The mathematics of a latent variable model expresses the probabilities, p(x), for observations x as marginal probabilities integrating over unobserved z. That is, p(x) = integral over z of p(x,z), where p(x,z) is typically written as p(z)p(x|z).
It's certainly correct that nothing in this formulation says anything about whether z captures the "causes" of x.
However, I think it sometimes is usefully seen that way. Your presentation would be clearer if you started with one or more examples of what you see as typical models, in which you argue that z isn't usefully seen as causing x.
I'd take a typical vision model to be one in which z represents the position, orientation, and velocity of some object, at some time, and x is the pixel values from a video camera at some location at that time. Here, it does seem quite useful to view z as the cause of x. In particular, the physical situation is such that z at a future time is predictable from z now (assuming no forces act on the object), but x at a future time is not predictable from x now (both because x may not provide complete knowledge of position and orientation, and because x doesn't include the velocity).
This is the opposite of what you seem to assume - that x now cause x in the future, but that this is not true for the "summary" z. But this seems to miss a crucial feature of all real applications - we don't observe the entire state of the world. One big reason to have an unobserved z is to better represent the most important features of the world, which are not entirely inferrable from x. Looking at x at several times may help infer z, and to the extend we can't, we can represent our uncertainty about z and use this to know how uncertain our predictions are. (In contrast, we are never uncertain about x - it's just that x isn't the whole world.)
Hi Dr. Neal,
Wow, I studied your work in grad school! (And more recently your paper on Gaussian Processes). Quite an honor to get a comment from you. Just as an aside, I am not sure if my figure is visible, can you see it? I set it as the thumbnail, but I don't see it anywhere. In case it doesn't, it is here:
https://www.mlcrumbs.com/img/epistemology-of-representation.png
I think I need to change some labels, I realize now that I have been using 'x' ambiguously - sometimes as a model input, and sometimes to represent the bedrock physical system. But, to clarify, I'll use your vision example, but add temporality:
Your presentation would be clearer if you started with one or more examples of what you see as typical models, in which you argue that z isn't usefully seen as causing x.
Actually your example of a typical vision model is one example where I'd argue this, though I fear you might think this is a trivial splitting of hairs.
In any case, I'll first assume you agree that "causation" by any use of the term, must be temporal - causes must come before effects. So, to a modified question: why wouldn't be usefully seen as causing ? In this case, let's assume then that delta is the time required for photons to travel from the object's surface to the camera.
What I'm more saying is that , or are platonic, non-physical quantities. It is which is causing , and is just a slice of . Or, if you like, could be seen as a platonic abstraction of it.
I would also add though that at best, could at best be interpreted as an aspect of something that caused the pixels . Of course, just position, orientation and velocity of an object aren't enough to determine colors of all pixels.
This vision example is one example in which the representations are very much rigid-body summaries, and so it seems useful to strongly identify them as "causes". But, I am trying to put all of ML and mental models on the same semantic footing here. There are plenty of models, like for instance diffusion models, where the z are just pure noise, where such an interpretation makes no sense at all, even in the sense that you mean.
{kind=link}
Introduction
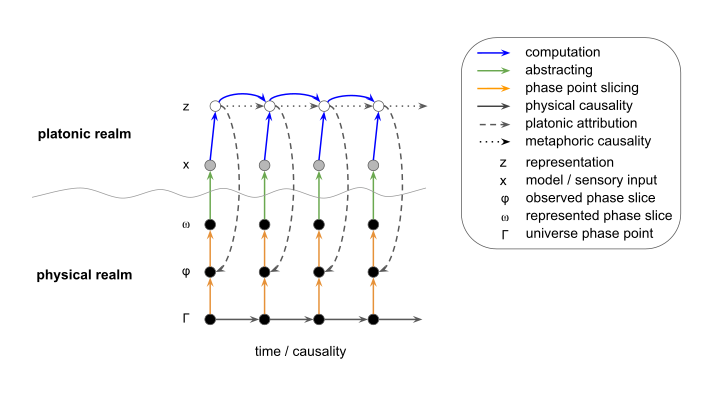
In this note, I argue that the interpretation of representations (mental or machine learning) as causes of observed effects, is wrong by any sensible definition of causality. This interpretation seems to be somewhat common, although not pervasive. I propose a new interpretation based on dualism. In the new interpretation, representations are instead causes of subsequent representations. The gist of it is shown in the figure, with time or causality flowing along the x-axis, and the level of representation along the y-axis. This re-interpretation has implications for the broader notion of "truth", in both the scientific and common-sense senses.
I partly arrived at this conclusion when contemplating large language models. They made me question more and more what it means to understand, reason, or know something. Actually, I had asked this question years before in slightly different form: what is the foundation of machine learning, and is there such a thing as "the true model" which we are trying to discover through SGD and regularization? What makes a "good" representation of the data?
One answer that kept coming up in some form or another is that a good representation zshould discover the causal factors of the observed data, x. The question became especially acute for me when I was studying the original variational autoencoder paper by Kingma and Welling. As an aside, a variational autoencoder (VAE) is a pair of models called generative (mapping z to x) and recognition (mapping x to z) which usually co-train each other on a dataset from x. After studying the paper for a long time, it seemed to me one could train a VAE and fit a data distribution arbitrarily well without the hidden variables z meaning anything at all. Indeed, nowhere in the paper do they mention that z are causal factors of x. And, as much as I tried, I could not find anything in the math where z might take on emergent meaning.
But why should z take on "meaning"? The model was just using these hidden variables as a mathematical tool to create a flexible marginal distribution over x. On reflection, the only reason I was surprised was because I thought of the VAE as a model for human cognition, and we know humans build meaningful representations, and somehow do it in an unsupervised fashion kind of like the VAE.
The VAE paper was presenting a technique and perhaps not much interested in tying it to interpretations of agents, so it is understandable it was not concerned with causal interpretations. An earlier work, Karl Friston's classic paper Learning and inference in the brain does hold this interpretation. It states (emphasis mine):
Using the notation from Kingma and Welling where q is a recognition model, under Friston's interpretation, q(z|x) has the task of inferring the latent causes z of x. In this short note, I argue this is wrong, but it is so close to being right that I don't expect the language to go away. However, I think this leads to an insidious confusion that has implications for interpretability and epistemology in machine learning.
Two separate realms
I claim that the interpretation of z as causal factors for x leads to confusion. To establish this claim, first of all, let's agree that the physical world consists of particles, forces and spacetime, and nothing else. And, the world of abstractions, although supported by and embedded in the physical world, are in a different and non-physical realm. To be concrete: the question "Does π exist?" could be answered: "Yes - every time someone thinks about π, that process physically exists as the particular slice of spacetime in which those neural firings happened in someone's brain." But this is not a meaningful answer. Or, the answer could be: "No - π is not a physical thing in itself" if you interpret the question physically. But this is not very satisfying either.
Using the notion of two separate realms, I would say that π exists in the platonic realm, expressions of which are supported by brains in the physical realm. The two realms are separate - no phyiscal entity ever intrudes into the non-physical, nor vice-versa. But, many of the abstractions are attributed to specific slices of space-time, i.e. a region of space at a particular instant.
Causality
Now on to causality. What is it? A moment's thought will convince you that if we are talking only about the physical world, it just means that it evolves in time according to certain laws. The laws are causality, there is no extra concept needed. From moment to moment, the exact configuration of the universe causes the next configuration. Causes always come before effects. The universe is just a bunch of these particles buzzing about according to the laws, and that's it.
But, because entities in our non-physical, "platonic" realm (categories, descriptions, representations, etc) are defined by, and attributed to various configurations of the physical realm, and because the physical realm evolves according to set laws, these "platonic quantities" also evolve in time (at least the ones that are time and space associated). The mappings from physical to platonic are always many-to-one, and so the evolution of platonic entities in time is not perfectly predictable. And, sometimes the opposite happens - the platonic quantity is quite predictable over time despite that it is an extreme summarization of physical state.
For instance, take the notion of an object's center of mass. A solid object doesn't physically "have" a center of mass - rather, the center is a platonic quantity defined in terms of the masses and positions of each particle. But there is nothing physically special at that location. In this particular case, paradoxically, despite our lack of knowledge of individual particle motions, this platonic quantity evolves very predictably in time due to so many internal collisions constantly cancelling each others' positional contributions.
Zooming out a bit, in the diagram above, z takes on values in this non-physical realm. If we allow for the moment, an analogy within an analogy, let x represent something "closer to" the physical realm here. So, z is attributed to or describes or summarizes x, but it is not in a causal relationship with x. It cannot be - first of all, because z is in the non-physical realm and x in the physical, and they do not cross. Second, because causal relationships require the cause to precede the effect in time. But here, z is attributed to x, thus associated with the same time as x occurs.
Although the evolution in time of a model's representation z doesn't evolve according to "laws" like x does, it tracks x. So, to the extent that x evolves according to physical laws, z evolves in a way that could be accurately predicted. We thus speak of causes and effects in terms of these representations in a metaphorical sense. This is what we do in our daily thoughts and communications. So, to come back to the original claim: z are causes, they are just not causes of x. Rather, zt−1 are causes, in the metaphorical sense, of zt.
The notion of Truth
We as humans have a strong sense of what is "true" - and since we don't have any direct access to the physical realm, this truth can only be a property of our internal representations, which are invented descriptions. Some mental models we build, such as a physio-spatial model, have a very strong notion of truth - I really really believe I'm typing on a laptop right now and not dreaming. Other models have a weaker definition - I am pretty sure I know what some of my friends are thinking much of the time.
But one thing is clear now - mental model building is necessary across all domains, and the notion of "truth", useful in all domains, has a very different character in mathematics than it does in psychology or economics for instance. Absolute truth only seems to apply to abstract subjects like math and physics. For others, it is only used in a loose metaphorical sense. Not only that, even in those pure subjects where truth is the goal, it is not confirmable. Science is honest about this - the best we can do is to not falsify the given current theory.
For awhile I was in a sort of denial about this, and thought sometimes of "the true model" that machine learning was trying to discover. This new duality-based view shatters that notion, and it is actually a great relief to know that there is no such "true model" which I am failing to find. In short, all models are made-up; some predict better than others. (to paraphrase George Box)
The Ultimate MNIST classifier
If you really wanted to "find the true model", though, consider the ultimate MNIST classifier. Instead of convolution and pooling layers, a fully connected layer and final softmax, we want to model the true causal process that gave rise to the MNIST image. This started with a human thinking of a digit, then picking up a pen and putting it to paper, then the ink soaking in, then a camera or scanner shining a light on the paper and the photons hitting a CCD chip, binning the intensity levels and finally storing them in a file. This is what actually happened. So, a classifier then would have to model all of this, and then infer what digit the writer was thinking of.
Real MNIST classifiers, whether machine or Human, don't do this obviously. They don't even attempt to approximate it. They do something else entirely that has nothing at all to do with this physical reality.
Active Inference
So if getting closer to "the true model" is not possible, what criterion for judging a model could apply universally and objectively? The best notion I've come across which attempts to serve as a foundation for model building is Karl Friston's Active Inference - It is a mechanism used by an agent in a world to survive. One byproduct of survival of an agent moving about in a temporal world (i.e. not just labeling static images) is the ability to predict the future. To my understanding, this is needed in order to perform credit assignment from future consequence of action back to current action, across the environment gap. It is a fascinating theory.
Within this theory, the agent must predict future sensory input from its own internal representation of its environment. So, the bedrock notion of what makes a "good" internal representation is entirely utilitarian - how useful the representation is to support accurately predicting future sensory input.
But this is functionally indistinguishable from our psychological notion of truth. An idea is true if it allows us to accurately predict some aspect of the future we care about. It is just the empirical principle of using a theory to test predictions - as long as the theory agrees with observation, it is indistinguishable from truth. Remarkably (to me anyway), this principle seems to work psychologically across all domains from fuzzy to exact, and we experience "truth" along this spectrum as well.
Causal reasoning probably requires temporal knowledge
To summarize, in this dualistic interpretation, there are two forms of causality - the bedrock physical causality, and the metaphorical causality that arises from it purely as a consequence of how the platonic representations are attributed to physical states. But this only happens for those representations that are bound to physical states at a certain time. Temporality is a prerequisite for metaphorical causality to arise. This seems to imply that machine learning models that hope to learn causal relationships must consume temporal data and model its time evolution.
Implication for morality
It is said that you "cannot derive an ought from an is". But, in this new view, this barrier between ought and is dissolves. Or, rather it is side-stepped. Humans have just one brain, capable of constructing representations and ideas to serve the purpose of survival. To the extent that a set of moral principles helps aid that survival, the same process of representation building occurs, just as essential to guilding our behavior as our belief in object permanence or conservation of momentum. If a moral principle that guides behavior leads one to a bad outcome, it could be revised through the same empirical learning process we use for every other mental model.
The dichotomy between facts and values is attractive only because of a failure to recognize that "facts" exist only in this spectrum of truths, which have varying degrees of predictive accuracy across domains. It is a false dichotomy for two reasons. First because there isn't any hard threshold in prediction accuracy where a "truth" suddenly just becomes a model. Second, there is a failure to recognize that all mental models for an agent arise from the same requirement to survive, and therefore are implicitly laden with a value, which you might call moral value.
Implications for interpretability of representations
One goal of interpretability research is to train models that not only produce desired outputs, but produce desired internal representations. In this view, we treat the model not just as a black box. In this endeavor, representations don't just facilitate training and mediate computation of outputs, but also provide hooks to interpret or knobs to control how a model generates an answer or output.
However, one problem with this is that, when applied to ever more subtle domains, humans will no longer have consensus on, or awareness of their own internal representations. Even worse, such representations may be interpretable but give a false sense of understanding to the human.
A more hopeful outcome might be an AI model that can invent interpretations - ones that are better predictors of utilitarian objectives than popular human notions. I'm thinking here of economic models for example. Or, domains in which only theories abound but might have a great room for improvement, such as psychoanalysis.
Human representations are often flawed - more likely so in domains where humans make more mistakes, or for which only some humans have exceptional skill. This is a potentially tremendous opportunity for an interpretable ML model to serve as a teacher, by solving the same problem a human struggles with, and then explaining in great detail how it solved the problem.
Implications for Machine Learning
There is no "true" model - the only way to compare two models is by their prediction accuracy. One model's internal representation z is better than another if it supports a more accurate prediction than another.
Causal reasoning is one facet of interpretability, since we humans can perform it. In light of the two-realm diagram above, we might expect that models presented with a sequence of inputs arranged much like a human might experience that sequence (temporally) will lead to sequences of representations that resemble/imitate/perform causal reasoning. After all, human causal reasoning is a byproduct of the time-evolution of our representations, which is in turn a byproduct of the physical cause-effect chain.
One final thing to note is that all inference is really prediction. Humans often will make inferences about what happened in the past. However, if I do this, I am updating my mental state (as I travel forward through time) and this in turn may affect what new predictions I will make in light of that update. Thinking about the past does sure feel like time travel though!
Conclusion and Reflection
For representations, both in machine learning models, and animal mental models, re-interpreting them as learned, fit-for-purpose inventions rather than causal factors of observed data (or sensory inputs) has a few benefits. First, it is a much more generally applicable interpretation. ML models do many different things. All of them produce internal activations en route to an output. It would be awkward to anoint only some models' representations with special properties. Second, this reinterpretation removes an annoying, and artificial semantic barrier between notion of absolute and "fuzzy" truth, and between absolute and fuzzy causal relationships. Truth now means "a representation that produces accurate predictions of future representations".