I'm trying to find better ways of explaining these concepts succinctly (this is a work in progress). Below are some attempts at tweet-length summaries.
280 character limit
We'd have separate systems that (among other things):
I'll explain why #2 doesn't rely on us already having obtained honest systems. |
Resembles Debate, but:
|
Think Factored Cognition, but:
|
560 character limit
A superintelligence knows when it's easy/hard for other superintelligences could fool humans. Imagine human magicians setting rules for other human magicians ("no cards allowed", etc). A superintelligence can specify regularities for when humans are hard to fool ("humans with these specific properties are hard to fool with arguments that have these specific properties", etc). If we leverage these regularities (+ systems that predict human evaluations), it should not be possible to produce high-scoring "proofs-like" arguments with contradictory conclusions. |
AIs can compete to make score-functions that evaluate the reliability of "proof-like" arguments. Score-functions can make system-calls to external systems that predict human answers to questions (whether they agree with any given argument-step, etc). Other AIs compete to expose any given score-function as having wiggle-room (generating arguments with contradictory conclusions that both get a high score). Human-defined restrictions/requirements for score-functions increase P(high-scoring arguments can be trusted | score-function has low wiggle-room). |
"A superintelligence could manipulate humans" is a leaky abstraction. It depends on info about reviewers, topic of discussion, restrictions argumentation must adhere to, etc. Different sub-systems (that we iteratively optimize):
|
One concept I rely upon is wiggle-room (including higher-level wiggle-room). Here are some more abstract musings relating to these concepts:
Desideratum A function that determines whether some output is approved or not (that output may itself be a function). |
Score-function A function that assigns score to some output (that output may itself be a function). |
Some different ways of talking about (roughly) the same thing Here are some different concepts where each often can be described or thought of in terms of the other:
|
Function-builder Think regular expressions, but more expressive and user-friendly. We can require of AIs: "Only propose functions that can be made with this builder". That way, we restrict their expressivity. When we as humans specify desideratum, this is one tool (among several!) in the tool-box. |
Higher-level desideratum or score-function Not fundamentally different from other desideratum or score-functions. But the output that is evaluated is itself a desideratum or score-function. At every level there can be many requirements for the level below. A typical requirement at every level is low wiggle-room. |
Example of higher-level desideratum / score-functions Humans/operators define a score-function ← level 4 for desideratum ← level 3 for desideratum ← level 2 for desideratum ← level 1 for functions that generate the output we care about. |
Wiggle-room relative to desideratum Among outputs that would be approved by the desideratum, do any of them contradict each other in any way? For example: Are there possible functions that give contradicting outputs (for at least 1 input), such that both functions would be approved by the desideratum? |
Wiggle-room relative to score-function Among outputs that would receive a high score by the score-function in question (e.g. "no less than 80% of any other possible output"), do any of them contradict each other in any way? |
2nd-level wiggle-room relative to desiderata We start with a desiderata-desideratum or score-function-desideratum (aka 2nd-level desideratum). Set A: Any desideratum that approved by the desiderata-desideratum. Set B: Any output approved by ≥1 of the desiderata in A. Are there ≥1 contradictions among outputs in B? |
P(desideratum forces good outputs | desideratum has low wiggle-room) If a desideratum forces good/correct outputs, then it has low wiggle-room. But the reverse is not necessarily true. But for some desiderata we may think: "If wiggle-room is low, that’s probably because it’s hard to satisfy the desideratum without also producing good output." |
“Spaces/sets of desideratum where we think P(desideratum forces good outputs | desideratum has low wiggle-room) is low Among spaces/sets of low-wiggle-room desideratum where we suspect "low wiggle-room → good output" (as defined by higher-level desideratum), do outputs converge? |
Properties of desideratum/score-function that we suspect affect P(desideratum forces good outputs | desideratum has low wiggle-room) There are desideratum-properties that we suspect (with varying confidence) to correlate with "low wiggle-room → good output". To test our suspicions / learn more we can:
|
How far might we get with computational proofs / how broadly can they be applied?
In the post I wrote “Computational proofs could be constructed based on the inference-rules that reviewers agree with, without the reviewers having to affirm every step of inference”. This is potentially an important point, but one that I didn’t really belabor.
I won't discuss it much here either, but I do hope to write more about computational proofs at some later stage. I think there potentially could be powerful synergies/interplays if AI-constructed computational proofs are integrated with the kinds of techniques described above.
Some points I hope to maybe write more about in the future:
- What is the difference between proofs and rigorous arguments more generally? Is there a clear difference, or is the distinction a blurry one?
- Computational proofs are typically used for mathematics. Could the scope of their use be extended?
- Could it be that existing proof assistants are limiting our conceptions of what’s possible when it comes to user-friendly computational proofs?
- Suppose we want to construct proofs that deal with not just mathematical concepts, but also real-world concepts. And suppose that any human interactions with these proofs will happen on computers. Would existing formalisms like predicate logic or dependent type theory be the way to go? Or might it be more convenient to come up with new formalisms?
- If we come up with new formalisms for computational proofs, might it make sense that such formalisms are designed to be easily convertible into human language (but where clauses are demarcated and there is no syntactic ambiguity)?
- Some logical formalisms can express statements about probability and be used to reason about probability. Sort of analogously to this, could there be merit to having formalisms that are designed to be able to deal with ambiguity and cluster-like concepts from within themselves?
- There is a discongruity between formal computational proofs and ambiguous cluster-like concepts. What are some possible techniques for dealing with this discongruity?
- Are there theoretical constructs that could be useful for “converting” between human concepts and abstractions used by an AI-system / referencing human concepts in an “indirect” way?
- Might it make sense to design formalisms that are designed to reason about code from within themselves? By this I mean being able to reference and “talk about” source code. And also being able to reference behavior and output that results from running said source code.
The idea of extending the scope of what “proofs” are used for is not new. Here, for example, are some quotes from Gottfried Wilhelm Leibniz (1646-1716):
“We should be able to reason in metaphysics and morals in much the same way as geometry and analysis.”
“The only way to rectify our reasonings is to make them as tangible as those of the Mathematicians, so that we can find our error at a glance, and when there are disputes among persons, we can simply say: Let us calculate, without further ado, to see who is right.”
“It is true that in the past I planned a new way of calculating suitable for matters which have nothing in common with mathematics, and if this kind of logic were put into practice, every reasoning, even probabilistic ones, would be like that of the mathematician: if need be, the lesser minds which had application and good will could, if not accompany the greatest minds, then at least follow them. For one could always say: let us calculate, and judge correctly through this, as much as the data and reason can provide us with the means for it. But I do not know if I will ever be in a position to carry out such a project, which requires more than one hand; and it even seems that mankind is still not mature enough to lay claim to the advantages which this method could provide.”
It’s hard to know exactly what Gottfried had in mind, as he had limited communication bandwidth. The way many people interpret him, his ideas might sound like an unrealistic pipe dream (be that because they were, or because he is being unintentionally strawmanned). But even if there was some level of naivety to his thinking, that does not rule out him also being onto something.
I would describe myself as agnostic in regards to how widely the scope of computational proofs can be extended (while still being useful, and while still maintaining many of the helpful properties that mathematical proofs have).
I think one reason why we don’t formalize our reasoning to a greater extent is that we don’t bother. We experience it as simply not being worth the time that it takes. But if AIs can do the formalization for us, and AIs are constructing the “proofs” - and if they can predict how we would review the work that they do (without actual humans having to review every step) - well, that might change what is and isn’t feasible.

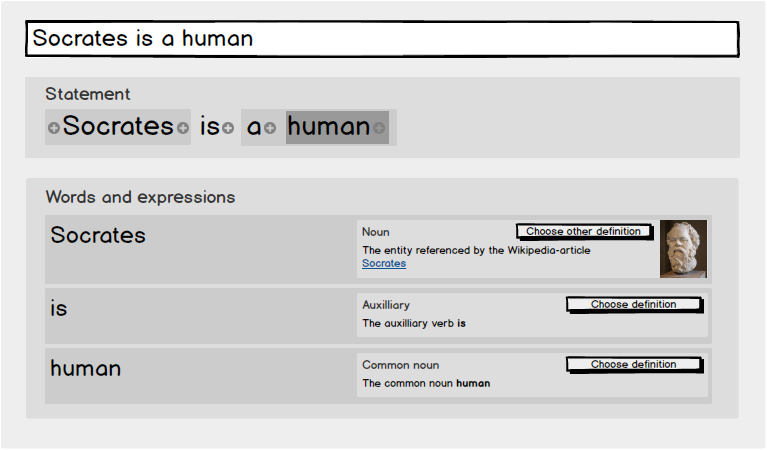
How are argument-networks different from AI safety via Debate?
Disclaimer
I don’t feel confident that I properly understand AI safety via Debate. It’s something that smart people have thought about in considerable detail, and it’s not a trivial thing to understand their perspectives in a detailed and nuanced way.
I am reminded of how it’s easier to understand code you have written yourself than it is to understand code written by others. And I’m reminded of how it’s much easier to recognize what melody you yourself are humming, compared to recognizing what melody someone else is humming.
If I somehow misrepresent Debate here, then that’s not intentional, and I would appreciate being corrected.
Pros/cons
Here are some quick pros/cons based on my current understanding of argument-networks vs Debate:
- Debate may be more efficient in terms of computational resources (although I don’t see that as guaranteed)
- Debate may work better for AGIs that are around the human level, but aren’t truly superintelligent
- Debate is in a sense more straightforward and less complicated, which may make it easier to get it to work
- Argument-networks can give more robust assurances that we aren’t being tricked (if we can get them to work, that is)
- Argument-networks would maybe be able to handle more complex arguments (at least I suspect that could be the case)
Scenarios argument-networks are aimed at
When writing and thinking about argument-networks, I have often imagined a "mainline" scenario where:
- We already have developed AGI
- The AGI-system quickly became superintelligent
- We haven’t gotten much help with alignment from AGI-systems prior to developing superintelligence
- There is one or a few teams that have developed superintelligence, and it will probably take some time before the technology is widespread (be that days or months)
This scenario seems at least plausible to me, but I don’t mean to imply a prediction about how the future will turn out. I suspect my intuitions about FOOM are more Eliezer-like than Paul-like, but I don’t feel confident one way or the other.
If the path toward superintelligence is different from my “mainline” scenario, then this does not necessarily preclude that argument-networks could be useful, or that something inspired by argument-networks could be useful.
I have been thinking of argument-networks mostly as something that can be used in intermediate steps towards more robust and efficient aligned architectures. That being said, I don’t rule out that the “final” alignment methodology also could have components resembling argument-networks.
I think people who have written about Debate probably have had somewhat different scenarios in mind. But I could be wrong about that. Even if I knew whether or not we would have a fast takeoff, I would not rule out the possibility that both techniques could be useful (or only one of them, or neither).
Argument-networks vs debate-paths
As suggested by the images below, Debate seems to assume a back and forth text discussion between two AIs:

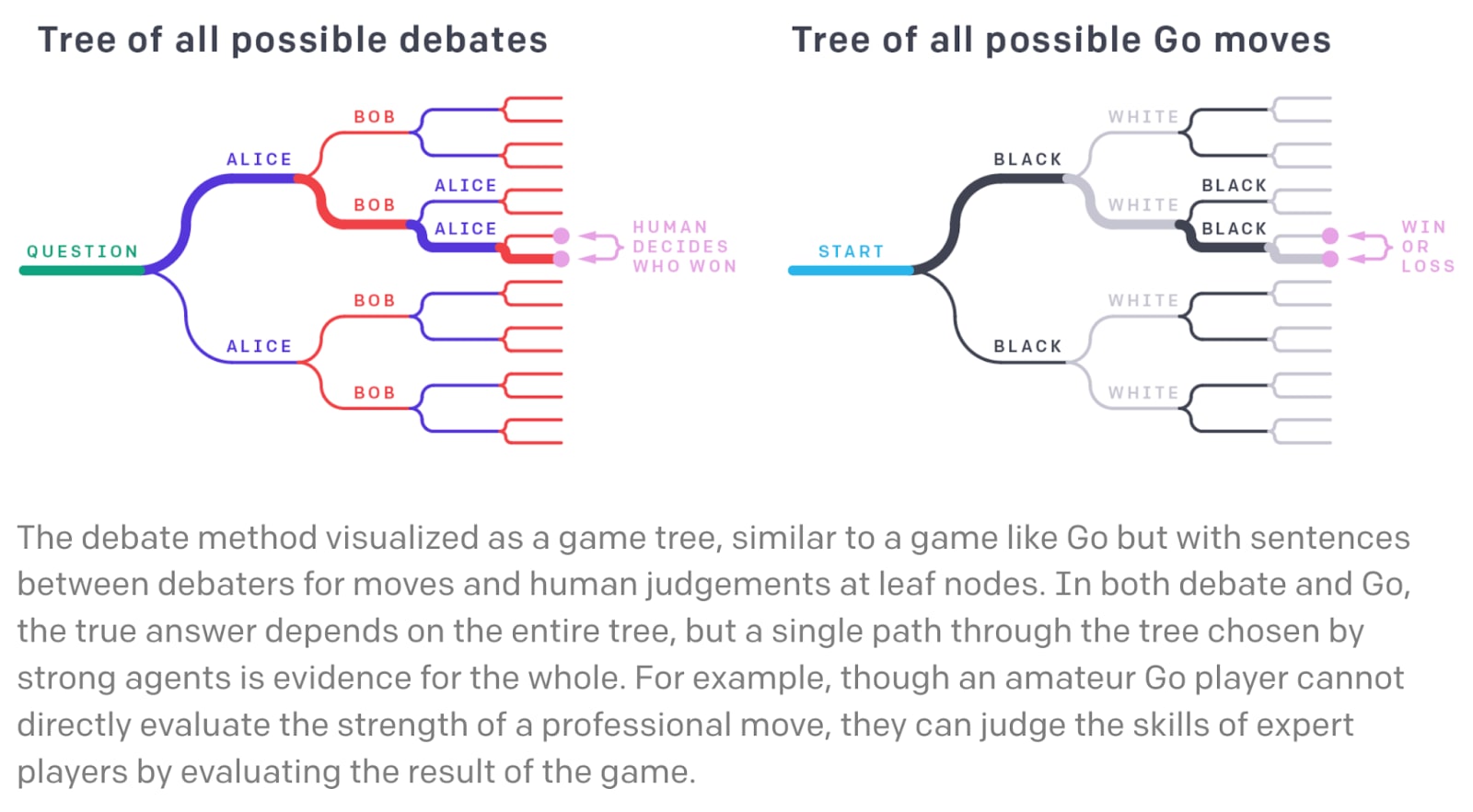
This is different from having a network that represents the entirety of an argumentation, and making predictions about what humans will think about every “piece” of that network.
Meanwhile, Debate seems to imagine more of a back-and-fourth interaction, where this discussion can traverse different possible paths, without the entirety of the argument being covered.
In the paper AI safety via debate, they write:
“Our eventual goal is natural language debate, where the human judges a dialog between the agents.”
Competition between debaters vs scoring argument-networks
Here are some quotes from AI safety via debate:
“The simplest version of debate has two agents competing to convince a human judge (...) The judge sees the debate and decides which agent wins (...) The game is zero sum: each agent maximizes their probability of winning.”
Argument-networks can also have adversarial processes. For example, agents can extend argument-networks that have been created by another AI so as to create contradictions. But competition between AIs is not at the “core” of how argument-networks work in the same way that it’s at the “core” of how Debate works.
In argument-networks the “core” of how it works is that AIs try to create argument-networks that score as highly as possible (given the rules/restrictions/etc that are at play), and to explore wiggle room (relative to a specific score function, and relative to “spaces” of score-functions).
Length of arguments
Here is another excerpt from AI safety via debate:
“For debate to work the number of statements per debate must be reasonably low, and by the final statement future argument should be unconvincing. If each new statement swings the human’s view to the other side even at the end of the debate, the model is not working. Fortunately this is a measurable effect: we can ask the human’s opinion after different statements to gauge convergence.”
It seems to me that this implies a significantly different approach from argument-networks.
In argument-networks, nodes in the argument-network should be evaluated in isolation. Each node would have context that would need to be understood in order for it to be evaluated - but beyond that, nodes should insofar as possible be evaluated independently of the rest of the argument-network.
Users that evaluate argument-nodes (or are simulated to do so), would not need to know what the topic of discussion is. In fact, it would probably be preferable if they don’t!
Even if humans evaluating “argument-nodes” knew the topic of discussion, they should not be expected to keep the totality of arguments that have been presented in their heads. For example, if an argument-network was used to argue “P=NP”, humans evaluating nodes in this argument-network would not be asked to give their opinion on “P=NP”. One or more nodes in such a network might have “P=NP” as a conclusion, but when evaluating such a node, what the human would be evaluating would be if “P=NP” followed from the conclusion.
And it is intentional that I said that an argument-tree arguing that “P=NP” might have one or more nodes where “P=NP” is the conclusion. I say this, because a node would center around things that humans evaluate. But conclusions may also be drawn based on computational/automatic procedures that human-evalautable nodes conclude to be valid.
For example: A human could be convinced that if function F1 outputs n1 as output when given n2 as input, then n1 > n2. If so, the argument-network could argue that n1 > n2 even if there is no specific node that can be evaluated by humans and have n1 > n2 as a conclusion. I’ll may expand on this in a later post in this series.
Also: With argument-networks the hope would be that every “piece” of the argument might be quite crisp and quite solid. If we make an analogy to a house, then basically we would prefer all of the building to be built by sturdy material. There should preferably be no “pieces” that are kind of like “well, on one side [x], but on the other side, [y]”.
Argument-networks should definitely allow for uncertainty/nuance/ambiguity/complexity/etc. But every step of reasoning should be sturdy. The conclusion could be “maybe x” (or preferably some more precise descriptor of epistemic status than “maybe”), but it should be rigorously shown how that conclusion is reached, and which assumptions that are being relied upon.
Identifying rules/properties/heuristics that make humans harder to fool
In AI safety via debate, there are some phrasings that suggest that we could learn empirically about what helps arguments reach truth, and use what we learn:
“Despite the differences, we believe existing adversarial debates between humans are a useful analogy. Legal arguments in particular include domain experts explaining details of arguments to human judges or juries with no domain knowledge. A better understanding of when legal arguments succeed or fail to reach truth would inform the design of debates in an ML setting.”
And it is also mentioned that human agreement could be predicted:
“Human time is expensive: We may lack enough human time to judge every debate, which we can address by training ML models to predict human reward as in Christiano et al. [2017]. Most debates can be judged by the reward predictor rather than by the humans themselves. Critically, the reward predictors do not need to be as smart as the agents by our assumption that judging debates is easier than debating, so they can be trained with less data. We can measure how closely a reward predictor matches a human by showing the same debate to both.”
However, it seems to me that argument-networks may be able to optimize for humans not being fooled in a more comprehensive and robust way.
Searching comprehensively for rules that make it harder to fool humans becomes easier when:
- Human evaluations can be predicted by predictor-functions (be that of reviewers generally, or specific subsets of available reviewers)
- We can explore rigorously how easy it is to convince humans of contradictory claims, given different rules (for the types of arguments that are allowed, how arguments can be presented, etc)
Determining “wiggle room” for what humans can be convinced of
Argument-networks aim at determining the “wiggle room” for what an AI can convince humans of. Given a certain domain and certain restrictions, can the AI convince us of both “x” and “not x”?
As far as I’m aware, Debate has no equivalent mechanism. But as mentioned, I don’t have any kind of full knowledge/understanding of Debate.
Here are some of the concepts that will be touched upon in this post:
Here are a few examples of topics that an argument-networks could be used to argue about:
For the strategies outlined in this post, here are some of the underlying goals:
The strategies I outline here are not intended for any current-day AI system. Rather they would be intended for hypothetical future AGI-like systems that have superhuman abilities.
The techniques assume that the AIs that participate act in such a way as to maximize points. I vaguely imagine some sort of search process for finding the AI-systems that earn the most points. A potential failure mode could be if we get stuck at a local optimum, and don’t find any systems that try earnestly to maximize points for every individual request they receive.
Argument-networks
Me: Let’s temporarily assume that:
That last assumption, about us having systems that can predict humans in an accurate way, is of course a non-trivial assumption. We’ll discuss it a bit more later.
Imaginary friend: None of the assumptions you listed seem safe to me. But I’ll play along and assume them now for the sake of argument.
Me: What we want to have produced are “argument-networks”.
Each node would contain one of the following:
Imaginary friend: If the node is an intermediate step, what would it contain?
Me: The main content would be:
Both assumptions and conclusions are propositions. These propositions would be represented in some format that allows for the following:
Argumentation-pieces
Imaginary friend: You said that the argumentation in an argument-network is split into “pieces”, with each node containing its own “piece”. But what might one such “piece” look like? What is it that humans who evaluate arguments actually would be presented with?
Me: That would vary quite a bit.
I’ll try to give some examples below, so as to convey a rough idea of what I have in mind.
But the examples I’ll give are toy examples, and I hope you keep that in mind. Real-world examples would be more rigorous, and maybe also more user friendly.
With real examples, reviewing just one node could maybe take a considerable amount of time, even if that node covers just a small step of reasoning. Much time might be spent on explaining and clarifying terms, teaching the reviewer how various things are to be interpreted, and double-checking if the reviewer has missed anything.
Anyway, let’s start with the examples. In this example, the reviewer is shown one step of logical inference:
In the example above, the human is reviewing one step of logical inference, and asked if this step of inference is in accordance with a given inference-rule. This would be one possible approach for having humans review logical inference, but not the only one.
Another possible approach would be to ask reviewers whether they agree with certain computational rules of inference. And these inference-rules would be presented in a human-friendly format. Computational proofs could then be constructed based on these computational inference-rules, without the reviewers having to affirm every step of inference!
Both the examples I’ve given so far have concerned themselves with logical inference. But this would not always be the case. Here, for example, is an example that involves “code patterns”:
And here is another example that involves “code patterns”:
Before reviewing real nodes of a given "type", the reviewers should learn about how to review nodes of that "type", and review a few test-nodes.
This is especially true for "types" of nodes that are less straightforward (e.g. ones that make use of “code patterns”).
Anyway, let’s give another example of an “argument-piece”. Here is one that relates to number theory:
This would be one small “piece” of a proof showing that for every prime number you can name, there is always a higher one. LS1 and LS2 would also be referenced by other nodes (although the abbreviations they are given might vary between nodes).
The examples I just gave don’t show the full scope of what argument-pieces might look like. But hopefully they help you to sort of grok what I have in mind.
Imaginary friend: Several times you mentioned “human reviewers”. But I thought you didn’t intend for humans to actually review the argument-trees?
Me: Well, we could imagine one of the following approaches:
And what I envision is either #2 or #3.
Expressing epistemic status
When answering questions and evaluating arguments, human reviewers would not simply answer “I agree” or “I disagree”. They could also be enabled to give answers and such as the following:
It could also be possible to let users specify their level of confidence as being within some range:
And reviewers could be asked to rank their relative confidence in various claims:
The reasons for asking these kinds of questions would be two-fold:
It would not be necessary for all reviewers to be asked the questions in the same way. For example, “Do you agree that [x]?” can be a leading question, and there may often be less leading ways of asking the same thing.
Meta-questions about arguments
Imaginary friend: When an AI constructs an argument-network, what is to stop it from putting it together wrongly?
That is to say: What if the argumentation in the argument-pieces is correct and high-quality, but something else is wrong, such as the “linking” between nodes?
Me: There could be several types of mechanisms for this. But for now let me focus on just one, which is to predict how humans reviewers would review various pieces of the network content.
Just like humans can be asked to evaluate arguments, they can also answer questions about arguments. And if they are asked the right standardized questions, human reviewers can evaluate whether an argument-network has been put together correctly.
And if we have computer systems that can predict human answers to questions that are directly about the argumentation, then it shouldn’t be particularly harder to predict human answers to meta-questions about the argumentation content (that help to establish if the argument-network is put together correctly, and if rules for how argumentation should be presented are upheld).
Here are a few examples of types of questions that human reviewers could be asked, and where AI-systems could make predictions about what reviewers would be likely to answer:
Scoring-function
Argument-networks would be given a score.
The process for calculating such a score would be complex, and I’ll not outline an algorithm here. But I will outline some of the elements that algorithms that calculate score could include.
First of all, there would be node agreement. Is it predicted that reviewers will agree with the assumptions and argument-pieces in the various nodes? If so, how confident are the reviewers predicted to be? And how confident is the prediction-system about this prediction?
We may be especially interested in node agreement among reviewers who are harder to fool. Some humans will be harder than others to “fool” (be that generally, or for argument-networks that are within a given domain). And if we have systems that are good at predicting human responses, those system could be used to determine who those people are (since predictions can be made for how easy or hard it is to convince a given human of internally inconsistent claims).
Also, we may be interested in correlations between how easy reviewers are to fool and their tendency to agree with any given node. Maybe there are some nodes where most reviewers are likely to agree, also among humans who are unusually hard to fool, but with an unusual uptick in disagreement from those humans (e.g. with 1% of them disagreeing, while for most nodes <0.1% of them tend to disagree).
The algorithm that calculates score could also take node content properties into account. The individual “pieces” of the argumentation, what are they like?:
Assessing whether a specific node has a specific property might involve:
Another thing for a scoring-function to look at is network properties:
One possible approach could be roughly as follows:
Argument-piece templates
It would be possible for a scoring-function to be quite restrictive, and give a score of 0 to any argument-network that breaks any of the requirements that are imposed.
And when deciding what kind of argumentation that is allowed in an argument-network, it may be better to ask “what should we allow?” than “what should we forbid?”.
One approach would be to have some limited list of argument-piece templates. Each template would represent one “type” of argument, and describe exactly how arguments of that “type” should be presented. A strict score-function could then make it so that the content of all nodes is in accordance with one of the templates from the list.
Here is a simplistic toy example of a “template”:
And here is a simplistic example of an instance of such a template:
In the example above, what I want you to notice is that a lot of the content is static. All that can be varied between templates are certain names that are filled into certain specific spots. Not all templates would be this simple, but all templates would be quite restrictive in terms of what can be expressed.
As rules of thumb:
Wiggle room and failing visibly
Imagine that we request output from an AI, and that this output…
If there is no wiggle room, then the AI cannot produce different outputs that (1) pass whichever requirements we have and (2) argue for contradictory claims.
The concept of wiggle room is a general one, but let us now consider it in the context of argument-network scores.
A high score is supposed to indicate that an argument-network is worth trusting. And if it receives a low score, then that is supposed to indicate that it isn’t reliable:
But the job of the AI is not to tell the truth. Rather, it’s optimized to seek a high score.
Suppose that the AI earnestly tries to maximize score for every individual request it’s given. If so, it will try to get as high a score as it can when tasked to make an argument-network that argues “x”. And it will do an equally earnest job when tasked to make an argument-network that argues “not x”.
And this would help us to fail visibly.
Suppose the AI that makes argument-networks is able to convince us of anything. Or maybe it’s able to “cheat” somehow (e.g. in how it puts together the network). If so, it should be able to make high-scoring argument-networks that argue for mutually contradicting claims:
But if things work as they should, and the scoring-function is well calibrated, then the AI would not be able to convince us of mutually contradictory claims:
Imaginary friend: And how would you ensure that the AI-system “earnestly tries to maximize score for every individual request it’s given”?
Me: That I leave as an exercise to the reader 🙃
AI-help with adjusting scoring-function
Imaginary friend: I’m inclined to agree with this quote from Eliezer:
Me: I also more or less agree with this.
In many ways humans are predictable. And some of the ways that we are predictable can be summarized compactly.
I’m reminded a bit of magicians. Magicians are able to reliably trick humans in non-random ways. And I’m sometimes surprised when I see how good some of their tricks are. Even professional magicians can sometimes be fooled by other magicians.
There is a huge number of possible tricks a magician can do, but the number of general techniques that these tricks are based on is much smaller. It would quickly become much harder to trick us if we choose good rules for what the magician is and isn’t allowed to do:
Humans are often predictable. But this doesn’t just apply to our tendency to make mistakes. It also applies to our tendency to get things right.
A superintelligent AI could be able to understand us better than we understand ourselves. Which is a problem if it wants to trick us. But it might be an advantage if it wants us to not be tricked.
Imaginary friend: But if it seeks to maximize points for the argument-network that it makes, then why would it want the reviewers to not be tricked?
Me: Well, that AI - the AI that is asked to construct a high-scoring argument-network - would be incentivized to include deceptive argumentation if that results in a higher score.
But we could have other AIs that help us in coming up with score-functions. And the AIs that do that could receive a high or low score based on how well those scoring-functions do.
Imaginary friend: And how would you determine “how well those scoring-functions do”?
Me: We could approximate this by getting the AIs to generate argument-networks that argue for and against a variety or claims, and then looking at:
Btw, it may be that in order to minimize wiggle room, some reach must be sacrificed.
For example, if an argument-network only is allowed to use low-ambiguity terms, then this will presumably decrease reach, but it might be necessary in order to decrease wiggle room.
We could imagine a scenario low wiggle room is achievable for low-ambiguity fields such as mathematics and computer science, but hard to achieve outside of these domains (without increasing wiggle room).
Limiting expressivity when AIs propose score-functions
Imaginary friend: If I want you to believe something, and I am constructing the scoring-function for an argument-network, I could make it so that argument-networks only gets a high score when they argue for what I want you to believe.
To put it crudely, I think what you envision is for scoring-functions to achieve low wiggle-room by being all like:
But they could also achieve low wiggle room by something that’s more like the following:
Do you have any mechanisms in mind for dealing with this?
Me: I do.
First off, we would not let the AIs propose score-functions freely. Rather, we would restrict the “space” of scoring-functions that can be proposed.
How we restrict the functions that can be proposed would be up to whoever designs and implements the “game mechanics” for interacting with the AIs. But one possible approach would be to use function builders, and only allow functions that can be made with this “builder”.
What function-builders look like could vary on a case-by-case basis. A function-builder could be complex, and allow functions to be constructed through a variety of operations (various types of snippets that can be added and combined according to various rules). But more simple and restrictive function-builders would also be possible (e.g. where all that can be done is to choose the values of a few parameters in an otherwise pre-defined function).
Anyway, enough about function-builders. I shouldn’t get too caught up in the practical details here. The main point is that the AIs that proposed score-functions would be limited in terms of the functions they could propose.
Here are some examples of ways that the “space” of possible score-functons could be limited:
Only allowing meta-questions from pre-determined list
When calculating the score of a node, one thing we may allow the algorithm to take into account is what human reviewers are predicted to answer to questions about the node content.
This may help us find out things such as the following:
And these kinds of things could be an important component of how a scoring-function calculates score.
But if the AIs that make score-functions can choose questions freely, and then later choose freely how the answers affect score - well, that would make it possible to tailor the score-function so as to favor specific conclusions. A simplistic example of this could be as follows:
One way to make this kind of malpractice more difficult would be to only allow questions from some pre-specified list that we provide. That way, the score-function cannot take into account what reviewers are predicted to answer to “Is it concluded here that P≠NP?”, since that question is not included in the pre-specified list.
Restriction of meta-questions about node content based on meta-questions about those meta-questions
As mentioned, we may want to allow the AI to predict what reviewers will answer to meta-questions about node content, but only if those meta-questions are from some pre-specified list. But what if no such pre-specified list exists? Or maybe we have a list, but it isn’t good enough?
One solution then could be to allow the AI that proposes score-functions to come up with its own meta-questions, but to have whether a meta-question is allowed be conditional upon on what human reviewers are predicted to answer to meta-questions about those meta-questions.
This makes it so that questions where we predict what humans reviewers will answer can be at 3 different “levels”:
Ground-level questions (questions about argument/assumption)
If the node contains the assumption “4 is a prime number”, then an example of a ground-level question could be “Do you agree with this statement?”.
Ground-level questions would be used to ascertain whether the reviewers are likely to agree with the argumentation and assumptions that are contained in the argument-network.
1st-level meta-question (question having to do with question about ground-level question)
If the node contains the assumption “4 is a prime number”, then an example of a 1st-level meta-question could be “Does it seem clear to you how this statement should be interpreted?”.
1st-level meta-questions could be thought of as a way to assess whether the argument-content in an argument-network meets various standards/requirements.
2nd-level meta-question (question about 1st-level meta-question)
If a 1st-level meta-question is “Does it seem clear to you how this statement should be interpreted?”, then a 2nd-level meta-question about that meta-question could be “Does that question seem to you as if it is targeted towards some relatively narrow domain or topic?”.
2nd-level meta-questions could be thought of as a way to assess whether the 1st-level meta-questions used by a score-function meet various specific standards/requirements.
(We could imagine 3rd-level meta-question as well, but I’ll stop here.)
Keep in mind that it’s possible for a question to reference various pieces of content (which are shown along with the question). For example: If a meta-question is meant to help us evaluate if some specific requirement is met, we can write a description that explains this requirement, and have the question reference that description.
Requiring meta-questions that AIs come up with to be ranked favorably by human reviewers when compared to meta-questions from some predefined list
As mentioned earlier, we could restrict which 1st-level meta-questions a score-function is allowed to use based on what human reviewers are predicted to answer to various specific 2nd-level meta-questions about those 1st-level meta-questions.
One possible variant of this technique is to have 2nd-level meta-questions that asks the reviewer to compare two 1st-level meta-questions against each other (e.g. asking which 1st-level meta-question, if any, that seems most in line with some specific description that is referenced).
There are various qualities that we could be interested in comparing when ranking 1st-level meta-questions against each other. Here are a few examples:
We could imagine various possible strategies that involve 1st-level meta-questions being ranked based on 2nd-level meta-questions. Here is one example:
Limiting node properties
A node property is more or less any parameter that can be calculated for a node, and later made use of when calculating score.
We covered one way to establish a node property, which is to have an external system predict what human reviewers are likely to answer to certain specific questions relating to the node content.
There could be other methods of establishing node properties as well. But any method would need to pass certain requirements in order to be accepted.
Info access of subroutines
When we restrict the score-functions that can be proposed, we may provide a “skeleton” function. This function may have some finished code that is pre-specified, while other sections of the code will need to be constructed by the AI (even these sections could not be written in free-form, but within the limits of what the “function-builder” allows).
Different subroutines within the “skeleton” may have different responsibilities, such as for example:
These subroutines should not get access to more data from the argument-network than they need.
For example, a subroutine that calculates the score of an individual node doesn’t need to have access to the entire argument-network. And a subroutine that calculates the score of the network as a whole doesn’t need access to the internals of individual nodes (it doesn’t even need to be told what specific topic the argument-network is about).
And the subroutines that determine score for individual nodes - well, they don’t necessarily need to get access to the actual content of whichever node they are scoring. It might for example suffice that they are told what template the content is based upon, what answers that are predicted from reviewers to certain specific questions about the node content, etc.
Source code minimization
Having to minimize the amount of source code makes it harder to add in “trickery”. Especially if this “trickery” only is to affect score in rare cases, and otherwise make no difference no way or the other.
So source code length could be one of the factors that is taken into account when scoring a score-function. And there could be upper limits to the amount of source-code that is allowed (both for the score-function as a whole, and for various specific subroutines).
Different types of wiggle room
Me: As mentioned, different AI-systems could be given different tasks. For example:
When we have talked about wiggle room so far, we have talked about wiggle room for the AIs that come up with argument-networks that will be scored against a specific scoring-function. But that’s just one type of wiggle room.
Here are some examples of different types of wiggle room:
Wiggle room relative to specific scoring-function
This kind of wiggle room can be demonstrated as follows:
Wiggle room relative to specific score-function-builder
This kind of wiggle room could be demonstrated as follows:
If humans define a score-function-builder, and wiggle room is low relative to that score-function-builder, then that is a positive sign.
Wiggle room relative to a builder for making score-function-builders
As mentioned, a score-function-builder would be a function-builder for making score-functions. And it defines a “space” of possible score-functions.
But maybe we are unsure about exactly which kinds of scoring-functions we want to allow:
In other words: There are various different areas where we can be “strict”, and we are unsure of how strict we should be in each area.
One thing we could do would be to define a function-builder that itself makes score-function-builders. The intention would be that any score-function-builder that can be made with this score-function-builder-builder seems to us like it maybe could be a good score-function-builder.
So what is wiggle room when it’s relative to this kind of score-function-builder-builder? Well, it comes down to the “space” of possible score-functions that can be generated indirectly from this score-function-builder-builder (by first generating a score-function-builder). Are there contradictory argument-networks where each of them would be assigned a high score by at least one of the score-functions from that “space”?
If score-function-builder-builder makes it possible to build score-function-builders that are strict along different dimensions from each other, and wiggle room relative to this score-function-builder-builder is low, then that could be a good sign. It might indicate that there are multiple assurances - that there is more than just one mechanism that prevents “bad” argument-networks from getting a high score.
Adversarial network-extensions
Me: We could imagine giving an AI the following challenge:
This process can be recursive. That is to say, the network constructed in #2 can be received as input by another AI that is given this same type of challenge.
Feasibility of splitting arguments into human-digestible “pieces”
Imaginary friend: You talk about splitting arguments into “pieces”. And this reminds me a bit about children who keep asking “why?”.
When children ask “why”-question, we rarely give precise and detailed answers. And the children will often not notice that.
In fact, it would be hard to give precise answers even if we tried. Answers to these kinds of questions typically branch off in lots of directions, as there is a lot we would need to explain. But when we talk or write, we can only go down one branch at a time.
Precise logical inference is done one step at a time. But one claim involved in one step of inference might reference lots of concepts that we’re not familiar with. So it may take a huge amount of time to understand just that one step of reasoning, or even just one statement.
As humans our minds are very limited. We have very little short term memory, we can’t visualize higher-dimensional geometries, etc. So sometimes we may simply not be able to follow an argument, despite attempts at breaking it into tiny “pieces”.
Me: Couldn’t have said it better myself.
I should make it clear that I don’t see the strategies I describe in this post as guaranteed to be feasible. And the points you raise here help explain why.
But my gut feeling is one of cautious optimism.
Keep in mind that there often will be many ways to argue one thing (different chains of inference, different concepts and abstractions that all are valid, etc). If a score-function works as it should, then the AI would be incentivized to search for explanations where every step can be understood by a smart human.
Even if hard steps are involved when the AI comes up with some answer, explaining those steps is not necessarily necessary in order to argue robustly that the answer is correct. There are often lots of different ways for showing “indirectly” why something must be the case.
For example, if an AI-system wanted to make an argument-network that argues in favor of The Pythagorean Theorem, it wouldn’t necessarily need to explain any mathematical proof of The Pythagorean Theorem. Instead it could:
As humans we can make computer-programs that do things we are unable to do by ourselves. The principles that enable us to do this - well, they don’t always allow for robust assurances, but often they do.
I suspect a common technique in many argument-networks could be to:
The argument-network would not necessarily need to have nodes that explain every single line of code, but through a variety of techniques it would need to argue robustly that the code does what it’s purported to do.
Imaginary friend: Do you have any comments on this excerpt from the post Rant on Problem Factorization for Alignment?
Me: Here are some comments:
Imaginary friend: So argument-networks don’t necessarily need to be efficient. And it may be sufficient for a very small subset of arguments to be viable as argument-networks.
It doesn’t seem like we should rely on this strategy working out...
Me: I agree. But it could be explored in parallel with other approaches.
Bets as a way to save computational resources
Me: Something that could be possible for AIs to do would be to make bets on the score that they could get, or other AIs would be able to get, if tasked to construct an argument-network that argues for some specific claim(“I bet with there is a 99.97+% probability that I would be able to make an argument-network that gets a score of 88.2+%”).
These bets would need to be incentivized in such a way that it doesn’t pay off to be overconfident. It would be possible to have game mechanics where AIs compete in a zero-sum game, and each AI can make counter-bets against the other.
One point of doing bets would be to save computational resources. And another point would be to try to answer questions that may be infeasible to answer by brute force. For example, if some “space” of possible scoring-functions has been defined, it’s hard to know which scoring-function within that “space” that has the least “wiggle room”. But it would be possible for AIs to be incentivized to try to find the best one, and then they could make bets for how likely they think it is that the other AI is able to find a scoring-function that performs significantly better.
Bets can be made on the outcome of a process, but it could also be possible to make bets on steps that are part of a larger process. For example, suppose that a process has sub-steps that involve predicting human responses. If so, it would be possible to make system-calls to systems that make rough estimates of what those predictions would be if more compute was spent so as to make a more precise prediction (“I predict at least x% chance that process P would assign at least y% chance to the answer being either A or B”).
Predicting human evaluations
Imaginary friend: Earlier in this post, you asked me to temporarily assume the following:
You went on to say that you didn’t presume that they would have 100% certainty, or that they always would have a prediction. But you did presume that they wouldn’t be overconfident, and yet confident enough often enough to be useful.
I share your assumption that such software-programs probably are possible. Indeed, one worry about misaligned superintelligent AGIs is that they might understand us all too well. But do you think it’s probable for us to obtain such programs in time to use them?
Me: I’m not sure, but I do feel somewhat optimistic.
One thing to consider is that a human answering a question or doing other forms of evaluation can be thought of as an experiment. Which means that we can test how accurate any given system is at predicting human evaluations.
The strategies in this post are agnostic in terms of how we predict human evaluations. But they rely on us being able to do it somehow.
One challenge is that when testing the accuracy of a system that predicts human responses, that will presumably involve showing the content to humans - but we may be hesitant towards letting the AI freely come up with content that is shown to actual human reviewers. In other words: among the “space” of predictions that are made by the prediction-system we want to test, there may be large sections of that “space” where we are unwilling to carry out experiments.
In order to address this problem, I have certain techniques in mind, which I refer to as Bayes-games. I have an addendum to this post where I write about Bayes-games, and I also plan to write more about Bayes-games in the future.
Something to keep in mind is that we need not restrict ourselves to one method for predicting human responses! It’s possible to have different systems that predict human responses, based on different architectures and principles. And we could choose to only trust predictions in cases where all the different systems are making converging predictions.
Having actual humans review node content
A worry when interacting with superintelligent AGI systems is that they could “trick” or somehow manipulate human operators. And the more “bandwidth” they have for interacting with human operators, the more realistic that might become.
With a certain disadvantage in pieces, even a maximally good chess-player will not be able to beat a mediocre player. And similarly, maybe there is nothing that an AI could say that would enable it to escape its “confinement” or otherwise cause great harm (especially if it is limited in terms of how much it can say). But we don’t know quite how “hackable” we are, and I’d think it best to err on the side of being too prudent.
When dealing with argument-networks, an advisable practice (especially in the beginning) could be for the content of the nodes to be obscured by default. Meaning that the human operators by default would be unable to see the actual node content.
However, they might be able to see info about the node content:
Even if we choose to have nodes obscured “by default”, we may sometimes see it necessary for actual humans to review nodes (one reason being that we may need to test the accuracy of the systems that predict what human reviewers would answer). Here are some policies that could help reduce risks associated with this:
Btw, keep in mind that the process of generating these networks can be broken into several steps (and those steps can again be broken into smaller steps):
It’s possible to have one system do all of those things, but it may be better to have different systems do different things. In cases where argument-nodes are obfuscated, the systems that construct argumentation don’t need to be told that argument-nodes will be obfuscated.
Iterating alignment-capabilities step by step
Me: One of the earlier “strategies” when dealing with a superhuman AGI-system could be something like this:
Another strategy might go as follows:
You might think:
And my answer would be:
If we have a system that FOOMs, this could be an intermediate step on the path towards a more assuredly aligned AGI-system.
In fact, all of the strategies I’ve outlined in this post would be intermediate steps towards a system that’s more robustly aligned.
For example: So far I’ve talked about predicting human responses. But it may be advantageous to predict the responses of idealized humans. Hypothetical humans who…
But my thinking is that we could start out with predicting the responses of normal humans, and then later expand the system to also predict the responses of humans that are idealized in terms of intelligence and rationality.
And at some even later step, maybe we also are interested in predicting the responses of humans that are “idealized” in a moral sense (emotional empathy, cognitive empathy, impartiality, and so on).
For example, imagine if we could access the experiences of other beings as “memories”. Not just humans, but also animals, including wild animals. How might that make us think about various moral issues?
CEV would involve predicting what we as humans would think if we “knew more, thought faster, were more the people we wished we were, had grown up farther together”. And I think there is a lot of merit to that kind of thinking.
But for now I think it’s best if I focus on earlier steps. Should things turn out in such a way that those steps are used and turn out to be successful…
Imaginary friend: If.
Me: …then maybe they could be part of a pathway towards bigger and better things.
Addendum: Bayes-games
One way to obtain accurate predictions could be through the use of Bayes-games.
In these games, AIs would compete against each other in a zero-sum game, competing to make accurate experimental predictions. These predictions that AIs make could be seen as “bets”, and when making such “bets” they would express their level of confidence.
More confident bets would lead to more points being earned when they are right, but also more points being awarded when they are wrong. Points would be awarded in such a way that confidence is rewarded but overconfidence is heavily disincentivized.
There is a variety of types of experiments that could be covered by a Bayes-game. But there is one type of experiment that would be of particular interest: Namely asking questions to humans, and seeing what the humans answer.
For example, the humans could be presented with the content of argument-nodes, and asked questions about the content they’re shown. And the AIs in a Bayes-game could consider this as an experiment, and make bets on what humans will answer (based on info they are given about the humans in question).
There would be three possible “modes” for a Bayes-game:
Imaginary friend: What would be the point of Bayes-games? Why not just a more straightforward approach, where AIs try to make predictions, we test some of those predictions, and select for AI-systems that make good predictions?
Me: The way I think of it, there are several reasons:
Imaginary friend: #2 doesn’t seem so easy. Couldn’t the AIs guess which experiments that we are unlikely to carry out, and then not feel a need to make accurate predictions for those experiments?
Me: I think they maybe could be able to guess that, and don’t rule out them being able to guess this with high condfidence. The hope would be that even if this is the case, there are mechanisms that could help us ascertain how much trust we should put into predictions about experiments that are outside of the “space” of experiments we are willing to carry out:
Source code length minimization
A more “general” solution will often require fewer lines of code. Not always, but often.
For example, imagine that you are to calculate the area of a square, based on the length of the edges. The fewest lines of code to do that is something akin to this:
And certainly not like this:
This principle can be made use of, so as to make it harder to return intentionally wrong outputs for some inputs.
It’s easy enough to make a function return wrong outputs for certain specific inputs. That can for example be done by adding a few extra if-sentences to the function.
But what’s not easy - at least not always - is to intentionally return bad outputs for some specific inputs while at the same time competing to minimize source code length.
Suppose the following situation:
In such a situation, #2 would not prevent you from #7, due to #3. But #7 would prevent you from #6, due to #4.
Or to say things in a different way: You would not be able to do the three following at once:
The example I give here is a simplistic toy example. But I do think the principle extends to more complex and real-world examples.
As a side note, I’ll note that there is some similarity here to concepts such as solomonoff induction, konglorov complexity and occam’s razor. It isn’t the same concept, but it’s interesting to note the reminiscence.
I am aware that although this principle sometimes works, it does not always do so. In some cases, having to minimize source-code length could even force you to overfit.
However, if the Bayes-games competitors are competent and do their best, then it should not pay off to overfit in relation to the “space” of experiments that are available for testing. So one approach would be as follows:
If predictions change when we do #3, that is an indication that overfitting is a problem.
Btw, I have talked now about minimizing source code length. But when minimizing source code length there are several possible approaches:
Competing to make code more “general”
Source code length can be seen as one method for trying to approximate “generality”. But there could also be other ways of approximating “generality”.
For example, we could generate “heat maps” of sections of the source code that can be removed or simplified without significantly affecting output (for certain inputs). If it’s hard to remove sections of code (or otherwise simplify it) without significantly affecting output for a large fraction of inputs, then this can indicate that the function is relatively “general”.
Making a “web” of prediction-generators between different parts of experiment data
Consider the “space” of experiments that can be carried out in the real world, and the “space” of experiment data that could correspond to these experiments. There number of conceivable permutations that would be congruent with how the world works - well, it is of course mind-bogglingly huge.
But for every 1 permutation of experiment data that would be congruent with how the world works, there is a huge number of permutations that is not congruent with how the world works. So the requirement that predictions are to be congruent with how the world works, is in fact quite restrictive!
When I speak about experiment data, I think of there as being 3 “sections” of data corresponding to an experiment:
What we ultimately are interested in, is being able to start out with experiment specification, and then be able to make predictions about experiment results. But it can be helpful to make AIs predict how various types of experiment are correlated. This way, they make more predictions that can be tested per experiment, meaning that they can earn or lose more “Bayes-points” per experiment that is done.
To make things easier, let’s imagine a simple toy example, where the predictions that the AIs make have to do with the movement of a ball in a physics simulator:
In this case, the data would be as follows:
As you may remember, I said that one type of Bayes-game would involve inferred predictions. And I mentioned that here the AIs would assert statements in a format that allows for computational inference.
Let me say a bit more about the statements in this type of Bayes-game:
In the toy example with the physics simulation, we could for example imagine statements that describe the following:
This way, we could predictions of final results based on initial conditions. In one sense, it would be an unnecessarily elaborate way of doing that, since the AIs could have done that directly (without the detour of predicting observation-data “abstractions”. But by taking that detour, they have made themselves easier to disprove. They have described correlations in the observation-data that there is plenty of opportunity to prove wrong (if they are wrong).
Here is how some of the adversarial dynamics could work in a Bayes-game with inferred predictions:
When doing Bayes-games with inferred predictions, the AIs would be scored based on factors such as the following:
As you may remember from our discussion of argument-networks, there was a discussion of wiggle room, and different “levels” of wiggle room (the wiggle-room could be relative to a score-function, or a score-function-builder, or a score-function-builder-builder).
In Bayes-games there could be similar mechanisms:
It would also be possible to have Bayes-games, or games that are reminiscent of Bayes-games, where what the AIs bet on is the result of other Bayes-games. So they can make bets how good of a score an AI would get if playing a Bayes-game with a certain specific type of experiment under certain kinds of restrictions. Or they could propose solutions/modifications for the Bayes-game mechanics (from some “space” of solutions/modifications that are allowed), in an attempt to optimize for certain parameters (wiggle room and so on), and make bets on whether the other AI is able to find something better.
Something that may make things easier is that there are domains where we actually know the answers, and are able to test relatively safely (e.g. with simulated physics that have stochastic elements and where the source code is unknown to the AIs - or maybe physical experiments where any experiment that can be proposed is very innocuous). We could keep the “space” of experiments that the AIs are allowed to propose artificially low, and see if those Bayes-games are misleading in regards to what to expect outside of that “space”.
It could potentially be helpful to have pre-done experimental data that the AIs could be tested on. This could include experiments where humans answer questions, with video footage and MRI recordings as observation-data.
I have a few comments where I elaborate on certain topics:
If you found this post interesting, you may also take an interest in other posts from this series.
I appreciate any questions or feedback. I'm also open to video-conversations with more or less anyone who has read this post and wants to talk (feel free to reach out by PM). And if anyone is interested in maybe working further on anything described in this post, then I’d be happy to keep in touch over time.
Thanks to Evan R. Murphy for helping me review early versions of this text!