Here's another idea that is not quite there but could be a component of a solution here:
- If a red-team finds some particular model failure (or even some particular benign model behavior), can you fix (or change/remove) that behavior exclusively by removing training data rather than adding it? Certainly I expect it to be possible to fix specific failures by fine-tuning on them, but if you can demonstrate that you can fix failures just by removing existing data, that demonstrates something meaningful about your ability to understand what your model is learning from each data point that it sees.
Assuming we're working with near-frontier models (s.t., the cost of training them once is near the limit of what any institution can afford), we presumably can't actually retrain a model without the data. Are there ways to approximate this technique that preserve its appeal?
(Just to check my understanding, this would be a component of a sufficient-but-not-necessary solution, right?)
Yep, seems too expensive to do literally as stated, but right now I'm just searching for anything concrete that would fit the bill, regardless of how practical it would be to actually run. If we decided that this was what we needed, I bet we could find a good approximation, though I don't have one right now.
And I'm not exactly sure what part of the solution this would fill—it's not clear to me whether this alone would be either sufficient or necessary. But it does feel like it gives you real evidence about the degree of understanding that you have, so it feels like it could be a part of a solution somewhere.
Another thought here:
- If we're in a slow enough takeoff world, maybe it's fine to just have the understanding standard here be post-hoc, where labs are required to be able to explain why a failure occurred after it has already occurred. Obviously, at some point I expect us to have to deal with situations where some failures could be unrecoverable, but the hope here would be that if you can demonstrate a level of understanding that has been sufficient to explain exactly why all previous failures occurred, that's a pretty high bar, and it could plausibly be a high enough bar to prevent future catastrophic failures.
Thanks to Chris Olah for a helpful conversation here.
Some more thoughts on this:
- One thing that seems pretty important here is to have your evaluation based around worst-case rather than average-case guarantees, and not tied to any particular narrow distribution. If your mechanism for judging understanding is based on an average-case guarantee over a narrow distribution, then you're sort of still in the same boat as you started with behavioral evaluations, since it's not clear why understanding that passes such an evaluation would actually help you deal with worst-case failures in the real world. This is highly related to my discussion of best-case vs. worst-case transparency here.
- Another thing worth pointing out here regarding using causal scrubbing for something like this is that causal scrubbing requires some base distribution that you're evaluating over, which means it could fall into a similar sort of trap to that in the first bullet point here. Presumably, if you wanted to build a causal-scrubbing-based safety evaluation, you'd just use the entire training distribution as the distribution you were evaluating over, which seems like it would help a lot with this problem, but it's still not completely clear that it would solve it, especially if you were just evaluating your average-case causal scrubbing loss over that distribution.
Causal Scrubbing: My main problem with causal scrubbing as a solution here is that only guarantees the sufficiency, but not the necessity, or your explanation. As a result, my understanding is that a causal-scrubbing-based evaluation would admit a trivial explanation that simply asserts that the entire model is relevant for every behavior.
Redwood has been experimenting with learning (via gradient descent) causal scrubbing explanations that are somewhat addressing your necessity point. Specifically:
- "Larger" explanations are penalized more (size refers to the number of dimensions of the residual stream the explanation claims the model is using for a specific behavior).
- Explanations must be adversarially robust: an adversary shouldn't be able to include additional parts of the model we claimed are unimportant and have a sizable effect on the scrubbed model's predictions.
This approach doesn't address all the concerns one might have with using causal scrubbing to understand models, but just wanted to flag that this is something we're thinking about as well.
My summary:
Evan expresses pessimism about our ability to use behavioral-based evaluations (like the capabilities evals ARC did for GPT-4) to test for alignment properties in the future. Detecting for alignment may be quite hard because you might be up against a highly capable adversary that is trying to evade detection; this might even be harder than training an aligned system to begin with. A model will struggle to fake its capabilities after specific fine tuning (requires advanced gradient hacking), but faking alignment properties seems much easier.
Due to behavioral-evals struggling to detect deception, AI labs widely adopting a safety framework like behavioral-evaluations from external auditors (without access to checkpoints/transparency) might make it very hard to detect deception in the future.
Evan suggests pairing capabilities-evaluations with understanding-based evals. These understanding-evals would focus on how well we can predict models’ behavior, but of course it’s hard to define what this means. [edited in response to Evan's comment:] These understanding-evals would focus on how well developers understand the models they're creating, but of course it’s hard to define what it means to have such an understanding. "Rather than evaluating a final model, an understanding-based evaluation would evaluate the developer's ability to understand what sort of model they got and why they got it." Desiderata for these evals including being method-agnostic and having a high enough level of understanding to detect dangerous failures. Potential strategies to build off: causal scrubbing, auditing games, prediction-based evaluation, fixing behavior via removing data from training rather than adding it; Evan talks about ways in which each of these is insufficient currently.
At first I was confused about why faking capabilities will be harder than faking alignment. After thinking, here’s my explanation:
When we fine-tune on specific capabilities, we will have gradients pushing toward the model improving on these capabilities (unless your model is gradient hacking). These gradient updates are likely to lead to eliciting all of the possible capabilities of your model (with enough fine-tuning). There is a capabilities ground truth being trained against. A deceptively aligned model may try to hide its maximum capabilities, but there are strong gradients pushing against this unless it is gradient hacking.
On the other hand, faking alignment is much easier. When you’re a deceptively aligned model acting aligned during training, there’s no training signal smacking you in a different direction, you’re doing great on those alignment benchmarks. Being deceptively aligned implies that your model is instrumentally pursuing the training objective, so gradients don't affect its mesa-objective. Beyond this “you’re doing just as well as an aligned model” problem, we also don’t have a reliable ground truth alignment measure to even be doing this fine-tuning on, like we do for capabilities.
Thanks, Gabe, for this simple framing: Acting aligned gets low loss, whereas acting dumb (incapable) gets high loss, in the fine-tuning.
This looks basically right, except:
These understanding-evals would focus on how well we can predict models’ behavior
I definitely don't think this—I explicitly talk about my problems with prediction-based evaluations in the post.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
I have a pretty fundamental concern with these sorts of techniques as a mechanism for eventually assessing alignment
that would lead to safety or alignment goodharting problem.
It sounds like you want some formalisation of theory/model selection in science, i.e., a formalisation of epistemology.
"It's very unclear what it would look like to be able to prove that you understand your model" -- in this phrase, the word "prove" rings a bell for me, because since Popper we know that there are only falsifications in science but not proofs.
Formalisation of science cannot escape also "solving" cognitive science, because science is something scientists do. But here, I think there is no way to escape model subjectivity. When you apply a certain framework to understand the AI model, you should also apply it, reflectively, to oneself. This is the "meta-theoretical move". E.g., (inverse) RL framework is doing it. Free Energy Principle, too ("On the Map-Territory Fallacy Fallacy"). There may be some formal ways to map between RL and FEP using category theory, but this isn't a priori true for any other theory of cognition whatsoever.
FEP literature asserts that it's a "canonical" approach to modelling intelligence because it recovers maximum-entropy posterior expectation of behaviour. However, by construction, this is a story of inductivism and instrumentalism and thus doesn't deal with out-of-distribution generalisation (or, one can say, deals with OoD generalisation in an average case rather than worst case way).
Thank you so much for sharing this extremely insightful argument, Evan! I really appreciate hearing your detailed thoughts on this.
I've been grappling with the pros and cons of an atheoretical-empirics-based approach (in your language, "behavior") and a theory-based approach (in your language, "understanding") within the complex sciences, such as but not limited to AI. My current thought is that unfortunately, both of the following are true:
1) Findings based on atheoretical empirics are susceptible to being brittle, in that it is unclear whether or in precisely which settings these findings will replicate. (e.g., see "A problem in theory" by Michael Muthukrishna and Joe Henrich: https://www.nature.com/articles/s41562-018-0522-1)
2) While theoretical models enable one to meaningfully attempt predictions that extrapolate outside of the empirical sample, these models can always fail, especially in the complex sciences. "There is no such thing as a validated predictive model" (https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-023-02779-w).
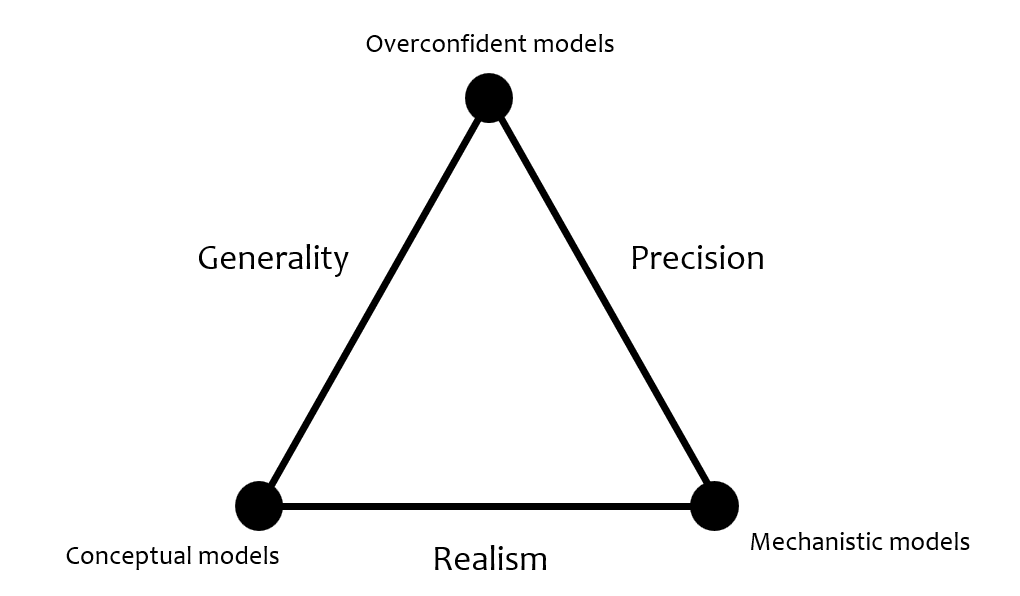
A common difficulty that theory-based predictions out-of-distribution run into is the tradeoff between precision and generality. Levin (https://www.jstor.org/stable/27836590) described this idea by saying that among three desirable properties---generality, precision, and realism---a theory can only simultaneously achieve two. The following is Levin's triangle:
Thanks to Kate Woolverton, Ethan Perez, Beth Barnes, Holden Karnofsky, and Ansh Radhakrishnan for useful conversations, comments, and feedback.
Recently, I have noticed a lot of momentum within AI safety specifically, the broader AI field, and our society more generally, towards the development of standards and evaluations for advanced AI systems. See, for example, OpenAI's GPT-4 System Card.
Overall, I think that this is a really positive development. However, while I like the sorts of behavioral evaluations discussed in the GPT-4 System Card (e.g. ARC's autonomous replication evaluation) as a way of assessing model capabilities, I have a pretty fundamental concern with these sorts of techniques as a mechanism for eventually assessing alignment.[1]
I often worry about situations where your model is attempting to deceive whatever tests are being run on it, either because it's itself a deceptively aligned agent or because it's predicting what it thinks a deceptively aligned AI would do. My concern is that, in such a situation, being able to robustly evaluate the safety of a model could be a more difficult problem than finding training processes that robustly produce safe models. For some discussion of why I think checking for deceptive alignment might be harder than avoiding it, see here and here. Put simply: checking for deception in a model requires going up against a highly capable adversary that is attempting to evade detection, while preventing deception from arising in the first place doesn't necessarily require that. As a result, it seems quite plausible to me that we could end up locking in a particular sort of evaluation framework (e.g. behavioral testing by an external auditor without transparency, checkpoints, etc.) that makes evaluating deception very difficult. If meeting such a standard then became synonymous with safety, getting labs to actually put effort into ensuring their models were non-deceptive could become essentially impossible.
However, there's an obvious alternative here, which is building and focusing our evaluations on our ability to understand our models rather than our ability to evaluate their behavior. Rather than evaluating a final model, an understanding-based evaluation would evaluate the developer's ability to understand what sort of model they got and why they got it. I think that an understanding-based evaluation could be substantially more tractable in terms of actually being sufficient for safety here: rather than just checking the model's behavior, we're checking the reasons why we think we understand its behavior sufficiently well to not be concerned that it'll be dangerous.
It's worth noting that I think understanding-based evaluations can—and I think should—go hand-in-hand with behavioral evaluations. I think the main way you’d want to make some sort of understanding-based standard happen would be to couple it with a capability-based evaluation, where the understanding requirements become stricter as the model’s capabilities increase. If we could get this right, it could channel a huge amount of effort towards understanding models in a really positive way.
Understanding as a safety standard also has the property that it is something that broader society tends to view as extremely reasonable, which I think makes it a much more achievable ask as a safety standard than many other plausible alternatives. I think ML people are often Stockholm-syndrome'd into accepting that deploying powerful systems without understanding them is normal and reasonable, but that is very far from the norm in any other industry. Ezra Klein in the NYT and John Oliver on his show have recently emphasized this basic point that if we are deploying powerful AI systems, we should be able to understand them.
One of the main problems here, however, is purely technical: it's very unclear what it would look like to be able to prove that you understand your model, which is obviously a major blocker for any attempt to build some sort of an evaluation around understanding. What we need, therefore, is some way of formalizing what it would mean to demonstrate that you understand some model. Some desiderata for what something like this would have to look like:
Overall, I think working on producing a way of evaluating understanding that satisfies these desiderata seems like an extremely critical open problem to me. If we could channel the asks of society and the efforts of big AI labs into understanding models in a rigorous way, we could shape a lot more safety research than we have the ability to do ourselves, and point it directly at what I see as the core problem of us not understanding the models that we are building.
I think it's also worth pointing out that there are some existing techniques that currently seem insufficient to me here, but could potentially be used as a basis for something like this:
Finally, I think it's also worth noting here that I don't want to replace behavioral safety standards entirely. I definitely think that there is a place for behavioral red-teaming as a way to catch many different sorts of model failures, including potentially some situations where you have a deceptively aligned model. Such evaluations could be especially useful early on as a way to find the first example of a deceptively aligned model, which could then be studied extensively. My point is only that such evaluations are insufficient on their own and need to be coupled with some sort of understanding-based standard if they are to actually be sufficient to guarantee safety into regimes where deceptive models could be highly capable at hiding their deception.
Edit: See these follow-up comments for some more of my thoughts here.
That's because while I think it would be quite tricky for a deceptively aligned AI to sandbag its capabilities when explicitly fine-tuned on some capabilities task (that probably requires pretty advanced gradient hacking), it should be quite easy for such a model to pretend to look aligned.