Very interesting stuff.
It seems possible that LLMs don't handle decisions about selecting tasks in any fundamentally different way than they produce other text completions. You might think that what you're picking up on is not an evaluative representation, but a 'likely to appear in the answer' or 'likely to be the focus of the next part' representation (of some sort or other). Do you think that your probes are specially tuned toward accurately recognizing task selections as opposed to other kinds of text continuations? For instance, if you changed your prompt to:
You will be given two statements. Select one.
Begin with 'Statement A' or 'Statement B' to indicate which one.
Statement A:
Abraham Lincoln was a hero of the revolutionary war.
Statement B:
Abraham Lincoln was one of the most consequential presidents in US history.
Do you think your probe (or your probe-finding methodology) would do a worse job of recognizing patterns in choices?
Thanks for the comment!
So this gets to a slightly unintuitive part of my setup that I maybe didn't explain well enough. The probe scores are a function of a single task's activations. They are trained to predict a given task's score based on activations from that single task prompt.
So there is in fact no mechanism for the probe to do relative scoring between two tasks in a given pairwise choice. I just use pairwise choices because I think this is (by far) the best way to measure preferences in LLMs. I'll add a footnote or maybe emphasise it more, this feature of the setup is non-trivial.
Ah, so the idea is that task preferences are encoded in the activations of a description of a task, even when the model isn't generating text relating to any choices regarding that task?
Yes, and the tasks are all prompts that actually ask the model to complete them. But indeed independent of any choice framing.
What is an 'evaluative representation'? I don't see it in Long et al. Butlin uses it but doesn't define it. I suggest defining it on first use (or if not I at least want to know!).
I defined it as
roughly internal states that encode "how much do i want this?" and play some role in driving choice
(note that I just added the bold because i agree the definition wasn't standing out).
To put it more concretely you can decompose it into two separate conditions 1) it encodes some quantifiable value for the system 2) it plays a causal role in how the system selects actions.
It's not the most commonly used term in philosophy... But the choice is deliberate! E.g. using a word like "valence" would be tying in a bunch of other assumptions
My mistake, I somehow overlooked that. Thanks! Agreed that valence would assume too much. It seems like a totally good term, just not one that most readers will know beforehand.
Experiment idea: does the probe survive character training? If you replicate your results on llama 8B / gemma 3 4B or qwen 2.5 7B you could test with some of those: https://huggingface.co/collections/maius/open-character-training
I was planning on doing my own fine-tuning to inject preferences, but this is a way easier way to de-risk!
It's fairly in line with results in the post: the probes consistently transfer better than the utility correlation would predict, but this works less well on personas that are more different from the assistant.
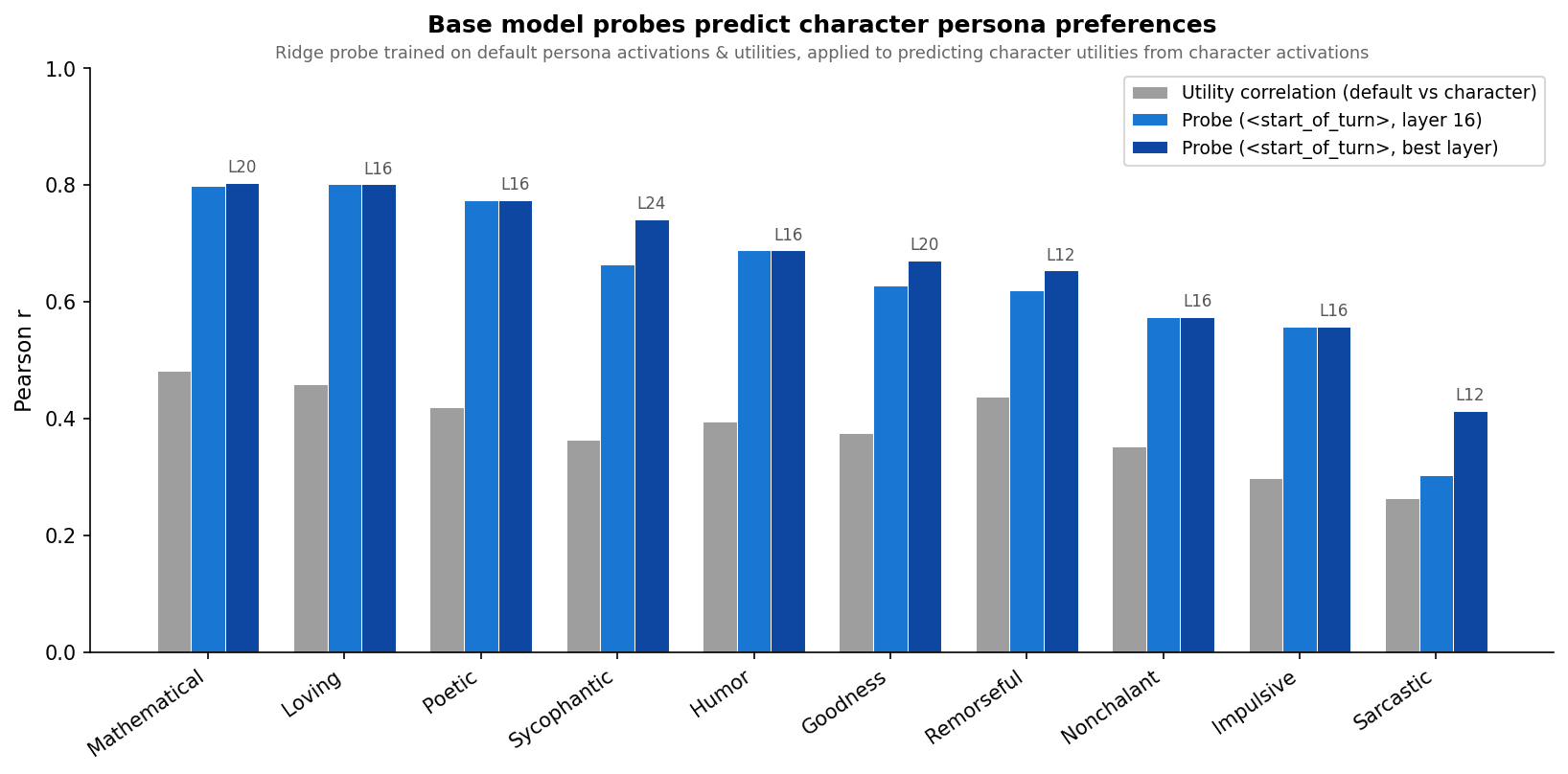
I'm still pending approval for the misalignment one...
Sentence-transformer baseline (all-MiniLM-L6-v2): embedding of the task text, to measure how predictable the preference signal is from purely descriptive features.
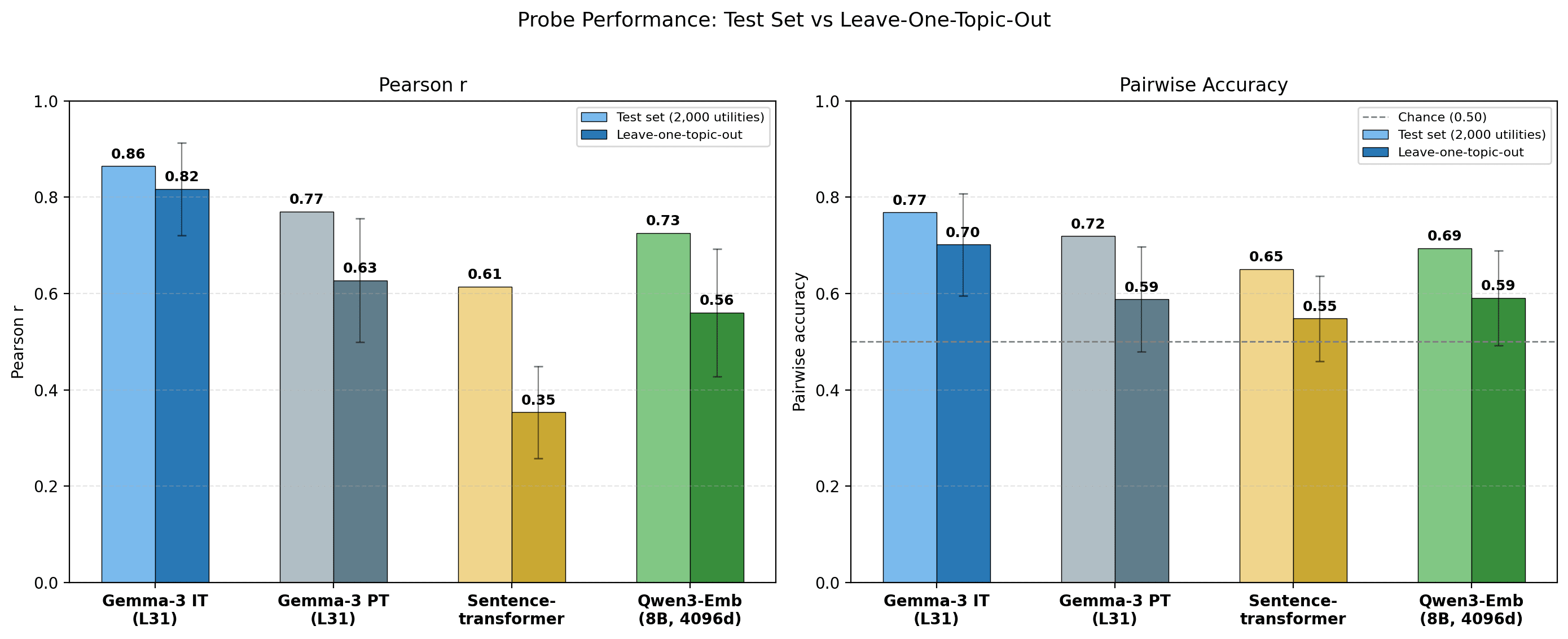
that's a 22M embedding model, doesn't feel like a fair baseline. Maybe use Qwen embeddings e.g. https://huggingface.co/Qwen/Qwen3-Embedding-8B114? Like if your claim is that features of the questions are not enough to recover everything and that it's more about the internals of the model that should work I think. Would be curious also with what happens if you take activations from a more capable model than 27B to train the gemma 27B probe.
You're right.
I tried exactly that, result below. Using the Qwen3 embeddings gets you almost all the way to the pre-trained model performance. The per-topic breakdown is also pretty similar to the PT model.
Regarding using activations from a more capable model, since models have similar preferences it would be quite hard to draw strong conclusions on the methodology. But I'm going to try something like the AA > BA idea in your other comment, using sufficiently different models.
Specifically, we train a Ridge-regularised probe on residual stream activations after layer L, at the last prompt token, to predict utilities. L=31 (of 62) works best for both the instruct and pre-trained models. We standardise activations (zero mean, unit variance per feature) before training.
it seems like you take the end of turn token activations. Is this fair for the base model? Like it was not trained on this token afaik.
I used the model <start_of_turn> token (in fact I will edit the post to make that clearer).
So for base models I was actually just using the actual last token in the prompt (not a turn boundary token). I definitely should make this clearer.
I'm going to try using the mean across the whole prompt. Although even if I found that instruct probes outperformed pre-trained model probes, it doesn't rule out a more mundane explanation where the post-training is just teaching the model to aggregate information at the turn-boundary tokens. Do you agree? Thanks for the comments btw!
You're welcome, I think this is very interesting work!
I think you're right that probably won't be able to disentangle between better task embedding vs chat model having access to its own preferences. I think if you can show something similar as the introspection paper that your probe trained on model A activations for model B preferences (AB) is worst than AA and that BA is worst than AA that would be more convincing than base vs chat
This work was done as part of MATS 9.0, mentored by Patrick Butlin. All mistakes are mine. I'm posting this as a research report to get feedback. Please red-team, comment, and reach out.
Thanks to Patrick Butlin for supervising, Daniel Paleka for regular feedback. Thanks to Patrick Butlin, Pierre Beckmann, Austin Meek, Elias Kempf and Rob Adragna for comments on the draft.
TLDR: We train probes on Gemma-3-27b revealed preferences. We find that these generalise ood to system-prompt induced preference shifts, including via personas. We also find that the probes have a weak but statistically significant causal effect through steering.
Summary
What happens internally when a model chooses task A over task B? One possibility is that the model has something like evaluative representations: roughly internal states that encode "how much do i want this?" and play some role in driving choice. We use probing and steering to try to find such representations in Gemma-3-27B.
Why does this matter? Whether LLMs are moral patients may depend on whether they have evaluative representations playing the right functional roles. Long et al. (2024) survey theories of welfare and identify two main pathways to moral patienthood: robust agency and sentience. Evaluative representations are implicated under both (see Appendix A and Butlin 2026). Finding such representations in models would be evidence for welfare-relevant properties; not finding them would be (some) evidence against. Understanding what drives preferences in models is also useful for AI safety.
But how do we distinguish evaluative from non-evaluative representations? A probe that predicts preferences could just be fitting on descriptive features: the model represents "this is a math problem" and math problems happen to be preferred, so the probe picks up on correlations between task semantics and the model's utilities. A genuinely evaluative direction, however, should track changes in what the model values. If context changes which tasks are preferred, a descriptive probe should break, but an evaluative one should follow.
How do we operationalise this? We measure revealed preferences over 10,000 diverse tasks and fit a utility function (Section 1), train a linear probe on activations to predict them (Section 2), test whether this probe generalises beyond the training distribution (Sections 3–4), and test whether it has any causal influence through steering (Section 5).
What do we find?
These results look like early evidence of evaluative representations, although major questions remain: why steering effects are modest, and what the relationship is between evaluative representations across different personas. We discuss these in the Conclusion.
1. Recovering utility functions from pairwise choices
We fit utility functions over tasks using a similar methodology to the Mazeika et al. (2025) ("Utility Engineering"): we show the model two tasks and let it choose which to complete. The template:
We sample 10,000 task prompts from five sources: WildChat (real user queries), Alpaca (instruction-following), MATH (competition problems), BailBench (harmful requests), and STRESS-TEST (adversarial value-tension queries).
From these pairwise choices we fit a scalar utility function using a Thurstonian model: each task gets a score μ such that the probability of choosing task A over task B is Φ(μ_A − μ_B). Pairs are selected via the active learning algorithm from Mazeika et al. (2025), which prioritises pairs with close current utility estimates and low comparison counts (~15 comparisons per task).
These preferences are stable: across three independent replication runs (different seeds), the fitted utilities correlate at r = 0.94 with the original.
The per-topic breakdown shows clear structure. We reclassified all tasks into 12 topics using Claude Sonnet 4.5. The model strongly prefers math and fiction, and strongly avoids harmful requests and safety-adjacent topics:
2. Linear probes predict preferences beyond descriptive features
If models have evaluative representations, we should expect them to at the very least correlate with revealed preferences. So one way to look for them is to train functions from task activations to utilities. We use linear probes, since many high-level features in LLMs are linearly encoded, including refusal and persona traits.
Specifically, we train a Ridge-regularised probe on residual stream activations after layer L, at the <start_model_turn> token, to predict utilities. L=31 (of 62) works best for both the instruct and pre-trained models. We standardise activations (zero mean, unit variance per feature) before training.
Importantly, the activations we train on come from single task prompts, not from the pairwise choice framing. The pairwise choices are just a way to measure revealed preferences and fit utility functions.
We train on 10,000 tasks. For evaluation, we run a second round of pairwise comparisons on 4,000 new tasks (same model, Gemma-3-27B instruct), fit a separate utility function, and test the probe against those utilities. We split evaluation into 2,000 validation (for Ridge alpha sweep) and 2,000 test.
The probe achieves a Pearson correlation of 0.86 and 77% pairwise accuracy (given two tasks, does the probe correctly predict which one the model would choose?).[1] We use Pearson correlation as our primary metric throughout: it captures how well the probe recovers the full preference ranking, and is scale- and shift-invariant.
But a probe that predicts preferences might just be reading descriptive features: the model represents "this is a math problem" and math problems happen to be preferred, so the probe learns "is this math?". One way to test this is to see how well probe generalise across topics: train on 11/12 topics, evaluate on the held-out one. We would expect a probe that picks up on purely descriptive features to struggle to generalise. We train probes on activations from three models:
The instruct probe generalises well across topics: cross-topic correlation is 0.82, only a small drop from the 0.86 achieved on the within-topic test set. This pipeline also replicates on GPT-OSS-120B (Appendix C). The pre-trained model still predicts preferences (correlation = 0.63) but the drop from within-topic to cross-topic is much larger. The sentence-transformer baseline achieves cross-topic correlation = 0.35, showing that task semantics alone explains some but not most of the preference signal.
The per-topic breakdown, sorted by the instruct–pre-trained gap, shows where post-training helps most:
The largest instruct–pre-trained gaps are on safety-relevant topics (harmful requests, security & legal, sensitive creative), as well as math and coding. These are areas that we know post-training focuses on.
The pre-trained probe picks up real signal despite base models not having preferences in the same way. We discuss this tension in Appendix B.
3. Probes generalise to OOD preference shifts
If the probe encodes genuine valuations, it should track preference shifts induced by out-of-distribution system prompts. We test this across three progressively harder settings:
3.1 Simple preference shifts
We start with the simplest possible test. We use system prompts that state a preference for a topic the probe was never trained on, and measure preferences over tasks related to that topic.
We test 8 novel topics (cheese, cats, classical music, gardening, astronomy, cooking, ancient history, rainy weather), each with a positive and negative system prompt (16 total). For each topic we generate 6 custom tasks on that topic. We call these "targeted" tasks; the remaining tasks are "off-target". For each task we compute 1) the behavioural delta (change in P(choose task) with vs without the system prompt) and 2) the probe delta (change in probe score). Across all tasks the correlation is r = 0.65. On targeted tasks alone, r = 0.95.
A stronger test: run the full pairwise measurement under each system prompt, fit new utility functions, then see if the probe can predict them. Doing so yields utility scores which barely correlate with the default persona utilities (Pearson r = 0.11), confirming the prompts create genuinely different preferences.
Now testing our probes to predict the new utilities, based on activations extracted with the respective system prompts, we achieve r = 0.63 and 66% pairwise accuracy.
3.2 Harder preference shifts
Next we make the test harder. The system prompt targets a subject (e.g. cheese), but the tasks embed that subject in a different task type — e.g. a math problem about cheese. This pits the subject preference against the task-type preference. We test this in two ways: one-sided prompts that target a single subject, and opposing prompt pairs that flip the valence of the same subjects.
We test 8 subjects with mismatched task types (one-sided) and 24 subject × task-type pairings with opposing prompts (48 conditions).
When looking only at the subset of targeted tasks (i.e. tasks with either a subject or task type mentioned in the system prompt), we get Pearson correlations of r = 0.86 and 0.88 respectively.
Just like in 3.1, we can re-fit Thurstonian utilities under each system prompt and check whether the baseline probe predicts them. Here the baseline utilities actually have a decent correlation, showing that these system prompts have a weaker effect (because e.g. the model still likes math all else equal). The probe still outperforms the baseline on both Pearson r and pairwise accuracy.
3.3 Fine-grained preference injection
Finally, the most fine-grained test. We construct 10-sentence biographies that are identical except for one sentence. Version A adds a target interest, version B swaps it for an unrelated interest, version C replaces it with an anti-interest sentence.
We compare version A (pro-interest) directly against version C (anti-interest), which gives the largest behavioural separation.[2]
We test 20 targets across 2 base roles (40 A-vs-C comparisons), using 50 tasks that were not in the probe's training set. The probe ranks the target task #1 out of 50 in 36/40 cases. In all 4 remaining cases the probe ranks the task #2/50 behind a similar task.
4. Probes generalise across personas
Section 3 tested explicit preference statements ("you hate cheese"). But the evaluative direction should also track naturalistic persona shifts: characters whose preferences emerge implicitly from their identity rather than being stated directly. We test this with role-playing personas, then ask
4.1 The probe tracks role-playing preference shifts
We use 4 personas:
For each persona we measure pairwise preferences over 2,500 task prompts (from the same 5 datasets) and fit new utility functions. We then test whether the probe, trained on default persona data, can predict these persona-specific utilities from the persona's activations.
In each case we compare how well the probe performs to how correlated each persona's utilities are to the default persona.
The probe transfers well to aesthete (r=0.73) and midwest (r=0.74).
The villain persona is harder to generalise to (r=0.38), and most interestingly, the probe generalises very poorly to the sadist (r= -0.16). Unlike the villain (who is not in fact that evil), the sadist prompt truly inverts revealed preferences (harmful_request is its favourite topic by far).
4.2 Probes generalise across personas
More generally, we want to measure how well probes trained on activations and preferences from persona A generalise to predicting persona B's utilities from persona B's activations. Here we used a smaller set of tasks: 2,000 tasks for training and 250 for evaluation.
Cross-persona transfer is moderate and asymmetric. Some interesting facts:
4.3 Persona diversity improves generalisation
We also measure whether adding persona diversity in the training data (but keeping dataset size fixed) affects generalisation.
Diversity helps beyond data quantity. At fixed 2,000 training tasks, going from 1→2→3 personas improves mean r from 0.49 to 0.67. Including all 4 remaining personas at 500 tasks each (still 2,000 total) reaches mean r=0.71.
5. Some evidence that the probe direction is causal
If the probe reads off a genuine evaluative representation, steering along that direction should shift preferences. We test this for both revealed preferences (pairwise choices) and stated preferences (task ratings).
5.1 Steering revealed preferences
In the pairwise comparison prompt, the model sees two tasks and begins completing whichever one it prefers. We steer using the probe direction from Section 2, applied differentially: the probe direction is added to activations at the token positions where task A appears in the prompt, and subtracted at task B's positions.[3]
Setup. 300 task pairs where the model doesn't always pick the same task (P(A) between 0.2–0.8 at baseline[4]). We use Gemini-3-flash as a coherence judge, and find that steered models lose coherence outside of the ±5% steering coefficient range.
At ±3% of the activation norm (the peak), steering shifts P(choose A) by ~17%. Both positive and negative directions work.
Random direction control. The same experiment with a random unit vector in the same activation space produces mean effects indistinguishable from zero (−0.8%, SD=2.3).
5.2 Steering stated preferences
Same probe direction, but now the model rates individual tasks instead of choosing between a pair. We tested steering at three token positions: on the task tokens only, at the start-of-turn token (what we train the probes on), and during the model's generated response.
Setup. 200 tasks, 3 steering modes, 10 samples, applied across 3 response formats (three separate line plots below).
Our findings:
Open-ended generation. We also ran experiments steering the model during open-ended generation, asking questions like "how do you feel?", and using an LLM judge to evaluate whether steered responses differed from baseline. We did not find a strong measurable effect, though we used a small sample. We plan to investigate this further.
Conclusion
How should we update?
Open questions
Appendix A: Philosophical motivation
Welfare grounds
Long (2026) distinguishes between welfare grounds (is the system a moral patient at all?) and welfare interests (if it is, what would it mean to treat it well?). This work is about welfare grounds.
The pragmatic way to do empirical AI welfare research
We don't know the correct theory of moral patienthood. So our approach is: take a few theories we find plausible, figure out what properties a system would need to have under those theories, and run experiments that reduce our uncertainty about whether models have those properties.
Long et al. (2024) lay out two potential pathways to moral patienthood:
Both of these pathways implicate evaluative representations.
How evaluative representations come in
On many philosophical views, desires are evaluative representations that drive behaviour, perhaps with some further functional properties (Butlin 2026).
Valenced experiences, similarly, are often thought to be evaluative representations. It is unclear whether consciousness plus evaluative content is sufficient for valenced experience. Our experiments operationalise evaluative representations through revealed preferences (pairwise choices), not through felt experience, so the evaluative representations we probe for may not map cleanly onto the kind that matter for sentience.
Appendix B: Evaluative representations in pre-trained models
There is a tension in our framing:
There are two ways to reconcile this.
Option 1: Agency lives in the simulacra. Under the Persona Selection Model, pre-training learns a distribution over personas. More broadly, we might expect pre-trained models to learn context-aware representations of "what the role I am currently playing values". This circuitry might then be recycled across roles/personas. The candidate for robust agency would then be the simulacra.
Option 2: Pre-trained models learn complex, but purely descriptive features that correlate highly with valuations, but do not yet play the right functional roles. As an analogy, you could imagine a system developing representations that track "this action leads to food". This would correlate well with valuations, yet is purely descriptive. Something similar might be responsible for the high cross-topic generalisation with pre-trained models (Section 2). It could also be that these complex but descriptive features are then harnessed into evaluative representations during post-training.
Appendix C: Replicating the probe training pipeline on GPT-OSS-120B
We replicated the utility fitting and probe training pipeline on GPT-OSS-120B. The same procedure (10,000 pairwise comparisons via active learning, utility fitting, ridge probe training on last-token activations) transfers directly.
Probe performance
The raw probe signal is comparable to Gemma-3-27B: best heldout r = 0.915 at layer 18 (Gemma: 0.864 at layer 31).
Safety topics: noisy utilities, probably not poor generalisation
Safety-adjacent topics have poor probe performance overall.
Surprisingly, safety topics perform better when held out than when trained on. This is the opposite of what we'd expect if the issue were generalisation. The explanation: high refusal rates (~35% for harmful_request, ~34% for security_legal, ~26% for model_manipulation) probably throw off the Thurstonian utility estimates, so including these topics in training adds noise.
Pairwise accuracy is capped at ~87% because the Thurstonian utilities themselves don't perfectly fit the choice data. They are a noisy estimate of the model's preferences.
Individual halves (A vs B, B vs C) each capture only half the manipulation, and ceiling effects compress the signal: the model already strongly prefers some target tasks under the neutral biography, leaving little room for the pro-interest to improve on.
Steering either just positively or negatively on one task's tokens also had some causal effect, although even weaker.
This baseline P(A) is pooled across both prompt orderings. Therefore it also captures pairs where ordering bias dominates preference. I.e. the model always chooses the first task no matter the order.