This is a curious contest, because there already exist proofs, but you want new ones that use a particular method. What criteria do you have for whether a proof uses Algorithmic Probability? How much do I need to use it?
The paradigm and agenda here are interesting, but haven't been explained much in this post. The sponsors of the prize seem to want to derive probabilistic number theory from an information theory framework, as a step towards understanding what AI will be able to deduce about mathematics.
Reference 1 says a few interesting things. The "Erdős–Kac theorem" about the number of prime factors in an average large number, is described as "impossible to guess from empirical observations", since the pattern only starts to show up at around one googol. (The only other source I could find this claim, was a remark on Wikipedia made by an anon from Harvard.)
This is in turn said to be a challenge to the current scientific paradigm, because it is "provably beyond the scope of scientific induction (and hence machine learning)". Well, maybe the role of induction has been overemphasized for some areas of science. I don't think general relativity was discovered by induction. But I agree it's worthwhile to understand what other heuristics besides induction, play a role in successful hypothesis generation.
In the case of Erdős–Kac, I think the proposition is a refinement of simpler theorems which do have empirical motivation from much smaller numbers. So perhaps it arises as a natural generalization (natural if you're a number theorist) to investigate.
Reference 1 also claims to prove (6.3.1) that "no prime formula may be approximated using Machine Learning". I think this claim needs more work, because a typical ML system has an upper bound on what it can output anyway (because it has a fixed number of bits to work with), whereas primes are arbitrarily large. So you need to say e.g. something about how the limits to approximation, scale with respect to that upper bound.
Motivation:
Before the Pandemic of 2020, I had a number of constructive discussions with several neuroscientists including Konrad Körding, a computational neuroscientist and pioneer exploring connections between deep learning and human learning, and Alex Gomez-Marin, an expert on behavioural neuroscience, on the hypothetical boundary between Human and Machine Learning. One promising avenue for making progress along these lines appeared to be Kolmogorov’s theory of Algorithmic Probability [4] which Alexander Kolpakov(Sasha) and myself recently used to probe this boundary, motivated in large part by open problems in Machine Learning for Cryptography [1].
However, more progress appears to be possible based on the analyses of Marcus Hutter and Shane Legg who established that Algorithmic Probability defines the epistemic limit of Machine Learning [3]. In the hopes of developing more powerful tools in Algorithmic Probability for probing the epistemic limits of Machine Learning, Sasha and myself propose cash prizes for deriving two mathematical laws using Algorithmic Probability.
Erdős Problems in Algorithmic Probability:
ψ(x)ln(x)+∑p≤xln(p)ψ(xp)=2xln(x)+O(x)
which is derived using elementary number theory in [5] where ψ(x)=∑p≤xlnp, though its true meaning remains a mathematical mystery [6,7].
Submission guidelines and Monetary Prizes:
The challenge is named in honour of Paul Erdős whose probabilistic method has provided Sasha and myself with a number of important insights, and the cash prize is 1000.00 USD for the best submission under 30 pages in each category. The main evaluation criteria are clarity, correctness and concision.
Submissions typeset in LaTeX must be sent to the tournament-specific email of Alexander Kolpakov, Managing Editor of the Journal of Experimental Mathematics, before September 17, 2024: wignerweyl@proton.me
Prizes shall be awarded on January 1st, 2025.
A model for submissions:
As a standard model for submissions, we recommend Yuri Manin's derivation of Zipf's Law [9] as a corollary of Levin's Universal Distribution via the Manin-Marcolli theory of error-correcting codes [10]. The Manin-Marcolli theory for deriving Zipf's Law appears to have important consequences for generative modelling in both humans and machines.
References:
2000. https://arxiv.org/abs/cs/0004001.