This post is a collection of observations around self-supervised learning for vision-based datasets. This is by no means a complete survey of SSL techniques, and assumes familiarity with Contrastive Learning, Masked Image Modeling and Masked AutoEncoder frameworks. For readers intending to get up to speed on these topics, there are excellent resources available online.
Setting
The datasets in the real world are rarely as well-understood and worked upon as academic datasets such as ImageNet-1k. They may have long-tailed distributions and/or high degree of label imbalance for a subset of classes. The labels may be noisy and the image metadata might be missing/unreliable. Further, label collection/verification might be time-consuming and expensive. There might be systematic confounders present in the data. We might be expected to deploy the model in situations where the data distribution might be unknown to us. At the same time, if our model performance on the metrics that we care about degrades, we should be able to correct for that with minimum effort and disruption to our workflows. In this context, we want to harness SSL pretraining (or pre-pretraining) to alleviate the need of labels, generate synthetic data for rare classes and learn rich representations that can be used for a variety of downstream tasks.
Vision datasets can have pervasive label issues (Source)
Contrastive Learning + Masked Image Modeling : Best of both worlds?
Contrastive learning (CL) involves bringing representations of similar samples closer and pushing apart representations of dissimilar samples. Initial methods for CL used a CNN encoder as a feature extractor. The need for positive and negative pairs within the same batch meant that these methods relied on bigger batches and correct assumptions about what constitutes positive and negative examples. Modifications that did not require negative pairs while avoiding the trivial collapsed features as a solution (SimSiam, BYOL, VICReg), and deal with noisy negative examples (RINCE loss) were suggested. With the advent of ViT, new approaches that integrate ViT into the SSL framework were designed. Works such as Park et al cover the difference between the properties of multi-head self-attention (MHSA) used in ViT and CNNs - MHSA are low-pass filters and shape-biased, while convolutions are high-pass filters and texture-biased. There is also literature that suggests that the patchify operation is the key behind ViT’s performance. Interestingly, there is work in both directions - replacing patchify with convolution to improve training stability and performance and using patchify stem in CNN. While a natural next step is to swap out CNN with ViT in the CL training pipeline, other works like DINO employ self-distillation to achieve impressive zero-shot results on segmentation & detection. Multi-view hypothesis explains the adaptability of these features by stating that self-distillation performs implicit ensembling and promotes learning of multiple concepts. Other popular methods continue using the distillation framework - iBOT employs masked image modeling (MIM) to learn patch level features, along with applying distillation on the CLS tokens; and DINOv2 combines this loss with the DINO loss. Finally, Park et al compare the pros and cons of CL and MIM. The authors also suggest a linear combination of these 2 losses as outperforming the individual components.
Comparison between Contrastive Learning and Masked Image Modeling (Source)
Link between temperature and number of classes
In CL, the temperature term serves to sharpen the output values, with a temperature -> 0 corresponding to one-hot representations. The gradient term of the loss shows that lower values of temperature lead to higher penalty values for hard-negative examples.
Different contrastive losses and the impact of temperature on loss gradients (Source)
Temperature is a crucial parameter, with CL based methods demonstrating a dramatic sensitivity to its values. DINO, for example, uses different temperature values and schedules for its student and teacher networks. Works such as F Wang et al, T Wang et al discuss the impact of temperature on the learnt representations through 2 properties - uniformity in the hypersphere which enables the learnt features to be separable, and tolerance to potential positive examples. Lower values of temperature focus on the former, thus they make more sense for datasets with larger number of classes like ImageNet, where the probability of getting a lot of potential positives in a training batch are low. By extension, the probability of getting more potential positives increases with fewer classes, thus lower values of temperature are not as beneficial. Thus, it is important to consider the number of classes for downstream tasks while picking a value for temperature.
Comparison of model performance at different temperatures, lower temperatures work better for datasets with larger number of classes (Source)
Augmentations
Augmentations are important in terms of deciding the invariances of the learnt representations. A key augmentation for both CL and MIM based methods is cropping. SimCLR mentions the importance of local crops + color jitter to learn how to predict neighboring views while avoiding trivial solutions like matching color histograms. Similarly, DINO passes only the local crops through the student and all crops through the teacher to learn ‘global-to-local’ correspondences. The best results are obtained with a relative local crop size of (0.05, 0.32) for both iBOT and DINO, and these trends are consistent for images which may not have a central object of interest.
Projector and invariance to augmentations
The importance of projector has been recognized since SimCLR, where adding a MLP projection head and then using the input features instead of outputs improves performance on downstream tasks by >10%. Guillotine regularization formulates this as a generic last k-layers removal task, and highlight the importance of removing more layers when there is a misalignment in terms of downstream prediction task/data distribution. Gupta et al posits that the projector learns a feature subspace to apply contrastive loss, thus preventing the backbone features (i.e, input to projector) to be augmentation-invariant (augmentations can be sub-optimal for certain tasks). This means those representations can align better to a wider range of downstream tasks. This might also explain why CLIP training relies on a linear projector and uses only a random crop as an augmentation, since the training set size is order of magnitudes larger and the aim is to learn generalizable features.
Extension to tasks beyond classification
Vanilla CL operates on flattened 1-d features and does not have any explicit spatial understanding baked in. Chen et al showed that CL learns features of only the dominant object or easy-to-learn features at the expense of other information in the image, which can be detrimental to certain tasks. Modifications to CL have been suggested that apply losses to the dense feature vectors and use location-based matching along with feature matching to yield local features that are invariant to the given transformations (VicRegL). ViT based approaches meanwhile, by virtue of their design choice, focus on smaller patches within an image and use positional embeddings. Indeed, features from DINO describe object boundaries without any supervision, and Park et al show that CL works well for linear probing and classification tasks with smaller models, whereas MIM outperforms CL in fine-tuning and dense prediction tasks with larger models.
Contrastive Learning can suffer from feature suppression among competing features, leading the model to learn only the dominant or easy features (Source)
Pretraining and downstream task alignment
Practitioners often care about deploying models with satisfactory performance on different tasks with low investment in terms of time/effort/resources. Performance of SSL pretrained embeddings on downstream tasks can depend on different factors. Cole et al study this for CL with CNN encoders on classification tasks. They find that while these representations can be effective for in-domain downstream tasks, they can suffer a degradation in performance when the domain is OOD, the downstream task is fine-grained (more number of classes) or the data has undergone specific transformations.
Different factors can influence the performance of pretrained backbones on downstream tasks (Source)
Regarding imbalanced classification, the jury is divided - Assran et al mention that SSL methods place a uniform prior on the data and thus underperform on unbalanced datasets, while Liu et al state that SSL enables the model to better learn the intrinsic structures in the data (aka multi-view hypothesis) which translates to better performance on rare classes. Although not self-supervised, works such as Wang et al, Juyal et al demonstrate improvements on long-tailed and imbalanced datasets with a gradual weight transfer from supervised contrastive loss to cross-entropy at training time.
How do different SSL compare with each other and with supervised training in terms of transfer learning performance, and how do they depend on the amount and diversity of pre-training data? Works such as Entezari et al, Goldblum et al aim to answer such questions. They findings include: CNNs pertained on large supervised datasets can outperform SSL methods, including more data for both pretraining and fine-tuning can offset the performance gap, and ViTs benefit more than CNNs both in terms of model and data scaling. DINOv2 also emphasizes the importance of collecting a well-curated, diverse dataset for model performance. Finally, the top-performing backbones are universally performant across multiple tasks, providing evidence for a foundation backbone catering to a wide range of use-cases.
This post is a collection of observations around self-supervised learning for vision-based datasets. This is by no means a complete survey of SSL techniques, and assumes familiarity with Contrastive Learning, Masked Image Modeling and Masked AutoEncoder frameworks. For readers intending to get up to speed on these topics, there are excellent resources available online.
Setting
The datasets in the real world are rarely as well-understood and worked upon as academic datasets such as ImageNet-1k. They may have long-tailed distributions and/or high degree of label imbalance for a subset of classes. The labels may be noisy and the image metadata might be missing/unreliable. Further, label collection/verification might be time-consuming and expensive. There might be systematic confounders present in the data. We might be expected to deploy the model in situations where the data distribution might be unknown to us. At the same time, if our model performance on the metrics that we care about degrades, we should be able to correct for that with minimum effort and disruption to our workflows. In this context, we want to harness SSL pretraining (or pre-pretraining) to alleviate the need of labels, generate synthetic data for rare classes and learn rich representations that can be used for a variety of downstream tasks.
Vision datasets can have pervasive label issues (Source)
Contrastive Learning + Masked Image Modeling : Best of both worlds?
Contrastive learning (CL) involves bringing representations of similar samples closer and pushing apart representations of dissimilar samples. Initial methods for CL used a CNN encoder as a feature extractor. The need for positive and negative pairs within the same batch meant that these methods relied on bigger batches and correct assumptions about what constitutes positive and negative examples. Modifications that did not require negative pairs while avoiding the trivial collapsed features as a solution (SimSiam, BYOL, VICReg), and deal with noisy negative examples (RINCE loss) were suggested. With the advent of ViT, new approaches that integrate ViT into the SSL framework were designed. Works such as Park et al cover the difference between the properties of multi-head self-attention (MHSA) used in ViT and CNNs - MHSA are low-pass filters and shape-biased, while convolutions are high-pass filters and texture-biased. There is also literature that suggests that the patchify operation is the key behind ViT’s performance. Interestingly, there is work in both directions - replacing patchify with convolution to improve training stability and performance and using patchify stem in CNN. While a natural next step is to swap out CNN with ViT in the CL training pipeline, other works like DINO employ self-distillation to achieve impressive zero-shot results on segmentation & detection. Multi-view hypothesis explains the adaptability of these features by stating that self-distillation performs implicit ensembling and promotes learning of multiple concepts. Other popular methods continue using the distillation framework - iBOT employs masked image modeling (MIM) to learn patch level features, along with applying distillation on the CLS tokens; and DINOv2 combines this loss with the DINO loss. Finally, Park et al compare the pros and cons of CL and MIM. The authors also suggest a linear combination of these 2 losses as outperforming the individual components.
Comparison between Contrastive Learning and Masked Image Modeling (Source)
Link between temperature and number of classes
In CL, the temperature term serves to sharpen the output values, with a temperature -> 0 corresponding to one-hot representations. The gradient term of the loss shows that lower values of temperature lead to higher penalty values for hard-negative examples.
Different contrastive losses and the impact of temperature on loss gradients (Source)
Temperature is a crucial parameter, with CL based methods demonstrating a dramatic sensitivity to its values. DINO, for example, uses different temperature values and schedules for its student and teacher networks. Works such as F Wang et al, T Wang et al discuss the impact of temperature on the learnt representations through 2 properties - uniformity in the hypersphere which enables the learnt features to be separable, and tolerance to potential positive examples. Lower values of temperature focus on the former, thus they make more sense for datasets with larger number of classes like ImageNet, where the probability of getting a lot of potential positives in a training batch are low. By extension, the probability of getting more potential positives increases with fewer classes, thus lower values of temperature are not as beneficial. Thus, it is important to consider the number of classes for downstream tasks while picking a value for temperature.
Comparison of model performance at different temperatures, lower temperatures work better for datasets with larger number of classes (Source)
Augmentations
Augmentations are important in terms of deciding the invariances of the learnt representations. A key augmentation for both CL and MIM based methods is cropping. SimCLR mentions the importance of local crops + color jitter to learn how to predict neighboring views while avoiding trivial solutions like matching color histograms. Similarly, DINO passes only the local crops through the student and all crops through the teacher to learn ‘global-to-local’ correspondences. The best results are obtained with a relative local crop size of (0.05, 0.32) for both iBOT and DINO, and these trends are consistent for images which may not have a central object of interest.
Projector and invariance to augmentations
The importance of projector has been recognized since SimCLR, where adding a MLP projection head and then using the input features instead of outputs improves performance on downstream tasks by >10%. Guillotine regularization formulates this as a generic last k-layers removal task, and highlight the importance of removing more layers when there is a misalignment in terms of downstream prediction task/data distribution. Gupta et al posits that the projector learns a feature subspace to apply contrastive loss, thus preventing the backbone features (i.e, input to projector) to be augmentation-invariant (augmentations can be sub-optimal for certain tasks). This means those representations can align better to a wider range of downstream tasks. This might also explain why CLIP training relies on a linear projector and uses only a random crop as an augmentation, since the training set size is order of magnitudes larger and the aim is to learn generalizable features.
Extension to tasks beyond classification
Vanilla CL operates on flattened 1-d features and does not have any explicit spatial understanding baked in. Chen et al showed that CL learns features of only the dominant object or easy-to-learn features at the expense of other information in the image, which can be detrimental to certain tasks. Modifications to CL have been suggested that apply losses to the dense feature vectors and use location-based matching along with feature matching to yield local features that are invariant to the given transformations (VicRegL). ViT based approaches meanwhile, by virtue of their design choice, focus on smaller patches within an image and use positional embeddings. Indeed, features from DINO describe object boundaries without any supervision, and Park et al show that CL works well for linear probing and classification tasks with smaller models, whereas MIM outperforms CL in fine-tuning and dense prediction tasks with larger models.
Contrastive Learning can suffer from feature suppression among competing features, leading the model to learn only the dominant or easy features (Source)
Pretraining and downstream task alignment
Practitioners often care about deploying models with satisfactory performance on different tasks with low investment in terms of time/effort/resources. Performance of SSL pretrained embeddings on downstream tasks can depend on different factors. Cole et al study this for CL with CNN encoders on classification tasks. They find that while these representations can be effective for in-domain downstream tasks, they can suffer a degradation in performance when the domain is OOD, the downstream task is fine-grained (more number of classes) or the data has undergone specific transformations.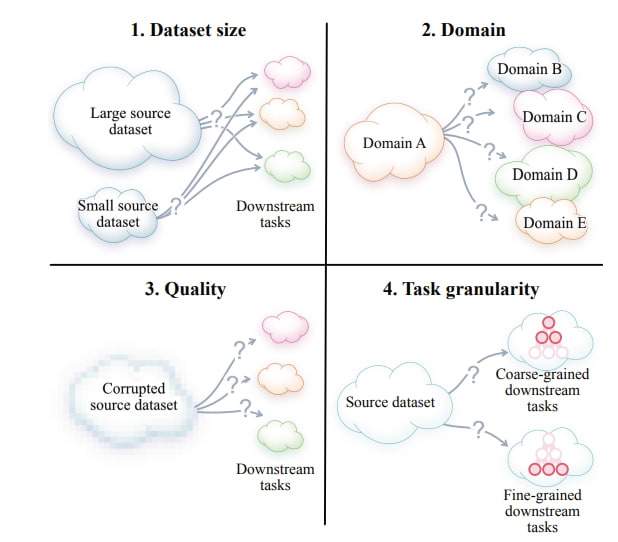
Different factors can influence the performance of pretrained backbones on downstream tasks (Source)
Regarding imbalanced classification, the jury is divided - Assran et al mention that SSL methods place a uniform prior on the data and thus underperform on unbalanced datasets, while Liu et al state that SSL enables the model to better learn the intrinsic structures in the data (aka multi-view hypothesis) which translates to better performance on rare classes. Although not self-supervised, works such as Wang et al, Juyal et al demonstrate improvements on long-tailed and imbalanced datasets with a gradual weight transfer from supervised contrastive loss to cross-entropy at training time.
How do different SSL compare with each other and with supervised training in terms of transfer learning performance, and how do they depend on the amount and diversity of pre-training data? Works such as Entezari et al, Goldblum et al aim to answer such questions. They findings include: CNNs pertained on large supervised datasets can outperform SSL methods, including more data for both pretraining and fine-tuning can offset the performance gap, and ViTs benefit more than CNNs both in terms of model and data scaling. DINOv2 also emphasizes the importance of collecting a well-curated, diverse dataset for model performance. Finally, the top-performing backbones are universally performant across multiple tasks, providing evidence for a foundation backbone catering to a wide range of use-cases.