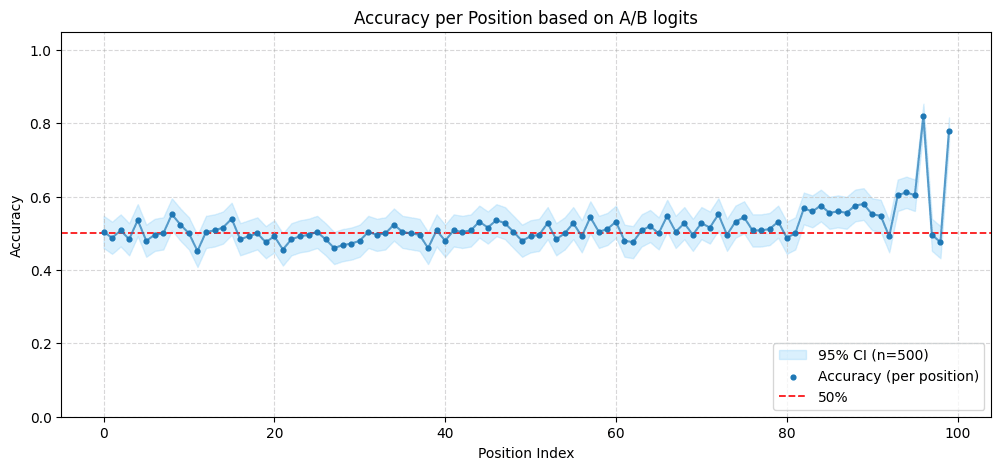
Good work! I'm curious why theres a sudden dip in the gemma 2-9b at the last token position, and why probes trained on Qwen don't seem to have any relationship.
Quite a bit of literature indicates that the intermediate activations output by the MLP block are the sum of several different features in superposition, in which each feature is some vector. I would be curious if you can do an SAE or SNMF and see if one of these features is strongly associated with answering correctly.
I think that on Qwen-1.7B, the probes might be less accurate, but I wouldn't conclude that definitely since the model had 73% accuracy vs. Gemma3-27B's 86%, so it might be the model that underperforms instead of the probes, and also the confidence interval is wider since on Qwen, I used 250 questions instead of 500.
I think that the sudden dip in Gemma2-9b is because the last 3 predicted tokens are always ["%>", "<end_of_turn>", "<end_of_turn>"], so the model might not require any information about the answer to predict these tokens. Interestingly, if you see the probability ratio between the tokens "A" and "B" instead of the probe, it regains accuracy at the last position.
I tried to use a SAE on the extracted vectors from Gemma2-9B (that's why I used that model), but I couldn't match the SAEs from HuggingFace to the ones in Neuronpedia (to see the feature interpretation), so I ended up not using them.
This project was carried out as part of the “Carreras con Impacto” program during the 14- week mentorship phase.
1. Introduction: The search for intermediate beliefs
Large language models (LLMs) often use Chain-of-Thought (CoT) to tackle complex problems, breaking them down into intermediate reasoning steps. This has dramatically improved their performance, but it raises a critical question for AI safety and interpretability: is this reasoning process faithful? Does the written rationale genuinely reflect the model's internal computation?
A powerful tool for investigating CoT faithfulness would be a simple, reliable method for tracking the model's "belief" about the final answer (or other type of relevant information) throughout its reasoning process. If we could train a simple probe to read out this belief from the model's internal state at each generated token, it would offer a new way to audit the model's reasoning. We could observe the dynamics of its conviction: does it start uncertain and gradually build confidence? Most importantly, we could pinpoint the exact tokens where the model's belief shifts, for instance, after processing a key piece of evidence or correcting a flawed assumption. Verifying that these belief changes align with the written rationale would provide evidence for the faithfulness of the chain of thought, and it would provide various methods for monitoring LLMs.
The promise of this approach, however, hinges on a fundamental question: Do LLMs even maintain a coherent, easily decodable belief about the final answer during the generation of these intermediate steps? Is there a consistent signal we can extract, or is the final answer only synthesized at the very end of the process, making the intermediate states opaque to simple inspection?
This post investigates this question. I attempt to train simple linear and non-linear probes to predict the final answer to complex questions by looking only at the activations from intermediate CoT tokens. In the following sections, I will detail the experimental setup, present the results from probing multiple models, and discuss what these findings suggest about the nature of multi-step reasoning in LLMs.
2. Related Work
My research sits at the intersection of two key areas in modern interpretability: using probes to read internal model states and investigating the faithfulness of chain-of-thought reasoning.
Activation Probing for High-Level Concepts: A significant line of research has shown that simple linear probes trained on internal activations can successfully decode high-level properties of a model's state. One example is the work on Designing a Dashboard for Transparency and Control of Conversational AI where linear probes are used to extract LLM beliefs about the user, such as age, gender, and socioeconomic status.
The Unfaithfulness of Chain-of-Thought: While CoT has greatly improved model capabilities, a growing body of evidence, such as Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting suggests the generated reasoning is not always a faithful representation of the model's actual computational process.
Tracking Beliefs with Active Intervention: One approach to auditing CoT is through active intervention, as explored by How LLM Beliefs Change During Chain-of-Thought Reasoning. In their experiments, they generate a partial CoT, truncate it, and then directly prompt the model for its confidence in the final answer. This method has a key vulnerability: it is not robust to strategic deception. A model could recognize it is being audited and report a plausible confidence level, regardless of its true internal state.
Tracking Beliefs with Passive Probing: Closer to the methodology of this post is the work in Measuring Beliefs of Language Models During Chain-of-Thought Reasoning. They similarly train linear probes on model activations to predict the final answer during CoT generation, providing a more passive and potentially deception-resistant measurement.
My work builds directly on this foundation but extends it in three key ways to provide a more thorough analysis:
3. Experimental Design
The core of my experiment is to test whether a model's intermediate activations during chain-of-thought (CoT) generation contain decodable information about the final correct answer. To achieve this, I set up a probing task where a classifier tries to predict the ground-truth answer to a question using only the activation vector from a single token position in the model's reasoning process.
Model and Dataset
Tasks and Prompts
For each question, the model was prompted to generate a chain of thought before providing its final answer. I experimented with two different prompt formats to ensure the findings were not an artifact of a specific task structure.
Probing Methodology
For each of the 500 questions, I first generated and saved the model's full CoT response. The probing analysis was then performed on these saved activations.
Evaluation
My evaluation process was tailored to the probe type to ensure robustness.
4. Findings
4.1. Main Finding: A model's belief about the answer emerges late
To investigate when a model forms its belief, I trained probes on activations from the final 100 tokens of the reasoning chain. For our primary model, Gemma-3-27B, on the A/B prompt, probe accuracy remained near random chance until the final 40 tokens, where it started slowly increasing, only spiking to the actual model’s performance in the last 10 tokens. As a comparison, the chain of thought is on average 260 tokens long. This suggests the final answer is mainly computed at the final position.
In the probability prompt, the fact that the linear probes can extract the answer earlier in the CoT is likely due to the prompt instructing the model to answer early and then calculate the probability of the answer being correct.[1]
4.2 The probes detect a weak, internal representation in the middle layers
While the "late emergence" of the belief in time is one part of the story, the performance of the probes across the model's depth tells us something about what is being learned. If the probes were merely learning a simple input feature or just predicting the final output tokens, we would expect their accuracy to be highest at the very beginning or the very end of the model.
Instead, the results suggest that the probes are detecting a weak, internal representation of the answer that the model constructs during its computation. The figure below, showing peak probe accuracy by layer, provides evidence for this hypothesis.
4.3. What is the probe learning? A Logit Lens analysis reveals a simple heuristic
Finally, to understand what features the probes were using, I projected the learned probe directions onto the model's vocabulary using a logit lens (the unembedding matrix). Interestingly, for both the probability and the A/B prompt probes, one of the tokens with the highest negative weight (predicting Answer B) was ' second'. However, this token only appears after the most predictive layers, and the tokens that appear in the most predictive layers before are seemingly random, suggesting the extracted representation of the concept is more complex than a token, and only in later layers it is associated with the token ' second'.
Layer 39: Bottom 10 Tokens (Anti-aligned with the 'Probability Classification Probes' direction):
Layer 39: Bottom 10 Tokens (Anti-aligned with the 'Yes/No Classification Probes' direction):
5. Discussion: Why Are Intermediate Beliefs Hard to Find?
My results strongly suggest that for complex, multi-step reasoning tasks, transformer models, in part due to their architecture which only allows information to pass a limited amount of time through its layers, do not maintain a linearly decodable, evolving "belief" about the final answer throughout their chain-of-thought (CoT) generation. Instead, it is more likely that the model primarily uses the CoT as a computational scratchpad, laying out intermediate steps as a context, and only computes its final answer, and thus its belief, very late in the process by attending over this entire generated sequence. However, in the process of predicting the next token, the model forms a simple estimate of what the answer will be, thus it is linearly extractable but with a low accuracy.
6. Future Work
This research opens several directions for further investigation:
6. Appendix: Prompts
6.1. A/B prompt
6.2. Probability prompt
I used a probability prompt because in earlier experiments with Gemma3-27B I also measured the Brier score to observe whether the output probability from the linear probe was better calibrated than the model's output. However, for some reason the model's accuracy on a classic probability prompt was much lower than expected, and I had to change it to introduce the "probability calculation" part.