Several challenges add friction to finding high signal people and literature:
High status may negatively impact signal.
Exploration can only be done at the edges of my network, e.g. Twitter thread interactions or recommended people to follow, bottlenecked by I don’t know what I don’t know.
Recommendations naturally bias toward popular people.
Even recommended people from a curated following list may be important but low signal, e.g. Sam Altman’s priority is promoting OpenAI products.
Validation - is this information valuable? - is manual vibe check.
We reapply PageRank to Twitter, which naturally weights “important” people higher. If Ilya Sutskever follows only three accounts, a puppy fan page among them, perhaps we should sit up and take notice. The approach is very similar to the existing LessWrong work analyzing AI discourse on Twitter/Bluesky, but instead of categorizing p(doom) discourse, we want to find "important" and “underrated” people.
Approach:
Find important people in the AI Twitter sphere via PageRank
Find the “underrated” people with low follow count from step 1.
Find consistently “high signal” people from step 1 via an LLM.
Six 'famous' users were used to bootstrap PageRank, chosen for high quality public contributions. After a round of convergence, the top ranked handle is added (removing organizations), repeating until we have ~200 "core" handles. Finally, we cut the list down to top 749 and rerun one last time. The full table with additional columns can be found at https://thefourierproject.org/people
Andrej Karpathy, @karpathy, Eureka Labs/Education
Dwarkesh Patel, @dwarkesh_sp, Various topics podcasts
Let’s look at the results! Unsurprisingly, Sam Altman is rank 0, clearly a center of gravity in the field, with other famous people trailing. How do the original 6 rank?
Andrej Karpathy (1)
Dwarkesh Patel (17)
Lilian Weng (46)
Chris Olah (34)
Dylan Patel (174)
Eric Jang (93)
We can also see some well known LessWrong members also in the untruncated ~60,000 list (rankings slightly different).
Ajeya Cotra @ajeya_cotra (194)
Daniel Kokotajlo @DKokotajlo (123)
Eli Lifland @Eli_lifland (1153)
"Underrated" People
"Underrated" handles should have low rank and low follower count, resulting in a high discovery score, where: Discovery Score=749−ranklog2(followers) For example @csvoss is ranked 111 suggesting her importance at OpenAI but “relatively” undiscovered at 12,275 followers.
"High Signal" People
However, high influence or high discovery may not imply high signal. Highly public people cannot tweet freely and everyone has personal interests. To estimate signal with a dystopian approach, we prompt Gemini Flash 3.0 Thinking with each user's 20 most recent tweets and the following:
Are these tweets high signal? I'm sifting for hidden gems on the internet. I am looking for any of the following:
Classic wisdom that has stood the test of time, perceptive and insightful
Novel ideas
Beautiful story about humanity
Genuinely funny jokes/observations
News items opining on the quality of new developments
Critically, the author should not:
Be too emotionally attached and fail to consider things objectively
Display negative financial incentives such as overly selling product or audience emotional vindication
Credentials can be a weak signal, but must be relevant to the topic and are not obsolete or fake. It is extremely critical to discern popularity due to stoking emotions in polarizing topics versus pieces that are actually sharp and high quality. Strongly penalize pieces that rely on emotional manipulation. Think very critically - do not use a categorized points based rubric, consider each tweet holistically.
Given Gemini's love for the term 'smoking gun', see if your taste aligns with its prompted interpretation of high signal, as ratings can vary over different runs. It is potentially useful as a starting point, and a external perspective to force reconsideration when I disagree with it's judgement.
The Lack of Correlation Between Rank and Discovery Lastly, we examine and find that neither rank or discovery score appear to correlate with signal, which suggests that it’s possible that the LLM signal rating is more random, however my personal spot checks (Andrej Karpathy, Lilian Weng, Sam Altman) seem about correct.
Gaps in the approach and possible additional explorations
Twitter API is expensive, so only ~200 core users result in a much sparser graph than reality.
People not as frequently on Twitter e.g. Carl Schulman or general academia are greatly underrepresented.
People may contribute outside Twitter, e.g Jeff Dean has promotion responsibilities but also wrote a very valuable performance hints guide not captured.
The cluster is very AI focused, so Lesswrong members like thiccythot (finance/crypto) are too far.
The cluster is still a form of popular vote, just among "influential" people, and doesn't capture "true" contrarians.
In the future I would like to tackle related fields such as semiconductors, robotics, and security in their separate clusters. If anyone had good bootstrap handles or field prioritization suggestions I would greatly appreciate it.
Cross post, adapted for LessWrong
Several challenges add friction to finding high signal people and literature:
We reapply PageRank to Twitter, which naturally weights “important” people higher. If Ilya Sutskever follows only three accounts, a puppy fan page among them, perhaps we should sit up and take notice. The approach is very similar to the existing LessWrong work analyzing AI discourse on Twitter/Bluesky, but instead of categorizing p(doom) discourse, we want to find "important" and “underrated” people.
Approach:
Six 'famous' users were used to bootstrap PageRank, chosen for high quality public contributions. After a round of convergence, the top ranked handle is added (removing organizations), repeating until we have ~200 "core" handles. Finally, we cut the list down to top 749 and rerun one last time. The full table with additional columns can be found at https://thefourierproject.org/people
"Influential" People
Let’s look at the results! Unsurprisingly, Sam Altman is rank 0, clearly a center of gravity in the field, with other famous people trailing. How do the original 6 rank?
We can also see some well known LessWrong members also in the untruncated ~60,000 list (rankings slightly different).
"Underrated" People
"Underrated" handles should have low rank and low follower count, resulting in a high discovery score, where:
Discovery Score=749−ranklog2(followers)
For example @csvoss is ranked 111 suggesting her importance at OpenAI but “relatively” undiscovered at 12,275 followers.
"High Signal" People
However, high influence or high discovery may not imply high signal. Highly public people cannot tweet freely and everyone has personal interests. To estimate signal with a dystopian approach, we prompt Gemini Flash 3.0 Thinking with each user's 20 most recent tweets and the following:
Are these tweets high signal? I'm sifting for hidden gems on the internet. I am looking for any of the following:
Critically, the author should not:
Credentials can be a weak signal, but must be relevant to the topic and are not obsolete or fake. It is extremely critical to discern popularity due to stoking emotions in polarizing topics versus pieces that are actually sharp and high quality. Strongly penalize pieces that rely on emotional manipulation. Think very critically - do not use a categorized points based rubric, consider each tweet holistically.
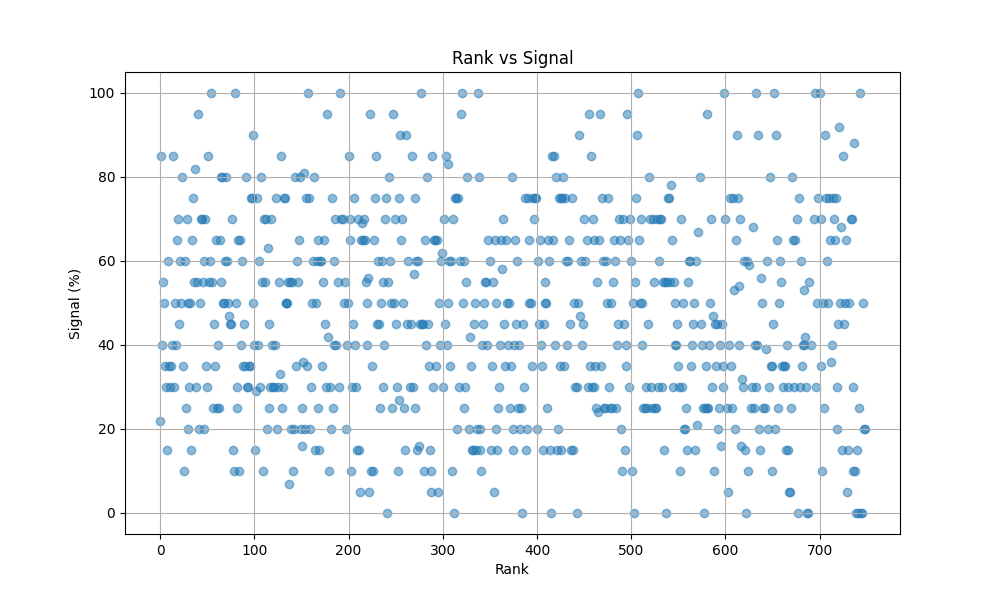
Given Gemini's love for the term 'smoking gun', see if your taste aligns with its prompted interpretation of high signal, as ratings can vary over different runs. It is potentially useful as a starting point, and a external perspective to force reconsideration when I disagree with it's judgement.
The Lack of Correlation Between Rank and Discovery
Lastly, we examine and find that neither rank or discovery score appear to correlate with signal, which suggests that it’s possible that the LLM signal rating is more random, however my personal spot checks (Andrej Karpathy, Lilian Weng, Sam Altman) seem about correct.
Gaps in the approach and possible additional explorations
In the future I would like to tackle related fields such as semiconductors, robotics, and security in their separate clusters. If anyone had good bootstrap handles or field prioritization suggestions I would greatly appreciate it.
Thanks for reading!