Another idea that could be interesting for decision transformers is figuring out what is going on in this paper https://arxiv.org/pdf/2201.12122.pdf
Also I can confirm that at least on the hopper environment training a 1L DT works https://api.wandb.ai/report/victorlf4/jvuntp8l
Maybe it does for the bigger environments haven't tried yet.
https://github.com/victorlf4/decision-transformer-interpretability here's the fork I made of the decision transformer code to save models in case someone else wants to do it to save them some work.
(I used the original codebase because I was already familiar with it from a previous project but maybe its easier to work with the huggingface implementation)
Colab for running the experiments.
https://colab.research.google.com/drive/1D2roRkxXxlhJy0mxA5gVyWipiOj2D9i2?usp=sharing
I plan to look into decision transformers myself at some point but currently I'm looking into algorithm distillation first, and anyway I feel like there should be lots of people trying to figure out these kind of models(and Mechanistic intepretability in general) .
If anyone else is interested feel free to message me about it.
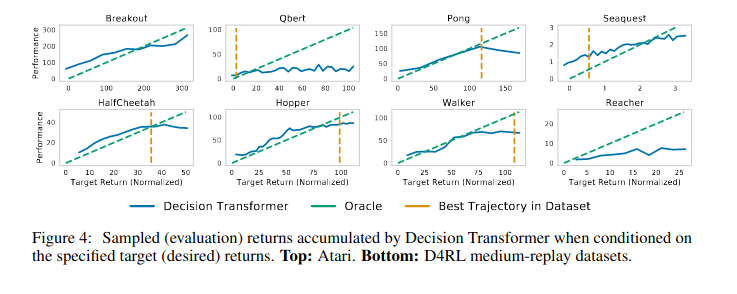
Something to note about decision transformers is that for whatever reason the model seems to generalize well to higher rewards in the sea-quest environment, and figuring out why that is the case and whats different from the other environments might be a cool project.
Also in case more people want to look into these kind of "offline Rl as sequence modeling" models another paper that is similar to decision transformers but noticeably different that people don't seem to talk much about is trajectory transformer https://arxiv.org/abs/2106.02039.
This is a similar setup as DT where you do Offline Rl as sequence modeling but instead of using conditioning on reward_to_go like decision transformers they use beam search on predicted trajectories to find trajectories with high reward, as a kind of "generative planning".
Edit: there's apparently a more recent paper from the trajectory transformer authors https://arxiv.org/abs/2208.10291 where they develop something called TAP(Trajectory Autoencoding Planner) witch is similar to trajectory transformers but using a VQ-VAE.
This is the ninth post in a sequence called 200 Concrete Open Problems in Mechanistic Interpretability. Start here, then read in any order. If you want to learn the basics before you think about open problems, check out my post on getting started. Look up jargon in my Mechanistic Interpretability Explainer
Motivating papers: Acquisition of Chess Knowledge in AlphaZero, Understanding RL Vision
Disclaimer: My area of expertise is language model interpretability, not reinforcement learning. These are fairly uninformed takes and I’m sure I’m missing a lot of context and relevant prior work, but this is hopefully more useful than nothing!
Motivation
Reinforcement learning is the study of how to create agents - models that can act in an environment and form strategies to get high reward. I think there are a lot of deep confusions we have about how RL systems work and how they learn, and that trying to reverse engineer these systems could teach us a lot! Some high-level questions about RL that I’d love to get clarity on:
Further, I think that it’s fairly likely that, whatever AGI looks like, it involves a significant component of RL. And that training human-level and beyond systems to find creative solutions to optimise some reward is particularly likely to result in dangerous behaviour. Eg, where models learn the instrumental goals to seek power or to deceive us, or just more generally learn to represent and pursue sophisticated long term goals and to successfully plan towards these.
But as is, much alignment work here is fairly speculative and high level, or focused on analysing model behaviour and forming inferences. I would love to see this grounded in a richer understanding of what is actually going on inside the system. Some more specific questions around alignment that I’m keen to get clarity on:
A work I find particularly inspiring here is Tom McGrath et al’s work, Acquisition of Chess Knowledge in AlphaZero. They used linear probes to look for which chess concepts were represented within the network (and had the fun addition of having a former world chess champion as co-author, who gave commentary on the model’s opening play!). And they found that, despite AlphaZero being trained with no knowledge of human chess playing, it had re-derived many human chess concepts. Further, by applying their probes during training, they found that many of these concepts arose in a sudden phase transition, and were able to contrast the order of concepts learned to the history of human chess playing. I think this is extremely cool work, and I’d love to see extensions that try to really push on the angle of reverse-engineering and learning from a superhuman system, or on trying to reverse-engineer how some of these concepts are computed.
Overall, I think it’s pretty obvious that making progress reverse-engineering RL would be important! But is it tractable? I find it hard to say - I just haven’t seen that much work on it! I personally expect us to be able to make some progress in reverse-engineering RL, but for it to be even harder than reverse-engineering normal networks. Deep RL systems are, fundamentally, neural networks, and the same kind of techniques should work on them. But there are also a bunch of weirder things about RL, and I don’t know what roadblocks will appear.
In my opinion, the lowest hanging fruit here is to just really grapple with reverse engineering even a simple system trained with RL, and to see how deep an understanding we can get.
Tips
Resources
Problems
This spreadsheet lists each problem in the sequence. You can write down your contact details if you're working on any of them and want collaborators, see any existing work or reach out to other people on there! (thanks to Jay Bailey for making it)