This is a linkpost for https://substack.com/home/post/p-198682900
But the real answer to Bertrand’s paradox is that the word ‘random’ is not meaningful without any knowledge of the structure of your sampling process.
Indeed, this is a fully general feature of attempting to know what's true. What we'd like to do is create an objective map the territory, but any map we construct is contingent on large numbers of non-objective assumptions that hinge on everything from sampling, selection, and attention processes to what categories have been historically useful to include in our ontology. This limitation stands in the way of many clever arguments that would seek to do an end-run around uncertainty, but ultimately fail because they smuggle in unjustified assumptions (cf. anthropic arguments).
any map we construct is contingent
Suppose that someone chose the chord, generated
Answer: we ALL will be able to identify it as
Sure, within a fixed framework, we get convergence, even when using different methods. But this is possible because concepts like "the radius of the chord" are already agreed on. The paradox isn't about not knowing which method generated the chord, it's that the question itself is underspecified and can't be fixed without making a choice (introducing contingency) because we lack access to a view from nowhere to adjudicate it.
There is no privileged way of picking out a chord, and therefore there is no 'correct' answer to the question without knowing more about the generating process.
This doesn't quite make sense to me. This just kicks the problem one level up. There are many way's we could privilege one space to distribute our uncertainty over. Almost none of them have minds that value human happiness occupying a large share of the space.
Like it seems obvious to me you have to make this concession. Because your argument doesn't privilege human morality in any way. You could make the same argument to argue we should be "uncertain" about any aspect of AI motivation
Fundamentally, I think we are in a position of deep uncertainty and confusion, and I am very sceptical of anyone who claims to be able to predict the motivation space of future AI systems with any kind of certainty, whether to justify believing the AI will spend all its time [building anime cat
-girls or not]
And I think a lot of discourse in this space could be more productive if people tried to think more about the selection processes generating the relevant distributions, and reason about why some projections are more or less valid than others.
I think all of prosaic alignment work is already about this, no?
>This doesn't quite make sense to me. This just kicks the problem one level up. There are many way's we could privilege one space to distribute our uncertainty over. Almost none of them have minds that value human happiness occupying a large share of the space.
This is just a counting argument about counting arguments, which is very fun, but is still vulnerable to the same objections.
> You could make the same argument to argue we should be "uncertain" about any aspect of AI motivation
I am arguing that a priori we should be "uncertain" about pretty much any aspect of AI motivation, so long as it's not contradictory. There certainly exist optimisation pressures that would select for an AI that wants to spend all of its time building anime cat-girls, but given knowledge of our current economic systems and the culture inside labs, it seems very likely that optimisation pressures will actually select against this.
> I think all of prosaic alignment work is already about this, no?
A lot of prosaic alignment is relevant to this. The post was mostly aimed at the class of people who are very sceptical of prosaic alignment in general because current techniques won't scale to the things that actually matter.
I am arguing that a priori we should be "uncertain" about pretty much any aspect of AI motivation, so long as it's not contradictory. There certainly exist optimisation pressures that would select for an AI that wants to spend all of its time building anime cat-girls, but given knowledge of our current economic systems and the culture inside labs, it seems very likely that optimisation pressures will actually select against this.
I'm just saying apriori, do you think we should be 50/50 on whether the ASI ends up spending its time building catgirls? Or are you advocating for some kind of uncertainty we can't assign numbers to?
Like, I don't think there is a fully canonical way to parameterize the space of all goals AIs have. But there are still somewhat principled arguments you can use to judge that some parametrizations are better than others. Like randomly privileging some concept you like, without good reason, is probably not The Way.
Like if you have AIXI, and you have a value-function slot, and you randomly sample from bit strings that encode valid value function, weighted by their length, I'd be willing to bet at 1:999999 odds you don't end up with a catgirl-AIXI. To get catgirl aixi, you have to put a bunch of stuff into the specification of your probability weighting.
A lot of prosaic alignment is relevant to this. The post was mostly aimed at the class of people who are very sceptical of prosaic alignment in general because current techniques won't scale to the things that actually matter.
To me the counting arguments are more about, some people think "50/50 it kills us or doesn't, we do RLHF++ which moves it to 95/5, we do a bunch of other fancy monitoring and control with interp in theloop and alignment pretraining etc, and we move it to 99/1"
Others (I'm in this camp) view it more like 1:10^9999* chance a random neural-net ASI is friendly. Then if it was created from pretrained base its somewhere between 1:10^998 and 1:10^-1* (with distribution over those netting to ~20%?). Then post-training moves it to somewhere between 1:10^9997 and 1:10^-999 (netting to maybe 50%?).
Does this sound reasonable? Does it illustrate why I think counting arguments tell us something, but that almost all the work goes into figuring out how details of training update that distribution?
*just me writing the first numbers that pop into my head for illustrative purposes
> I'm just saying apriori, do you think we should be 50/50 on whether the ASI ends up spending its time building catgirls? Or are you advocating for some kind of uncertainty we can't assign numbers to?
Yes, I am saying precisely that we shouldn't assign 50/50 when faced with deep ignorance about the nature of the generating process. Maybe I am advocating for a stance of Knightian uncertainty or maybe just saying that the standard Bayesian approach can plausibly lead you to be much too overconfident in your views. I think reasoning about ASI a priori doesn't makes sense in the same way that the question posed in Bertrand's paradox doesn't make sense.
>Like if you have AIXI, and you have a value-function slot, and you randomly sample from bit strings that encode valid value function, weighted by their length, I'd be willing to bet at 1:999999 odds you don't end up with a catgirl-AIXI. To get catgirl aixi, you have to put a bunch of stuff into the specification of your probability weighting.
So two things I want to point out here:
1) I suspect there is no single privileged value function encoding, so I think the answer to this question is undefined. I admit though that some value function encodings look weirder than others, and I think I agree with the general gist of what you're saying.
2) I think that the jump to "1:10^9999* chance a random neural-net ASI is friendly" is not valid here. AIXI is one framework which we can use to reason about intelligent neural networks, but it is far from the only one. I think 'random neural-net AISI' is underspecified unless you provide a sampling method, and yes you're allowed to use this as a prior, and I think it's not an unreasonable one to use here, but there are other priors you could use that would give you much less pessimistic conclusions.
Yes, I am saying precisely that we shouldn't assign 50/50 when faced with deep ignorance about the nature of the generating process. Maybe I am advocating for a stance of Knightian uncertainty or maybe just saying that the standard Bayesian approach can plausibly lead you to be much too overconfident in your views.
I mean, to be honest, I don't really understand Knightian uncertainty. ASI either kills us or it doesn't. If we lived in a distinct reality where the outcome of ASI doesn't impact us except we get to know how it went, and I offered you a bet, where you get a billion dollars if ASI doesn't kill everyone, and you have to pay me 1 cent if it does. Do you not take the bet? That seems absurd to me, but if you do take the bet, you have an implied probability distribution over outcomes.
I guess a more direct argument against what you're saying is: Bertrand's paradox occurs because the sample space is underspecified. But in the real world, there is a fact of the matter about the sample space. We are uncertain about that fact. But we can observe that almost any such sample space, unless we put in a bunch of very specific information, will have the property that, friendly goals occupy a very small fraction of it.
I think that the jump to "1:10^9999* chance a random neural-net ASI is friendly" is not valid here. AIXI is one framework which we can use to reason about intelligent neural networks, but it is far from the only one. I think 'random neural-net AISI' is underspecified unless you provide a sampling method, and yes you're allowed to use this as a prior, and I think it's not an unreasonable one to use here, but there are other priors you could use that would give you much less pessimistic conclusions.
This is kind of addressed by what I said above but imagine you have a gpt2-style transformer, but it has 1 quadrillion layers, and a hudnred quadrillion dimensional hidden state. Then look over all possible ways to assign values to the weights, assuming a fixed floating point representation.
Seems likely to me some fraction of those will yield an ASI. And some fraction of those ASIs will be friendly. But that fraction will be vanishingly small. And furthermore, that if you want to modify the probability distribution over weights so that friendly AIs are likely, you'll need to add a bunch of ad-hoc and very specific information into the distribution.
>I guess a more direct argument against what you're saying is: Bertrand's paradox occurs because the sample space is underspecified. But in the real world, there is a fact of the matter about the sample space. We are uncertain about that fact. But we can observe that almost any such sample space, unless we put in a bunch of very specific information, will have the property that, friendly goals occupy a very small fraction of it.
I agree with everything you said here, up to the point of "but we can observe that almost any such sample space...". My point is twofold:
(1) instead about reasoning about proportion of sample spaces, we should actually try to reduce uncertainty about the sample space by reasoning directly about it
(2) when you start reasoning about "friendly goals", you are implicitly projecting down to a lower-dimensional subspace, which does not necessarily preserve the structure of your original space, and so may radically distort proportions
when you start reasoning about "friendly goals", you are implicitly projecting down to a lower-dimensional subspace, which does not necessarily preserve the structure of your original space, and so may radically distort proportions
No offense, I already addressed this.
(1) instead about reasoning about proportion of sample spaces, we should actually try to reduce uncertainty about the sample space by reasoning directly about it
You "should" do that. I agree, but that doesn't mean counting arguments provide no evidence. If I have a mole that appears diffuse and growing, I should get it checked out to be sure it is/isn't cancer. But that doesn't mean a diffuse mole that's growing isn't more scary than one that isn't growing and isn't diffuse.
Hey, sorry for not engaging properly. On rereading your earlier comment:
>This is kind of addressed by what I said above but imagine you have a gpt2-style transformer, but it has 1 quadrillion layers, and a hudnred quadrillion dimensional hidden state. Then look over all possible ways to assign values to the weights, assuming a fixed floating point representation.
>Seems likely to me some fraction of those will yield an ASI. And some fraction of those ASIs will be friendly. But that fraction will be vanishingly small. And furthermore, that if you want to modify the probability distribution over weights so that friendly AIs are likely, you'll need to add a bunch of ad-hoc and very specific information into the distribution.
This seems like a more reasonable prior to start with. I think this gets you less doom than AIXI though. But I can make this same argument about biology: consider all of the possible sets of DNA that can produce an organism. Some fraction of these are going to be at least an an intelligent as a mouse. But a vanishingly small fraction of these have legs (most, in fact, are just blobs of brains or other cognitive machinery). So we should expect it to be incredibly unlikely that systems smarter than a mouse have legs. But it turns out that it's actually not that hard to create a selection process of which legs are a convergent property. I would claim that we don't really know how hard it is to create a selection process of which "don't kill us" is a convergent property. So I think unless you specify a particular selection process, it's hard to make strong claims, purely from reasoning about the sample space.
> I mean, to be honest, I don't really understand Knightian uncertainty. ASI either kills us or it doesn't. If we lived in a distinct reality where the outcome of ASI doesn't impact us except we get to know how it went, and I offered you a bet, where you get a billion dollars if ASI doesn't kill everyone, and you have to pay me 1 cent if it does. Do you not take the bet? That seems absurd to me, but if you do take the bet, you have an implied probability distribution over outcomes.
So Infra-Bayesianism (which I don't really understand) has a way of dealing with this through risk aversion across sets of priors. But yeah, I do have some implied probability distribution through the class of bets I'm willing to take. This plausibly manifests as not really being willing to take bets around the 50/50 mark and the further away you go, the more willing I am to take bets. You can perhaps model me as being risk averse and having uncertainty over my own credences. But I haven't really given this much thought, and I'm not entirely sure I endorse this.
> You "should" do that. I agree, but that doesn't mean counting arguments provide no evidence. If I have a mole that appears diffuse and growing, I should get it checked out to be sure it is/isn't cancer. But that doesn't mean a diffuse mole that's growing isn't more scary than one that isn't growing and isn't diffuse.
yep I agree with this, I think counting arguments should give you some evidence (which is maybe where I diverge from the Belrose and Pope view) but the further removed they are from the reality of how these systems are trained, the less I think they should update you.
> No offense, I already addressed this.
Please let me know if I haven't responded properly to this, I wasn't sure what exactly you were referring to.
I'm confused by this post (and why a perfectly fine response by williawa was downvoted). The post feels like a fully general argument against Bayesianism, probabilities, and reasoning (about novel situations) in general. Judging by the author's clarifying comment, it is a fully general argument:
Maybe I am advocating for a stance of Knightian uncertainty or maybe just saying that the standard Bayesian approach can plausibly lead you to be much too overconfident in your views. I think reasoning about ASI a priori doesn't makes sense in the same way that the question posed in Bertrand's paradox doesn't make sense.
But then the post shouldn't have been about counting arguments specifically!
Also, a nitpick:
I wanted to write this up because I think that a lot of disagreements about alignment bottom out into differences in projections, but people often argue as if they’re disagreeing about the territory.
People do disagree about the territory though?? The claim that people's disagreement is merely semantic is shocking, it requires examples.
Hey, thanks for your comment.
> The post feels like a fully general argument against Bayesianism, probabilities, and reasoning (about novel situations) in general.
I don't think I am directly arguing against Bayesianism in the post. I think that Bayesianism is underspecified when it comes to where to get your priors from, and I wanted to make the weaker claim that this isn't a particularly good way of informing your priors and can lead to overconfidence.
> People do disagree about the territory though?? The claim that people's disagreement is merely semantic is shocking, it requires examples.
Yep, this perhaps wasn't phrased very well. I was trying to express my frustration at a particular kind of disagreement I've seen where people have different models and the disagreement boils down to "ah but my model says this" without actually having much evidence that would distinguish the two models. People are disagreeing about the territory here, but filtered through different models, which sometimes they fail to recognise, and results in less productive disagreement.
cf. https://www.lesswrong.com/posts/YsFZF3K9tuzbfrLxo/counting-arguments-provide-no-evidence-for-ai-doom , https://www.lesswrong.com/posts/yQSmcfN4kA7rATHGK/many-arguments-for-ai-x-risk-are-wrong
A counting argument is a style of argument that looks something like this:
For example, when trying to answer the question “what is the probability that superintelligent systems will want to kill us” we might use an argument like:
I wonder what you think of this argument. Does it sound familiar to you? Does it seem reasonable?
Bertrand's Paradox
Consider an equilateral triangle inscribed in a circle. Suppose a chord of the circle is chosen at random. What is the probability that the chord is longer than a side of the triangle?
Method 1: random endpoints. Pick two points at random on the circumference and draw the chord between them. By rotational symmetry, fix one endpoint at a vertex of the triangle. The chord is longer than a side iff the other endpoint lands on the arc between the two opposite vertices — one third of the circumference. The probability is 1/3.
Method 2: random radial point. Pick a radius at random, then pick a point on that radius uniformly, then draw the chord perpendicular to the radius at that point. The chord is longer than a side iff the point lies within half the radius of the centre. The probability is 1/2.
Method 3: random midpoint. Pick a point at random inside the disk; it is the midpoint of a unique chord. The chord is longer than a side iff the midpoint lies within the inscribed circle of radius r/2, which has area 1/4 of the disk. The probability is 1/4.
(images from https://en.wikipedia.org/wiki/Bertrand_paradox_(probability) )
All three arguments seem reasonable; all assume a uniform prior over some unknown property of the chord (positions of endpoints, perpendicular radial point, midpoint), but lead to contradictory conclusions. It turns out that a uniform prior in the face of radical uncertainty (the Principle of Indifference) is a principle that cannot be applied coherently. There is no privileged way of picking out a chord, and therefore there is no 'correct' answer to the question without knowing more about the generating process.
AI Safety Projections
Many arguments about future AI systems implicitly rely on something like a uniform prior over an unknown property of superintelligent systems (the goals that they will have). This is, in some sense, an argument from ignorance - and I admit it should at least give us reason to be uncertain about what kinds of goals AI systems develop - but it provides a deceptively compelling intuition for why we should expect doom with high probability.
I don’t think all counting arguments are bad, or should never be used. But the real answer to Bertrand’s paradox is that the word ‘random’ is not meaningful without any knowledge of the structure of your sampling process. When you make a counting argument, you are implicitly projecting the weird complex minds that future AI systems will be into a lower dimensional, more understandable subspace (eg. the space of goals and world models - or analogously, the midpoint of a chord). Much like how Greenland looks almost as large as Africa on a Mercator projection, the apparent distribution over outcomes depends entirely on the projection you choose, and so can easily distort structure.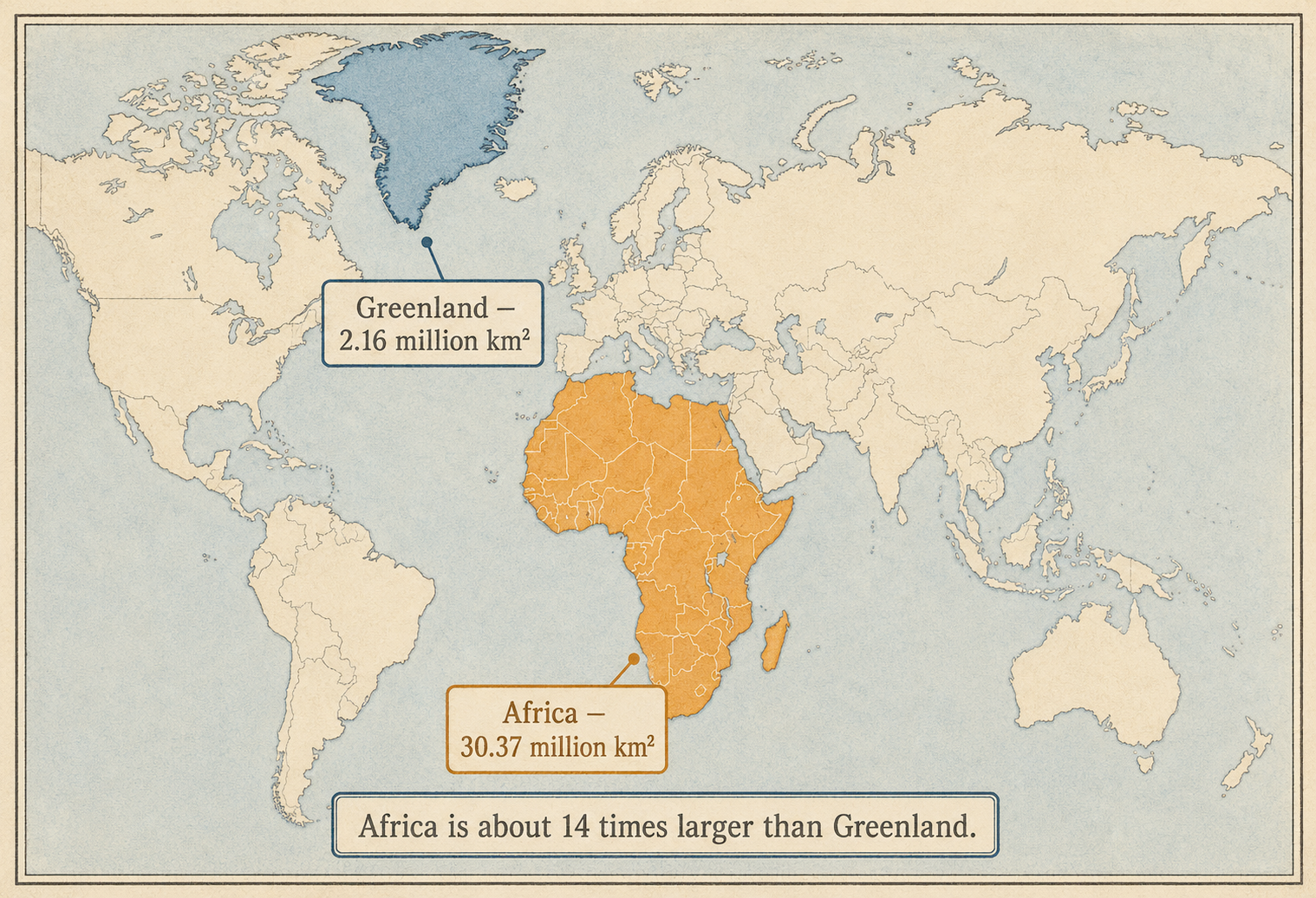
I wanted to write this up because I think that a lot of disagreements about alignment bottom out into differences in projections, but people often argue as if they’re disagreeing about the territory. And I think a lot of discourse in this space could be more productive if people tried to think more about the selection processes generating the relevant distributions, and reason about why some projections are more or less valid than others. Fundamentally, I think we are in a position of deep uncertainty and confusion, and I am very sceptical of anyone who claims to be able to predict the motivation space of future AI systems with any kind of certainty, whether to justify optimism or pessimism.
Written during AFFINE Superintelligence Seminar. Thanks to Stefano Zuffi, Kaarel Hänni, London Lowmanstone IV and Justis Mills for discussion and feedback on various drafts of this post.