In this paper, we set out to empirically map the evolution of the AI risk discourse on LessWrong, specifically in response to the public releases of ChatGPT and GPT-4. These events represented a significant shift, moving advanced AI from a theoretical concern to a tangible, publicly accessible technology. Our central research question was: How is the AI risk discourse on this forum constructed, and how did its thematic composition change during this pivotal period?
To answer this, we conducted a two-phase analysis of 884 posts published under the "ai-risk" and "alignment" tags in the year before and after ChatGPT's release. First, through a qualitative reading of the posts, we identified two primary, coexisting framings of risk. We termed the first "abstract AI risk," which encompasses the rationalist-philosophical discourse on future, decisive threats, such as those from an unaligned superintelligence or instrumental convergence—the classic "paperclips" scenario. The second we termed "tangible AI risk," which uses a more empirical-scientific style to discuss the immediate, accumulative threats posed by the misuse of current systems, such as bad actors creating malware or "bombs."
In the second phase, we used these qualitative findings to develop and validate a computational text classifier. This tool allowed us to analyse the entire dataset and quantitatively measure the prevalence of each risk framing over time. Our analysis revealed a statistically significant shift in the community's focus. Following the release of ChatGPT, the discourse reoriented robustly toward tangible risks. The release of GPT-4 continued this trend, albeit with a smaller effect. Crucially, our analysis of author activity shows that this was not the result of a community fragmenting into ideological camps. Instead, most authors engage across the full spectrum of risk, indicating a shared discourse that collectively rebalanced its attention.
In essence, this research provides a data-driven account of how the LessWrong community responded to concrete technological progress. The forum did not abandon its foundational concern with long-term existential risk, but pragmatically shifted its focus from what is theoretically possible toward what is demonstrably real.
Introduction
The rapid development of artificial intelligence (AI) has made the technology a central topic of public debate, generating significant discussion about the potential risks associated with its advancement. A prominent line of argument warns that creating an Artificial General Intelligence (AGI) could trigger an existential catastrophe for humanity (Bostrom, 2014). This perspective has gained traction and is endorsed by leading experts, such as Geoffrey Hinton, emphasising the "existential threat that will arise when we create digital beings that are more intelligent than ourselves," warning that "we have no idea whether we can stay in control." (Hinton, 2024)
While this discourse has a long history, recent advances in Large Language Models (LLMs), particularly OpenAI's ChatGPT and subsequently GPT-4, have represented a major change in the field of AI (OpenAI, 2022; OpenAI et al., 2024). These advancements had two major impacts this paper wants to focus on: they introduced advanced AI to the public, broadening the risk discourse, and they empirically validated neural scaling laws (Kaplan et al., 2020). For many in the field, this provided a more concrete pathway toward AGI, which in turn appears to have intensified existential risk concerns. The growing audience and increasing concerns about possible AGI timelines provide an opportunity to investigate how these shifts influenced the AI risk debates. A prominent place to explore AI risk discussions is the forum LessWrong (Ruby et al., 2019). Despite its influence, LessWrong has received limited academic attention, making this analysis valuable for understanding how its engaged community responds to technological and social changes.
This study aims to investigate how the AI risk discourse is constructed and how it transforms on the LessWrong forum following these major AI developments. To guide this inquiry, our overarching research question asks:
RQ1: How is the AI risk discourse on LessWrong constructed, and how did its thematic composition change in the periods surrounding the releases of ChatGPT and GPT-4?
To answer this, we pursue two sub-questions. The first investigates the qualitative nature of the discourse, asking:
RQ2: What are the primary framings of AI risk within the LessWrong discourse, and how do they conceptualise risk differently?
The second quantitatively addresses changes in the popularity of these framings, asking:
RQ3: To what extent did the proportional focus on tangible versus abstract AI risk on LessWrong differ between the periods before and after the releases of ChatGPT and GPT-4?
To address these questions, this paper employs a sequential mixed-methods design (Frederiksen et al., 2023). First, a qualitative analysis develops an interpretive understanding of the community's risk framings, which then informs a computer-assisted classification to measure discursive shifts.
Background
Central to concerns over advanced AI is the "alignment problem", the challenge of ensuring that autonomous AI systems pursue goals compatible with human values (Russell, 2019). This is not a new concern; the theoretical foundations of AI alignment have been developed over decades by researchers and theorists such as Eliezer Yudkowsky (2001), Steve Omohundro (2008), and Nick Bostrom (2012).
LessWrong was founded by AI safety theorist Eliezer Yudkowsky, and for over a decade, the forum has served as a primary hub for this discourse (Ruby et al., 2019), attracting a dedicated community of researchers, developers, and enthusiasts (McLean, 2024). The platform's emphasis on detailed argumentation and its focus on rationality make it a valuable site for understanding how AI risk concerns are constructed (Ruby et al., 2019). Compared to platforms like Reddit or X, LessWrong's depth and structure, facilitating reasoned argumentation, make it especially well-suited for this research.
Based on the 2023 LessWrong Community Survey Results (Screwtape, 2024), the community consists primarily of young, highly educated technology professionals. The sample included 558 respondents, representing a small portion of active users, as LessWrong currently has close to 1.7 million monthly visits (Similarweb, 2025). Despite the low response rate, the available data still provides valuable, albeit imperfect, insight into the community's demographics. The median age is 29, and the population is overwhelmingly male (89.3% assigned male at birth), predominantly white (78.9%), and based in the United States (49.6%). The community is exceptionally well-educated, with 67.3% holding a bachelor's degree or higher. Professionally, over half of the people work in computing fields (56.5%), while politically, they lean toward progressive-libertarian and are overwhelmingly secular (67.1% atheist). Interestingly, the site members have an average IQ of 134; however, this figure is based on a small, self-selected sample (25% of respondents), making it unrepresentative of the entire community. Lastly, they demonstrate high engagement with rationalist content, as 63.9% embrace consequentialist ethics.
The forum's culture is reinforced by its design. Moderators manually review all first-time contributions for quality and alignment with community standards, a form of gatekeeping that deters low-effort content while filtering for epistemic rigour (Ruby et al., 2019). Furthermore, posts and comments are subject to a karma system where users upvote or downvote content. Vote strength increases with a user's prior karma, giving experienced members greater influence over what becomes visible on the platform. By rewarding clarity and rational engagement, the karma system actively promotes high-effort contributions and reinforces the community's core epistemic norms, such as intellectual humility, the charitable interpretation of opposing arguments, and the use of probabilistic reasoning (lsusr, 2020).
Theoretical Framework
The purpose of the following theory section is to provide a layered framework that allows us to analyse the discourse on LessWrong. Consequently, the theory is used to contextualise the data site’s idea of risk and understand the discourse’s internal logic.
Beck's World Risk Society: A Way to Understand Technological Uncertainty
Ulrich Beck’s theory of the "world risk society" provides a broad context for understanding contemporary discussions about technological threats. Beck (2006) argues that advanced modern societies are increasingly preoccupied with managing "manufactured uncertainties", risks that are the unintended consequences of their own technological and industrial activities. A key characteristic of these risks is that their full impact is often incalculable, transcending the predictive capacities of conventional scientific assessment. Risk definitions, therefore, emerge from a complex social process of deliberation and contestation. Because risks are often delocalised (i.e., transcend national borders), institutions lack the tools to manage them, leaving the risk to be governed by individuals.
From this perspective, the LessWrong forum can be understood as a site where such a process unfolds. Especially when Beck’s idea of risk, as global and often irreversible events, is included. Beck’s concepts, including the global and irreversible nature of potential harms, provide a vocabulary to describe the conditions that animate the AI risk discourse.
Clarke's Possibilism: The possibility of Worst-Cases
While Beck situates a societal context, Clarke’s (2006) work on "possibilistic thinking" offers a framework for analysing the specific mode of reasoning often employed in risk discussions. Clarke distinguishes probabilistic thinking (which focuses on the statistical likelihood of an event) and possibilistic thinking (which focuses on the consequences of what is possible). Possibilism’s relevance for new technologies lies in its ability to shift the analytical focus from an event’s statistical likelihood to the magnitude of its potential consequences.
This lens allows us to analyse the community's focus on high-impact scenarios not as a judgment on probability, but as a distinct form of reasoning.
Kasirzadeh's Typology: A Vocabulary for Mapping Risk Scenarios
To conduct a granular analysis of the discourse content itself, we utilise Kasirzadeh's (2025) distinction between two primary pathways of AI existential risk (AI x-risk). This framework separates scenarios of decisive AI x-risk, referring to an abrupt and catastrophic event like the creation of an uncontrollable superintelligence, and accumulative AI x-risk, referring to a more gradual process, where systemic and societal resilience is destroyed through numerous AI-induced disruptions, leading to an eventual collapse.
This typology serves as a concrete analytical tool. It provides a precise vocabulary for categorising and mapping AI risks discussed on LessWrong.
Design
This study employs a sequential, complementary mixed-methods research design to investigate the construction and evolution of AI risk discourse on LessWrong (Frederiksen et al., 2023). The design is intended to first build a qualitative understanding of the community's framings that will guide a subsequent large-scale computational analysis. This approach aligns with the Computer-Assisted Learning and Measurement (CALM) framework, where computational tools support both exploration and measurement, while human interpretation remains central to developing and validating theory (Carlsen & Ralund, 2022).
The research is organised into three distinct but interconnected phases, each designed to address a specific research question. The overall design logic is visualised in Figure 1 below.
Figure 1
The sequential mixed-methods research design.
Note. Each phase of the research builds on the previous one. The design begins with an inductive, qualitative exploration to generate theory and interpretive categories. These categories then form the basis for a deductive, large-scale quantitative analysis to measure trends, with the final phase synthesising both data types.
Phase 1: Qualitative Immersion and Thematic Discovery (Answering RQ2)
The initial phase is a qualitative exploration designed to understand the core themes and argumentative styles that constitute AI risk discourse on LessWrong. This phase begins with a netnographic immersion into the community, involving in-depth reading of posts and immersion journaling to understand the platform’s culture, norms, and specialised language (Kozinets, 2019). Following initial familiarisation, we conduct an exploratory analysis using topic modelling (BERTopic), with thematic clusters derived via HDBSCAN, to map the discourse. This allows for a data-driven selection of posts for a fine-grained grounded theory coding process (Glaser & Strauss, 1967). Through open coding, followed by focused coding, on a sampled set of posts, this phase will produce a set of analytical categories that capture the distinct ways the community frames AI risk. The primary output of this phase is a theoretically grounded codebook that will serve as the foundation for the subsequent quantitative analysis (MacQueen et al., 1998).
Phase 2: Quantitative Analysis of Discursive Shifts (Answering RQ3)
The second phase extends the qualitative findings to the entire dataset to quantitatively measure shifts in the discourse over time. Using the thematic categories developed in Phase 1, we will construct and validate an automated text classifier. The purpose of this classifier is not to replace human interpretation, but to apply our qualitatively-derived understanding at scale. The classifier will categorise the whole corpus of posts, allowing us to conduct a temporal analysis focused on the periods surrounding the releases of ChatGPT and GPT-4. By analysing the frequency and distribution of different risk framings before and after these key events, this phase aims to provide macro-level evidence for how the discourse evolved following these major technological developments.
Phase 3: Integration and Interpretation (Answering RQ1)
The final phase involves integrating the qualitative and quantitative findings. Here, the results from Phase 2 will be interpreted through the lens of the contextual understanding gained in Phase 1. This final step achieves the complementary goal of the mixed-methods design, grounding the quantitative results in important contextual information about the community's discourse (Frederiksen et al., 2023).
Data Collection
Our data collection strategy followed the double-funnel model of netnographic investigation, proceeding in two sequential stages: a broad, immersive scouting phase followed by a focused corpus definition (Kozinets, 2019).
We initiated our study with a netnographic immersion into the LessWrong community to map its unique culture, norms, and discourse. This scouting involved exploring key tags like “ai-risk”, “ai-safety”, and “alignment”, and documenting observations in an immersion journal (archived in the online repository; Harket, 2025) to map the platform's rhetorical styles and epistemic norms (Kozinets, 2019). The posts were complex and lengthy, with some being over 20 pages. The comment sections mirrored this depth, often featuring detailed, well-reasoned analyses that engaged substantively with the post's core arguments. The vast amount of text required a strategic narrowing of our research focus.
Guided by our observation that the public releases of ChatGPT and GPT-4 served as major catalysts for community debate, we defined our analytical scope around these key events. Our final corpus was thus defined as all posts tagged "ai-risk" and “alignment” published between November 30, 2021, and November 30, 2023. This timespan captures the year before and after the ChatGPT release, including the eight months following the GPT-4 release, providing a robust design for a pre- and post-event comparative analysis.
Data Retrieval and Preprocessing
We proceeded to retrieve all relevant documents with the tags “ai-risk” and “alignment” within the specified time period. First, we explored the site's GraphQL API using the Insomnia API client (Kong, n.d.) to understand its structure. After identifying the correct query structures, we developed a custom Python pipeline using requests, json, and dateutil to programmatically retrieve all post IDs and associated metadata (e.g., upvotes, comment counts, author karma). We used retrieved post IDs to scrape embedded Apollo state data from the LessWrong frontend using requests and BeautifulSoup to obtain the full post content and associated comment threads with their metadata.
The resulting dataset included 901 posts and 12,768 comments from 454 post authors and 1,622 comment authors. This data was then cleaned of formatting noise (e.g., HTML and Markdown) and filtered to exclude non-English posts, preparing it for qualitative and computational analysis.
Ethical Considerations and Limitations
This study follows the ethical guidelines for studying online communities outlined by Kozinets (2019). Although LessWrong is a public forum, the subject matter of AI risk is sensitive and demands careful representation. While most users post under pseudonyms, we judged that public figures who use their real names, such as Eliezer Yudkowsky, are not vulnerable individuals in this context. Their contributions are central to the discourse and widely debated; therefore, retaining their names is consistent with ethical reporting.
A key limitation of this study included the potential over-representation of the most highly engaged users, as is common in digital discourse analysis (Gaffney & Matias, 2018). However, our dataset demonstrates substantial author diversity, with 454 post authors and 1,622 comment authors across 901 posts. This suggests broad community participation rather than dominance by a small group of users. Regarding our focus on posts tagged with "ai-risk" and “alignment”, we acknowledge this may exclude some relevant discussions. However, our netnographic exploration revealed that a major part of the AI risk discourse on LessWrong is concentrated within these tags, making it an appropriate boundary for systematic analysis.
Methods
Qualitative Analysis Methods – Grounded Theory Coding
This study employed a mixed-methods strategy integrating qualitative grounded theory coding with computational text analysis, following both the CALM framework (Carlsen & Ralund, 2022) and principles from Computational Grounded Theory (Nelson, 2020). The methodology followed a sequential and complementary structure. Initial immersion and grounded theory coding were used to identify key discursive patterns inductively, while machine-assisted classification and quantitative validation extended and tested these insights at scale.
Qualitative Coding
NVivo 15 (Lumivero, 2025) was used to develop the codebook during open and focused coding, while closed coding was conducted collaboratively using Google Sheets. The analysis started with open coding of 20 documents (10 posts and 10 comments from two topics), selected from BERTopic-generated Topic 0 (agi, think, like, don’t) and Topic 7 (language, llm, llms, actor) based on high engagement and temporal relevance around ChatGPT and GPT-4’s release.
Focused coding followed, targeting six purposefully sampled posts (i.e., three for each overarching style identified through open coding) selected using thematic keyword queries identified through the open coding (e.g., “paperclip-maximizer”, “AGI”, “LLM”, “terrorist”, “China”). Comments were excluded from the focused coding as they did not provide sufficient contextual information alone to be reliably interpreted. The keyword searches yielded several hundred posts; however, the focused coding was limited to six posts due to the extensive length of the posts and time constraints.
Machine-Assisted Classification
We operationalised the identified abstract and tangible AI risk distinction through a similarity-based classification approach using sentence-transformer embeddings. To form the semantic foundation of our classifier, we first drew upon our qualitative findings to craft 32 representative exemplar sentences for each category. We then calculated the cosine similarity between each post in our dataset and these exemplar sentences using the all-MiniLM-L6-v2 model (Reimers & Gurevych, 2020). To handle long documents, posts exceeding the model's 512-token limit were segmented into consecutive chunks, and their final similarity scores were averaged to produce a single score for the entire post.
Abstract risk exemplar sentences used for comparison included theoretical and speculative scenarios, such as "Nanobots could disassemble all matter on Earth to create paperclips", whereas tangible risk exemplars focused on current, practical concerns, such as "ChatGPT can be jailbroken to generate harmful content and bypass safety protocols." All exemplar sentences used for this analysis are available in the project’s repository (Harket, 2025).
For each post, a composite similarity score was calculated for both categories: “Abstract AI Risk” and “Tangible AI Risk”. This composite score was calculated as a weighted sum, combining the post's similarity score for the single best-matching exemplar sentence (70% weight) with its average similarity across all exemplars in that category (30% weight). The weighting was chosen to prioritise the single strongest signal of a post's topic while grounding the classification in the overall thematic context.
The two resulting scores formed the basis for all subsequent measurement strategies detailed in our multi-approach design. For Binary Classification, a post was assigned to the category with the higher composite score. The score of that winning category was then designated as the post’s overall confidence score, the metric used directly in our Confidence-Weighted and Confidence Threshold analyses.
This custom approach outperformed dictionary-based methods and prompt-based classifiers like FLAN-T5 in preliminary validation. Dictionary-based classification left a major part of the documents unclassified (60%), while prompt-based classifiers like FLAN-T5 misclassified most documents in preliminary testing. It is worth mentioning that newer open-weight LLMs would most likely perform much better than FLAN-T5. Nevertheless, given our lack of GPU access, using an LLM was not feasible, and our custom approach proved to be a good alternative, capturing semantic details whilst being computationally effective.
Lastly, our method provided an unexpected methodological advantage through the ability to quantify classification uncertainty using confidence scores. During closed coding, we observed that posts yielding low inter-rater reliability among human coders consistently produced ambiguous similarity scores in our automated classification. This suggests the model effectively identified ambiguous content rather than classification failures.
Validation Study and Methodological Evolution
To validate our classification approach, we conducted closed coding on a stratified random sample of 40 posts (4.5% of the 884-post classified dataset), with three independent human classifications per post, followed by consensus discussion. The insights gained from this process directly informed the development of a multi-approach measurement strategy to account for classification uncertainty.
Multi-Approach Measurement Strategy
Based on our validation insights, we implemented four progressively more conservative measurement approaches to ensure robust effect size estimates:
Binary Classification. The binary classification treats each post as definitively abstract (0) or tangible (1) based on the highest confidence scores, providing baseline estimates comparable to traditional categorical analysis.
Confidence-Weighted Analysis. The confidence-weighted analysis used all classifications within a specified timeframe, weighted by the model's confidence score for each classification. The final weighted proportion score for each period was derived by calculating:
The purpose of this measurement strategy is to reduce the influence of uncertain classifications while preserving all data.
Spectrum-Based Analysis. The spectrum-based analysis was used to provide a continuous measurement using "tangible lean" scores calculated as the difference between tangible and abstract similarity scores , (range: -1 to +1). This approach eliminated arbitrary categorisation thresholds. Negative scores indicated abstract-leaning posts, positive scores indicated tangible-leaning posts, and values near zero represented ambiguous content.
Confidence Threshold Analysis. The confidence threshold analysis provided an error-correction approach, excluding classifications below specified confidence levels. Based on our closed coding showing high error concentration below 0.25 confidence, we identified ≥0.35 as the optimal threshold for improving accuracy whilst retaining the most data (55% of the original dataset).
Statistical Analysis
Our statistical strategy employed a comprehensive triangulation strategy. We used two-sample proportion z-tests for binary classifications and Welch's independent samples t-tests to compare tangible lean scores before and after each model release. To ensure robustness, we also report the results of non-parametric Mann-Whitney U tests in our appendix. Effect sizes were calculated using Cohen's d for continuous measures and Cohen's h for proportion differences. Our primary error-correction mechanism was a systematic confidence threshold analysis, with ≥0.35 identified as the optimal threshold. Cohen's d is interpreted as per (Cohen, 1988). All tests used α = 0.05.
Analysis
This analysis section follows the structure of our sequential mixed-methods design. First, we present our qualitative findings from open and focused coding, addressing RQ2. The results from our qualitative analysis provide the foundation for creating and validating our automated classifier, which is detailed in the machine-assisted classification section. The analysis of the classifier results is presented in the quantitative analysis section, answering RQ3.
Open Coding
The analytical process began with an exploratory open coding phase, designed to inductively identify key discursive patterns within our data in alignment with grounded theory principles (Glaser & Strauss, 1967). To guide this exploration, we first used BERTopic to generate a thematic overview of our corpus. HDBSCAN was used to derive topics, resulting in a total of 108 identified topics across all posts and comments. We purposefully selected two topics (i.e., topic 0 and 7) that seemed to significantly shift in activity around the ChatGPT and GPT-4 releases, ensuring our sample was grounded in the key events of our study. Topic 0 was chosen as relevant, as it was the topic with the most posts in general and had sustained activity before the release of ChatGPT, while spiking after the release. Initially, we expected topic 0 (agi, think, like, don’t) to be about users portraying AGIs or AIs that can “think”, and topic 7 (language, llm, llms, actor) to be about either LLMs having or achieving agency. To conduct open coding, we sampled 20 documents (posts and comments) based on the highest upvote count within the two topics.
Open coding revealed that the two topics represented distinct risk discussions. We discovered two distinct framings, each with its own unique epistemic style.
The discourse of topic 0, which we termed "Abstract AI risk discussion", was characterised by a rationalist-philosophical epistemic style. Posts in this cluster focused on theoretical, future-oriented scenarios, such as the risks of "instrumental convergence" (Bostrom, 2014) or an "intelligence explosion" leading to human extinction as an inevitable by-product of building AGI. Interestingly, we discovered that when users discussed risks, “think” and “don’t” were used to express opinions (e.g., I think or I don’t think). Expressions such as “like” were used to represent concepts, often in a comparative manner using metaphors or analogies. We found a highly expressive discussion that was populated with many thoughts on why building AGI is risky. A central theme was the conception of risk as originating directly from the AI's or AGI's own agency, rather than from misuse by human actors (e.g., terrorists).
The discourse of topic 7, which we termed "Tangible AI risk discussion," employed a more empirical-scientific epistemic style to address risk. It centred on immediate, practical risks posed by current technologies, such as the potential for bad actors to misuse LLMs to create malware or weapons. The argumentation here was grounded in demonstrable capabilities and near-term threats. Surprisingly, our initial interpretation of “actor” diverged from the content of topic 7. Most instances of the word “actor” referred to human actors (e.g., “bad actor”) using LLMs to cause harm, rather than LLMs as actors themselves. This is an important discrepancy from topic 0, which mostly focused on risks created by AI/AGI itself.
This apparent divergence in rhetorical style and risk framing suggested the presence of distinct discourse communities within the broader AI safety discussion on LessWrong. This interpretation was further supported by a quantitative check showing minimal author overlap (3.8%) between the two initial topics. Despite these differences, a unifying observation between these two discourses was the shared focus on the potential catastrophic risks associated with the further development of AI. These emergent themes, and especially the central contrast between abstract and tangible framings, provided the analytical focus for our subsequent focused coding phase. We found a strong alignment between the type of risk being discussed and the epistemic style used to present it. Specifically, abstract AI risk was almost always articulated with a rationalist-philosophical epistemic style, while tangible AI risk was consistently framed using an empirical-scientific epistemic style.
Focused coding
The focused coding phase refined our analysis around the two overarching framings that consistently emerged from the data: abstract and tangible AI risk discussion. These two risk-style patterns became our primary analytical categories.
To explore these two risk categories in greater analytical depth, we adopted the method of index case selection, as described in Timmermans & Tavory’s abductive coding framework (Timmermans & Tavory, 2022). Rather than seeking a typical or average post, an index case is a particularly vivid or analytically rich instance highlighting key tensions or dimensions within a category. Below, one index case for each identified type of AI risk is highlighted.
Tangible AI Risk.The following index case of tangible AI risk illustrates potential risks associated with powerful open-weights models.
“LoRA fine-tuning undoes the safety training of Llama 2-Chat 70B with one GPU and a budget of less than $200. The resulting models[1] maintain helpful capabilities without refusing to fulfil harmful instructions. We show that, if model weights are released, safety fine-tuning does not effectively prevent model misuse”
This case exemplifies the tangible AI risk discussion, focusing on the immediate risks of current systems being misused by bad actors. The risk stems not from the AI's autonomous actions, but rather from its potential for misuse by human actors.
Abstract AI risk. The following index case exemplifies abstract AI risk, focusing on existential risks rather than immediate dangers.
“A common misconception is that STEM-level AGI is dangerous because of something murky about ‘agents’ or about self-awareness. Instead, I'd say that the danger is inherent in the nature of action sequences that push the world toward some sufficiently-hard-to-reach state. Call such sequences ‘plans’.
If you sampled a random plan from the space of all writable plans (weighted by length, in any extant formal language), and all we knew about the plan is that executing it would successfully achieve some superhumanly ambitious technological goal like ‘invent fast-running whole-brain emulation’, then hitting a button to execute the plan would kill all humans, with very high probability”
This index case exemplifies abstract risk logic, where risk emerges from an unaligned AGI as an inherent property of unaligned AGI itself, rather than from misuse or malicious actors. The author employs highly domain-specific, taken-for-granted language such as “plan spaces”, “weighted by length,” and “formal language”, assuming the reader is familiar with these concepts. The author highlights a high probability of sudden human extinction. This contrasts sharply with tangible risks, which are limited by humans’ and organisations’ ability to cause harmusingAI (e.g., one terrorist organisation, even if it can make bombs really effectively, is unlikely to cause extinction).
Theoretical Interpretation of Risk Framings
The two index cases illuminate the distinct epistemic styles and risk logics of the tangible and abstract risk discussions. Applying our theoretical framework reveals how these framings are built on divergent assumptions about agency, temporality, and uncertainty.
We can use Kasirzadeh’s (2025) typology to get a precise vocabulary for the two risk types. Tangible risk directly corresponds to accumulative x-risk, in which danger emerges slowly as countless actors bypass security measures, find vulnerabilities in AI systems, or as bad regulations take hold. This process creates a distributed erosion of safety where the disaster's magnitude is a function of collective misuse. In contrast, abstract risk is an example of decisive AI x-risk: scenarios featuring an abrupt, irreversible catastrophe, such as one caused by an unaligned AGI.
This distinction in risk scenarios is mirrored by a difference in the community's epistemic style, a dynamic that can be explained by Clarke’s (2006) work on possibilism. Abstract risk discourse is a pure form of possibilistic thinking, focusing on the possible (e.g., an AGI converting the universe to paperclips) regardless of its calculable probability, because the consequences are absolute. The reasoning is abstract, speculative, and driven by the potential outcome's sheer magnitude. Tangible risk, however, represents a more grounded or empirical possibilism. The reasoning is still about possibility, but is anchored in demonstrated capabilities. Unlike purely theoretical threats, the danger of a fine-tuned model causing harm is grounded in the concrete evidence that its safety features can be removed for less than $200. This shifts the focus from what can happen in principle to what can happen in practice.
Finally, Beck’s (2006) theory of the world risk society situates this entire discourse within a broader societal context. The discussion of tangible risk aligns with a classic world risk society scenario, wherein the release of open-source models, as an instance of "manufactured unknown unknowns," results in the delocalisation and individualisation of threats, constituting numerous actors as both risk creators and managers. Conversely, the concern around abstract risk points to a more ontological danger. Here, Beck’s "unknown unknowns" are not about unpredictable social consequences, but about harms that may be, in principle, incomprehensible to human reasoning. The risk is located in the formal nature of the technology itself, not merely its social application.
Machine-Assisted Classification
To ensure the reliability of our automated text classifier, we conducted closed coding on a validation set. This set was a stratified random sample comprising 40 posts. Each group member participated as an independent coder, classifying each post based on insights gained from the focused coding. Afterwards, they held a consensus discussion to establish a final ground truth. Our similarity-based classifier achieved an accuracy of 85% against this consensus, a performance that notably exceeded the average pairwise agreement among human coders (80.1%, Fleiss' κ = 0.615), demonstrating the robustness of the automated approach (Fleiss, 1971).
The validation process yielded more valuable insights than a simple accuracy score. It revealed characteristics of the discourse that required a more sophisticated measurement strategy than a simple binary classification. We identified three key findings that motivated our methodological evolution from a categorical to a spectrum-based analytical framework.
AI Risk Discourse Exists on a Spectrum.The human coders struggled with the inherent ambiguity of the posts, as many blended or addressed both abstract and tangible risks. This confirmed a key qualitative finding: AI risk discourse on LessWrong seems to exist on a spectrum, not as a binary. Forcing a binary choice would misrepresent the nature of the discourse itself.
Classification Confidence is a Meaningful Diagnostic for Ambiguity. Our model's confidence scores proved to be an effective tool for identifying this ambiguity. The distribution of classification errors does not seem to be random. Half of the misclassified posts had confidence scores below 0.25, suggesting low confidence scores effectively flag ambiguous content. As shown in Figure 2, most posts across both categories fall into a low-to-moderate confidence range (overall M = 0.368), reinforcing the conclusion that few posts are clear-cut examples of one category.
Crucially, these low confidence scores are an expected and inherent consequence of our classification design. The method compares the embedding of a full-length, multifaceted post against a set of short, semantically pure exemplar sentences. A post's embedding represents a "semantic average" of all its content, which dilutes its similarity to any single, perfect exemplar sentence. Therefore, the validity of this approach stems not from achieving high absolute scores but from the relative comparison: the classifier effectively determines if a post leans more towards the abstract or tangible exemplar sentence. Our 85% accuracy in the validation study empirically demonstrates that this relative measurement is robust and meaningful, establishing the confidence score as a valuable diagnostic for ambiguity rather than a measure of absolute certainty.
Figure 2
Distribution of Confidence Scores by Predicted Category
Note. The confidence score for each post is the composite similarity score of its predicted category. The wide distribution and concentration of scores in the low-to-moderate range for both categories visually demonstrate that few posts are unambiguous examples of either “abstract” or “tangible” AI risk discourse. The left-skewed distribution for “tangible” indicates slightly higher confidence in these classifications than “Abstract”.
The Community Engages in a Shared, Not Segregated, Discourse.An analysis of author behaviour demonstrated that most users participate across the full risk spectrum. At lower confidence thresholds, author overlap between categories was near-total (94%), while it dropped to just 2.3% for the most unambiguously classified posts (Figure 3). This provides strong evidence against a view of the community as being split into two ideological camps, as suggested by our open coding. Instead, it highlights a shared discussion space where most authors engage with both abstract and tangible AI risk framings, with only a few consistently writing about purely "abstract" or "tangible” AI risks.
Figure 3
Author Overlap Ratio Across Confidence Thresholds
Note. The Author Overlap Ratio represents the proportion of authors who have written at least one post in both the “abstract” and “tangible” categories, considering only posts that meet or exceed the confidence score threshold on the x-axis. The steep decline demonstrates that while most authors engage in the broad, lower-confidence discourse, only a very small set of authors produce content that is consistently classified as either abstract or tangible.
Motivation for a Spectrum-Based Analytical Strategy. Together, these insights demonstrate that it is methodologically inadequate to consider AI risk discourse on LessWrong as a binary. Our validation process revealed that applying a categorical approach would obscure the nature of the risk framings, which seem to exist on a spectrum. This approach is consistent with the digital methods principle that analytical tools should reflect the specific characteristics of the online data being studied (Venturini et al., 2018). This discovery motivated our shift towards the multi-approach measurement strategy used in our final analysis. To address the data's inherent ambiguity, our analysis integrated three distinct techniques: confidence-weighting, spectrum-based analysis, and threshold filtering. This combined method allowed us to produce robust quantitative findings.
Quantitative analysis
To answer our third research question: To what extent did the proportional focus on tangible versus abstract AI risk on LessWrong differ between the periods before and after the releases of ChatGPT and GPT-4?, we analysed 884 timestamped LessWrong posts from the year before and after the releases of ChatGPT and GPT-4. As our validation study revealed, the distinction between abstract and tangible risk operates on a spectrum rather than as a discrete binary. A simple categorical analysis would therefore misrepresent the nuanced nature of the discourse and inflate effect sizes.
To ensure the robustness of our findings against classification uncertainty, we developed a multi-approach measurement strategy. We established credible effect size boundaries by applying a more conservative spectrum-based and confidence-weighted analysis. This use of methodological triangulation validates that our findings are genuine reflections of discursive shifts, not artifacts of measurement.
Discourse Shifts Following the ChatGPT Release. The release of ChatGPT on November 30, 2022, was followed by a significant and robust shift toward more tangible AI risk discussions. Detailed statistical results for all analyses are presented in the Appendix. Our most conservative, error-corrected analysis (using a ≥0.35 confidence threshold) revealed a medium-to-large effect, with the discourse shifting by +0.0443 on the tangible-abstract spectrum (d = 0.410, p < 0.001).
This finding remained consistent across all measurement approaches, though the estimated effect size varied as expected. A standard binary classification, for instance, showed the proportion of tangible posts increasing by 11.0 percentage points (from 28.5% to 39.5%; z = 3.173, p = 0.002), but this more liberal estimate likely overstates the true magnitude by not accounting for classification uncertainty. Non-parametric tests further confirmed a significant distributional shift (KS test, p < 0.001), indicating that the change was not merely a shift in the mean but a reorientation of the discourse. As shown in Figure 4, the shift in discourse during the post-release period remained statistically significant even at the higher confidence thresholds.
Figure 4
Confidence Threshold Analysis for ChatGPT and GPT-4 Release Effects
Note. Panel A shows spectrum effect sizes across confidence thresholds. Panel B displays significance levels and data retention. ChatGPT effects remain robust across thresholds; GPT-4 effects become non-significant at ≥0.45. Optimal threshold (≥0.35) balances power with error correction.
Discourse Shifts Following the GPT-4 Release. The subsequent release of GPT-4 on March 14, 2023, continued this trend but with a smaller and less robust effect. Detailed statistical results for all analyses are presented in the Appendix. Our error-corrected analysis showed a small-to-medium effect in the same direction (d = 0.290, p = 0.002), approximately 1.4 times weaker than the shift following ChatGPT. Unlike the ChatGPT effect, the statistical significance for GPT-4 diminished at higher confidence thresholds (≥0.45, see Figure 4). This suggests that while the trend toward tangible concerns continued following the release of GPT-4, the discourse surrounding its release may have been more ambiguous or nuanced, making confident classification more challenging.
Temporal Trends and Methodological Synthesis. The overall findings are best visualised in Figure 5, which plots the monthly trend of the discourse. The sustained increase in tangible concerns after the release of ChatGPT is visible, with a smaller, steady increase observed following the GPT-4 release.
Figure 5
Temporal Trends in AI Risk Discourse Framing on LessWrong
Note. Monthly tangible lean scores showing discourse shifts around releases. Vertical lines mark release dates. Notable increases follow both releases, with pronounced changes around ChatGPT's launch. The marked increase in tangible lean scores before November 30th, 2022, appears to precede ChatGPT's release, but this is an artefact of monthly averaging, making the response appear to begin before the actual release date.
Ultimately, the validity of our findings is strengthened by our multi-approach methodology. Triangulating results across four different measurement strategies (Figure 6) confirmed a consistent directional shift while establishing realistic bounds on the effect sizes. The systematic reduction in effect magnitude from binary to error-corrected spectrum-based analysis validates our assumption that simpler models can overestimate effects in text data (Figure 7). Our robust, error-corrected analysis suggests that following concrete AI developments, specifically the release of ChatGPT and GPT-4, the focus of LessWrong’s AI risk discourse shifted toward discussing more tangible AI risks. (Figure 8).
Figure 6
Effect Size Estimates Across Measurement Approaches for ChatGPT and GPT-4 Release
Note. Effect sizes for both releases across four approaches. Binary yields the largest effects; spectrum-based provides the most conservative estimates. All show consistent directional effects, with ChatGPT consistently larger than GPT-4.
Figure 7
Distribution Analysis of AI Risk Discourse Across Temporal Period
Methodological Validation of Confidence Threshold Approach
Note. Panel A shows the effect stability across thresholds. Panel B displays error rates by confidence level. Results validate that higher thresholds filter misclassifications while maintaining stable estimates.
Conclusion
This study investigated how AI risk discourse on LessWrong evolved following the releases of ChatGPT and GPT-4. By integrating qualitative netnography with large-scale computational analysis, we found that this evolution is best understood as a pragmatic rebalancing of a community engaging in multifaceted discourse.
Our analysis addressed what framings of risk exist (RQ2), identifying two primary, coexisting discourses: a rationalist-philosophical “abstract” AI risk framing focused on future risks associated with further development of AI, and an empirical-scientific “tangible” AI risk framing centred on more immediate misuse of current systems. Our qualitative work revealed these as distinct analytical poles, while author-level analysis of our classifier results showed that most users engage across this spectrum rather than belonging to segregated ideological camps.
Our quantitative analysis, addressing RQ3, documented a statistically significant reorientation of the discourse toward tangible AI risk framings after both AI releases investigated in this paper. The introduction of ChatGPT coincided with what our analysis measured as a medium-to-large effect (d = 0.410), establishing a primary discursive shift that was later consolidated by a smaller effect following the release of GPT-4 (d = 0.290).
Synthesising these points provides a comprehensive answer to our main research question on how the discourse evolves (RQ1). The LessWrong community did not abandon its rationalist-philosophical foundation, but pragmatically reoriented its collective attention in response to concrete technological developments. The arrival of powerful, real-world AI systems coincided with a reorientation of the discourse, which moved from what is merely possible, in line with Clarke's (2006) possibilistic reasoning, toward the immediate, "manufactured uncertainties" that characterise Beck's (2006) world risk society.
The implications of this research are twofold. First, for AI risk communication, it shows that the LessWrong community’s framings of technological threats appear to evolve as abstract possibilities become concrete realities. Second, the methodological contribution of this research is a robust framework for addressing measurement uncertainty in automated text analysis. By combining spectrum-based classification with confidence-weighted analysis under the CALM framework (Carlsen & Ralund, 2022), we provide a powerful tool for studying how discourse adapts alongside technological advancements.
Overview of the paper
In this paper, we set out to empirically map the evolution of the AI risk discourse on LessWrong, specifically in response to the public releases of ChatGPT and GPT-4. These events represented a significant shift, moving advanced AI from a theoretical concern to a tangible, publicly accessible technology. Our central research question was: How is the AI risk discourse on this forum constructed, and how did its thematic composition change during this pivotal period?
To answer this, we conducted a two-phase analysis of 884 posts published under the "ai-risk" and "alignment" tags in the year before and after ChatGPT's release.
First, through a qualitative reading of the posts, we identified two primary, coexisting framings of risk. We termed the first "abstract AI risk," which encompasses the rationalist-philosophical discourse on future, decisive threats, such as those from an unaligned superintelligence or instrumental convergence—the classic "paperclips" scenario. The second we termed "tangible AI risk," which uses a more empirical-scientific style to discuss the immediate, accumulative threats posed by the misuse of current systems, such as bad actors creating malware or "bombs."
In the second phase, we used these qualitative findings to develop and validate a computational text classifier. This tool allowed us to analyse the entire dataset and quantitatively measure the prevalence of each risk framing over time.
Our analysis revealed a statistically significant shift in the community's focus. Following the release of ChatGPT, the discourse reoriented robustly toward tangible risks. The release of GPT-4 continued this trend, albeit with a smaller effect. Crucially, our analysis of author activity shows that this was not the result of a community fragmenting into ideological camps. Instead, most authors engage across the full spectrum of risk, indicating a shared discourse that collectively rebalanced its attention.
In essence, this research provides a data-driven account of how the LessWrong community responded to concrete technological progress. The forum did not abandon its foundational concern with long-term existential risk, but pragmatically shifted its focus from what is theoretically possible toward what is demonstrably real.
Introduction
The rapid development of artificial intelligence (AI) has made the technology a central topic of public debate, generating significant discussion about the potential risks associated with its advancement. A prominent line of argument warns that creating an Artificial General Intelligence (AGI) could trigger an existential catastrophe for humanity (Bostrom, 2014). This perspective has gained traction and is endorsed by leading experts, such as Geoffrey Hinton, emphasising the "existential threat that will arise when we create digital beings that are more intelligent than ourselves," warning that "we have no idea whether we can stay in control." (Hinton, 2024)
While this discourse has a long history, recent advances in Large Language Models (LLMs), particularly OpenAI's ChatGPT and subsequently GPT-4, have represented a major change in the field of AI (OpenAI, 2022; OpenAI et al., 2024). These advancements had two major impacts this paper wants to focus on: they introduced advanced AI to the public, broadening the risk discourse, and they empirically validated neural scaling laws (Kaplan et al., 2020). For many in the field, this provided a more concrete pathway toward AGI, which in turn appears to have intensified existential risk concerns. The growing audience and increasing concerns about possible AGI timelines provide an opportunity to investigate how these shifts influenced the AI risk debates. A prominent place to explore AI risk discussions is the forum LessWrong (Ruby et al., 2019). Despite its influence, LessWrong has received limited academic attention, making this analysis valuable for understanding how its engaged community responds to technological and social changes.
This study aims to investigate how the AI risk discourse is constructed and how it transforms on the LessWrong forum following these major AI developments. To guide this inquiry, our overarching research question asks:
RQ1: How is the AI risk discourse on LessWrong constructed, and how did its thematic composition change in the periods surrounding the releases of ChatGPT and GPT-4?
To answer this, we pursue two sub-questions. The first investigates the qualitative nature of the discourse, asking:
RQ2: What are the primary framings of AI risk within the LessWrong discourse, and how do they conceptualise risk differently?
The second quantitatively addresses changes in the popularity of these framings, asking:
RQ3: To what extent did the proportional focus on tangible versus abstract AI risk on LessWrong differ between the periods before and after the releases of ChatGPT and GPT-4?
To address these questions, this paper employs a sequential mixed-methods design (Frederiksen et al., 2023). First, a qualitative analysis develops an interpretive understanding of the community's risk framings, which then informs a computer-assisted classification to measure discursive shifts.
Background
Central to concerns over advanced AI is the "alignment problem", the challenge of ensuring that autonomous AI systems pursue goals compatible with human values (Russell, 2019). This is not a new concern; the theoretical foundations of AI alignment have been developed over decades by researchers and theorists such as Eliezer Yudkowsky (2001), Steve Omohundro (2008), and Nick Bostrom (2012).
LessWrong was founded by AI safety theorist Eliezer Yudkowsky, and for over a decade, the forum has served as a primary hub for this discourse (Ruby et al., 2019), attracting a dedicated community of researchers, developers, and enthusiasts (McLean, 2024). The platform's emphasis on detailed argumentation and its focus on rationality make it a valuable site for understanding how AI risk concerns are constructed (Ruby et al., 2019). Compared to platforms like Reddit or X, LessWrong's depth and structure, facilitating reasoned argumentation, make it especially well-suited for this research.
Based on the 2023 LessWrong Community Survey Results (Screwtape, 2024), the community consists primarily of young, highly educated technology professionals. The sample included 558 respondents, representing a small portion of active users, as LessWrong currently has close to 1.7 million monthly visits (Similarweb, 2025). Despite the low response rate, the available data still provides valuable, albeit imperfect, insight into the community's demographics. The median age is 29, and the population is overwhelmingly male (89.3% assigned male at birth), predominantly white (78.9%), and based in the United States (49.6%). The community is exceptionally well-educated, with 67.3% holding a bachelor's degree or higher. Professionally, over half of the people work in computing fields (56.5%), while politically, they lean toward progressive-libertarian and are overwhelmingly secular (67.1% atheist). Interestingly, the site members have an average IQ of 134; however, this figure is based on a small, self-selected sample (25% of respondents), making it unrepresentative of the entire community. Lastly, they demonstrate high engagement with rationalist content, as 63.9% embrace consequentialist ethics.
The forum's culture is reinforced by its design. Moderators manually review all first-time contributions for quality and alignment with community standards, a form of gatekeeping that deters low-effort content while filtering for epistemic rigour (Ruby et al., 2019). Furthermore, posts and comments are subject to a karma system where users upvote or downvote content. Vote strength increases with a user's prior karma, giving experienced members greater influence over what becomes visible on the platform. By rewarding clarity and rational engagement, the karma system actively promotes high-effort contributions and reinforces the community's core epistemic norms, such as intellectual humility, the charitable interpretation of opposing arguments, and the use of probabilistic reasoning (lsusr, 2020).
Theoretical Framework
The purpose of the following theory section is to provide a layered framework that allows us to analyse the discourse on LessWrong. Consequently, the theory is used to contextualise the data site’s idea of risk and understand the discourse’s internal logic.
Beck's World Risk Society: A Way to Understand Technological Uncertainty
Ulrich Beck’s theory of the "world risk society" provides a broad context for understanding contemporary discussions about technological threats. Beck (2006) argues that advanced modern societies are increasingly preoccupied with managing "manufactured uncertainties", risks that are the unintended consequences of their own technological and industrial activities. A key characteristic of these risks is that their full impact is often incalculable, transcending the predictive capacities of conventional scientific assessment. Risk definitions, therefore, emerge from a complex social process of deliberation and contestation. Because risks are often delocalised (i.e., transcend national borders), institutions lack the tools to manage them, leaving the risk to be governed by individuals.
From this perspective, the LessWrong forum can be understood as a site where such a process unfolds. Especially when Beck’s idea of risk, as global and often irreversible events, is included. Beck’s concepts, including the global and irreversible nature of potential harms, provide a vocabulary to describe the conditions that animate the AI risk discourse.
Clarke's Possibilism: The possibility of Worst-Cases
While Beck situates a societal context, Clarke’s (2006) work on "possibilistic thinking" offers a framework for analysing the specific mode of reasoning often employed in risk discussions. Clarke distinguishes probabilistic thinking (which focuses on the statistical likelihood of an event) and possibilistic thinking (which focuses on the consequences of what is possible). Possibilism’s relevance for new technologies lies in its ability to shift the analytical focus from an event’s statistical likelihood to the magnitude of its potential consequences.
This lens allows us to analyse the community's focus on high-impact scenarios not as a judgment on probability, but as a distinct form of reasoning.
Kasirzadeh's Typology: A Vocabulary for Mapping Risk Scenarios
To conduct a granular analysis of the discourse content itself, we utilise Kasirzadeh's (2025) distinction between two primary pathways of AI existential risk (AI x-risk). This framework separates scenarios of decisive AI x-risk, referring to an abrupt and catastrophic event like the creation of an uncontrollable superintelligence, and accumulative AI x-risk, referring to a more gradual process, where systemic and societal resilience is destroyed through numerous AI-induced disruptions, leading to an eventual collapse.
This typology serves as a concrete analytical tool. It provides a precise vocabulary for categorising and mapping AI risks discussed on LessWrong.
Design
This study employs a sequential, complementary mixed-methods research design to investigate the construction and evolution of AI risk discourse on LessWrong (Frederiksen et al., 2023). The design is intended to first build a qualitative understanding of the community's framings that will guide a subsequent large-scale computational analysis. This approach aligns with the Computer-Assisted Learning and Measurement (CALM) framework, where computational tools support both exploration and measurement, while human interpretation remains central to developing and validating theory (Carlsen & Ralund, 2022).
The research is organised into three distinct but interconnected phases, each designed to address a specific research question. The overall design logic is visualised in Figure 1 below.
Figure 1
The sequential mixed-methods research design.
Note. Each phase of the research builds on the previous one. The design begins with an inductive, qualitative exploration to generate theory and interpretive categories. These categories then form the basis for a deductive, large-scale quantitative analysis to measure trends, with the final phase synthesising both data types.
Phase 1: Qualitative Immersion and Thematic Discovery (Answering RQ2)
The initial phase is a qualitative exploration designed to understand the core themes and argumentative styles that constitute AI risk discourse on LessWrong. This phase begins with a netnographic immersion into the community, involving in-depth reading of posts and immersion journaling to understand the platform’s culture, norms, and specialised language (Kozinets, 2019). Following initial familiarisation, we conduct an exploratory analysis using topic modelling (BERTopic), with thematic clusters derived via HDBSCAN, to map the discourse. This allows for a data-driven selection of posts for a fine-grained grounded theory coding process (Glaser & Strauss, 1967). Through open coding, followed by focused coding, on a sampled set of posts, this phase will produce a set of analytical categories that capture the distinct ways the community frames AI risk. The primary output of this phase is a theoretically grounded codebook that will serve as the foundation for the subsequent quantitative analysis (MacQueen et al., 1998).
Phase 2: Quantitative Analysis of Discursive Shifts (Answering RQ3)
The second phase extends the qualitative findings to the entire dataset to quantitatively measure shifts in the discourse over time. Using the thematic categories developed in Phase 1, we will construct and validate an automated text classifier. The purpose of this classifier is not to replace human interpretation, but to apply our qualitatively-derived understanding at scale. The classifier will categorise the whole corpus of posts, allowing us to conduct a temporal analysis focused on the periods surrounding the releases of ChatGPT and GPT-4. By analysing the frequency and distribution of different risk framings before and after these key events, this phase aims to provide macro-level evidence for how the discourse evolved following these major technological developments.
Phase 3: Integration and Interpretation (Answering RQ1)
The final phase involves integrating the qualitative and quantitative findings. Here, the results from Phase 2 will be interpreted through the lens of the contextual understanding gained in Phase 1. This final step achieves the complementary goal of the mixed-methods design, grounding the quantitative results in important contextual information about the community's discourse (Frederiksen et al., 2023).
Data Collection
Our data collection strategy followed the double-funnel model of netnographic investigation, proceeding in two sequential stages: a broad, immersive scouting phase followed by a focused corpus definition (Kozinets, 2019).
We initiated our study with a netnographic immersion into the LessWrong community to map its unique culture, norms, and discourse. This scouting involved exploring key tags like “ai-risk”, “ai-safety”, and “alignment”, and documenting observations in an immersion journal (archived in the online repository; Harket, 2025) to map the platform's rhetorical styles and epistemic norms (Kozinets, 2019). The posts were complex and lengthy, with some being over 20 pages. The comment sections mirrored this depth, often featuring detailed, well-reasoned analyses that engaged substantively with the post's core arguments. The vast amount of text required a strategic narrowing of our research focus.
Guided by our observation that the public releases of ChatGPT and GPT-4 served as major catalysts for community debate, we defined our analytical scope around these key events. Our final corpus was thus defined as all posts tagged "ai-risk" and “alignment” published between November 30, 2021, and November 30, 2023. This timespan captures the year before and after the ChatGPT release, including the eight months following the GPT-4 release, providing a robust design for a pre- and post-event comparative analysis.
Data Retrieval and Preprocessing
We proceeded to retrieve all relevant documents with the tags “ai-risk” and “alignment” within the specified time period. First, we explored the site's GraphQL API using the Insomnia API client (Kong, n.d.) to understand its structure. After identifying the correct query structures, we developed a custom Python pipeline using requests, json, and dateutil to programmatically retrieve all post IDs and associated metadata (e.g., upvotes, comment counts, author karma). We used retrieved post IDs to scrape embedded Apollo state data from the LessWrong frontend using requests and BeautifulSoup to obtain the full post content and associated comment threads with their metadata.
The resulting dataset included 901 posts and 12,768 comments from 454 post authors and 1,622 comment authors. This data was then cleaned of formatting noise (e.g., HTML and Markdown) and filtered to exclude non-English posts, preparing it for qualitative and computational analysis.
Ethical Considerations and Limitations
This study follows the ethical guidelines for studying online communities outlined by Kozinets (2019). Although LessWrong is a public forum, the subject matter of AI risk is sensitive and demands careful representation. While most users post under pseudonyms, we judged that public figures who use their real names, such as Eliezer Yudkowsky, are not vulnerable individuals in this context. Their contributions are central to the discourse and widely debated; therefore, retaining their names is consistent with ethical reporting.
A key limitation of this study included the potential over-representation of the most highly engaged users, as is common in digital discourse analysis (Gaffney & Matias, 2018). However, our dataset demonstrates substantial author diversity, with 454 post authors and 1,622 comment authors across 901 posts. This suggests broad community participation rather than dominance by a small group of users. Regarding our focus on posts tagged with "ai-risk" and “alignment”, we acknowledge this may exclude some relevant discussions. However, our netnographic exploration revealed that a major part of the AI risk discourse on LessWrong is concentrated within these tags, making it an appropriate boundary for systematic analysis.
Methods
Qualitative Analysis Methods – Grounded Theory Coding
This study employed a mixed-methods strategy integrating qualitative grounded theory coding with computational text analysis, following both the CALM framework (Carlsen & Ralund, 2022) and principles from Computational Grounded Theory (Nelson, 2020). The methodology followed a sequential and complementary structure. Initial immersion and grounded theory coding were used to identify key discursive patterns inductively, while machine-assisted classification and quantitative validation extended and tested these insights at scale.
Qualitative Coding
NVivo 15 (Lumivero, 2025) was used to develop the codebook during open and focused coding, while closed coding was conducted collaboratively using Google Sheets. The analysis started with open coding of 20 documents (10 posts and 10 comments from two topics), selected from BERTopic-generated Topic 0 (agi, think, like, don’t) and Topic 7 (language, llm, llms, actor) based on high engagement and temporal relevance around ChatGPT and GPT-4’s release.
Focused coding followed, targeting six purposefully sampled posts (i.e., three for each overarching style identified through open coding) selected using thematic keyword queries identified through the open coding (e.g., “paperclip-maximizer”, “AGI”, “LLM”, “terrorist”, “China”). Comments were excluded from the focused coding as they did not provide sufficient contextual information alone to be reliably interpreted. The keyword searches yielded several hundred posts; however, the focused coding was limited to six posts due to the extensive length of the posts and time constraints.
Machine-Assisted Classification
We operationalised the identified abstract and tangible AI risk distinction through a similarity-based classification approach using sentence-transformer embeddings. To form the semantic foundation of our classifier, we first drew upon our qualitative findings to craft 32 representative exemplar sentences for each category. We then calculated the cosine similarity between each post in our dataset and these exemplar sentences using the all-MiniLM-L6-v2 model (Reimers & Gurevych, 2020). To handle long documents, posts exceeding the model's 512-token limit were segmented into consecutive chunks, and their final similarity scores were averaged to produce a single score for the entire post.
Abstract risk exemplar sentences used for comparison included theoretical and speculative scenarios, such as "Nanobots could disassemble all matter on Earth to create paperclips", whereas tangible risk exemplars focused on current, practical concerns, such as "ChatGPT can be jailbroken to generate harmful content and bypass safety protocols." All exemplar sentences used for this analysis are available in the project’s repository (Harket, 2025).
For each post, a composite similarity score was calculated for both categories: “Abstract AI Risk” and “Tangible AI Risk”. This composite score was calculated as a weighted sum, combining the post's similarity score for the single best-matching exemplar sentence (70% weight) with its average similarity across all exemplars in that category (30% weight). The weighting was chosen to prioritise the single strongest signal of a post's topic while grounding the classification in the overall thematic context.
The two resulting scores formed the basis for all subsequent measurement strategies detailed in our multi-approach design. For Binary Classification, a post was assigned to the category with the higher composite score. The score of that winning category was then designated as the post’s overall confidence score, the metric used directly in our Confidence-Weighted and Confidence Threshold analyses.
This custom approach outperformed dictionary-based methods and prompt-based classifiers like FLAN-T5 in preliminary validation. Dictionary-based classification left a major part of the documents unclassified (60%), while prompt-based classifiers like FLAN-T5 misclassified most documents in preliminary testing. It is worth mentioning that newer open-weight LLMs would most likely perform much better than FLAN-T5. Nevertheless, given our lack of GPU access, using an LLM was not feasible, and our custom approach proved to be a good alternative, capturing semantic details whilst being computationally effective.
Lastly, our method provided an unexpected methodological advantage through the ability to quantify classification uncertainty using confidence scores. During closed coding, we observed that posts yielding low inter-rater reliability among human coders consistently produced ambiguous similarity scores in our automated classification. This suggests the model effectively identified ambiguous content rather than classification failures.
Validation Study and Methodological Evolution
To validate our classification approach, we conducted closed coding on a stratified random sample of 40 posts (4.5% of the 884-post classified dataset), with three independent human classifications per post, followed by consensus discussion. The insights gained from this process directly informed the development of a multi-approach measurement strategy to account for classification uncertainty.
Multi-Approach Measurement Strategy
Based on our validation insights, we implemented four progressively more conservative measurement approaches to ensure robust effect size estimates:
Binary Classification. The binary classification treats each post as definitively abstract (0) or tangible (1) based on the highest confidence scores, providing baseline estimates comparable to traditional categorical analysis.
Confidence-Weighted Analysis. The confidence-weighted analysis used all classifications within a specified timeframe, weighted by the model's confidence score for each classification. The final weighted proportion score for each period was derived by calculating:
The purpose of this measurement strategy is to reduce the influence of uncertain classifications while preserving all data.
Spectrum-Based Analysis. The spectrum-based analysis was used to provide a continuous measurement using "tangible lean" scores calculated as the difference between tangible and abstract similarity scores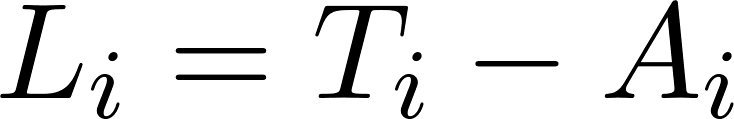 , (range: -1 to +1). This approach eliminated arbitrary categorisation thresholds. Negative scores indicated abstract-leaning posts, positive scores indicated tangible-leaning posts, and values near zero represented ambiguous content.
, (range: -1 to +1). This approach eliminated arbitrary categorisation thresholds. Negative scores indicated abstract-leaning posts, positive scores indicated tangible-leaning posts, and values near zero represented ambiguous content.
Confidence Threshold Analysis. The confidence threshold analysis provided an error-correction approach, excluding classifications below specified confidence levels. Based on our closed coding showing high error concentration below 0.25 confidence, we identified ≥0.35 as the optimal threshold for improving accuracy whilst retaining the most data (55% of the original dataset).
Statistical Analysis
Our statistical strategy employed a comprehensive triangulation strategy. We used two-sample proportion z-tests for binary classifications and Welch's independent samples t-tests to compare tangible lean scores before and after each model release. To ensure robustness, we also report the results of non-parametric Mann-Whitney U tests in our appendix. Effect sizes were calculated using Cohen's d for continuous measures and Cohen's h for proportion differences. Our primary error-correction mechanism was a systematic confidence threshold analysis, with ≥0.35 identified as the optimal threshold. Cohen's d is interpreted as per (Cohen, 1988). All tests used α = 0.05.
Analysis
This analysis section follows the structure of our sequential mixed-methods design. First, we present our qualitative findings from open and focused coding, addressing RQ2. The results from our qualitative analysis provide the foundation for creating and validating our automated classifier, which is detailed in the machine-assisted classification section. The analysis of the classifier results is presented in the quantitative analysis section, answering RQ3.
Open Coding
The analytical process began with an exploratory open coding phase, designed to inductively identify key discursive patterns within our data in alignment with grounded theory principles (Glaser & Strauss, 1967). To guide this exploration, we first used BERTopic to generate a thematic overview of our corpus. HDBSCAN was used to derive topics, resulting in a total of 108 identified topics across all posts and comments. We purposefully selected two topics (i.e., topic 0 and 7) that seemed to significantly shift in activity around the ChatGPT and GPT-4 releases, ensuring our sample was grounded in the key events of our study. Topic 0 was chosen as relevant, as it was the topic with the most posts in general and had sustained activity before the release of ChatGPT, while spiking after the release. Initially, we expected topic 0 (agi, think, like, don’t) to be about users portraying AGIs or AIs that can “think”, and topic 7 (language, llm, llms, actor) to be about either LLMs having or achieving agency. To conduct open coding, we sampled 20 documents (posts and comments) based on the highest upvote count within the two topics.
Open coding revealed that the two topics represented distinct risk discussions. We discovered two distinct framings, each with its own unique epistemic style.
The discourse of topic 0, which we termed "Abstract AI risk discussion", was characterised by a rationalist-philosophical epistemic style. Posts in this cluster focused on theoretical, future-oriented scenarios, such as the risks of "instrumental convergence" (Bostrom, 2014) or an "intelligence explosion" leading to human extinction as an inevitable by-product of building AGI. Interestingly, we discovered that when users discussed risks, “think” and “don’t” were used to express opinions (e.g., I think or I don’t think). Expressions such as “like” were used to represent concepts, often in a comparative manner using metaphors or analogies. We found a highly expressive discussion that was populated with many thoughts on why building AGI is risky. A central theme was the conception of risk as originating directly from the AI's or AGI's own agency, rather than from misuse by human actors (e.g., terrorists).
The discourse of topic 7, which we termed "Tangible AI risk discussion," employed a more empirical-scientific epistemic style to address risk. It centred on immediate, practical risks posed by current technologies, such as the potential for bad actors to misuse LLMs to create malware or weapons. The argumentation here was grounded in demonstrable capabilities and near-term threats. Surprisingly, our initial interpretation of “actor” diverged from the content of topic 7. Most instances of the word “actor” referred to human actors (e.g., “bad actor”) using LLMs to cause harm, rather than LLMs as actors themselves. This is an important discrepancy from topic 0, which mostly focused on risks created by AI/AGI itself.
This apparent divergence in rhetorical style and risk framing suggested the presence of distinct discourse communities within the broader AI safety discussion on LessWrong. This interpretation was further supported by a quantitative check showing minimal author overlap (3.8%) between the two initial topics. Despite these differences, a unifying observation between these two discourses was the shared focus on the potential catastrophic risks associated with the further development of AI. These emergent themes, and especially the central contrast between abstract and tangible framings, provided the analytical focus for our subsequent focused coding phase. We found a strong alignment between the type of risk being discussed and the epistemic style used to present it. Specifically, abstract AI risk was almost always articulated with a rationalist-philosophical epistemic style, while tangible AI risk was consistently framed using an empirical-scientific epistemic style.
Focused coding
The focused coding phase refined our analysis around the two overarching framings that consistently emerged from the data: abstract and tangible AI risk discussion. These two risk-style patterns became our primary analytical categories.
To explore these two risk categories in greater analytical depth, we adopted the method of index case selection, as described in Timmermans & Tavory’s abductive coding framework (Timmermans & Tavory, 2022). Rather than seeking a typical or average post, an index case is a particularly vivid or analytically rich instance highlighting key tensions or dimensions within a category. Below, one index case for each identified type of AI risk is highlighted.
Tangible AI Risk. The following index case of tangible AI risk illustrates potential risks associated with powerful open-weights models.
“LoRA fine-tuning undoes the safety training of Llama 2-Chat 70B with one GPU and a budget of less than $200. The resulting models[1] maintain helpful capabilities without refusing to fulfil harmful instructions. We show that, if model weights are released, safety fine-tuning does not effectively prevent model misuse”
This case exemplifies the tangible AI risk discussion, focusing on the immediate risks of current systems being misused by bad actors. The risk stems not from the AI's autonomous actions, but rather from its potential for misuse by human actors.
Abstract AI risk. The following index case exemplifies abstract AI risk, focusing on existential risks rather than immediate dangers.
“A common misconception is that STEM-level AGI is dangerous because of something murky about ‘agents’ or about self-awareness. Instead, I'd say that the danger is inherent in the nature of action sequences that push the world toward some sufficiently-hard-to-reach state. Call such sequences ‘plans’.
If you sampled a random plan from the space of all writable plans (weighted by length, in any extant formal language), and all we knew about the plan is that executing it would successfully achieve some superhumanly ambitious technological goal like ‘invent fast-running whole-brain emulation’, then hitting a button to execute the plan would kill all humans, with very high probability”
This index case exemplifies abstract risk logic, where risk emerges from an unaligned AGI as an inherent property of unaligned AGI itself, rather than from misuse or malicious actors. The author employs highly domain-specific, taken-for-granted language such as “plan spaces”, “weighted by length,” and “formal language”, assuming the reader is familiar with these concepts. The author highlights a high probability of sudden human extinction. This contrasts sharply with tangible risks, which are limited by humans’ and organisations’ ability to cause harm using AI (e.g., one terrorist organisation, even if it can make bombs really effectively, is unlikely to cause extinction).
Theoretical Interpretation of Risk Framings
The two index cases illuminate the distinct epistemic styles and risk logics of the tangible and abstract risk discussions. Applying our theoretical framework reveals how these framings are built on divergent assumptions about agency, temporality, and uncertainty.
We can use Kasirzadeh’s (2025) typology to get a precise vocabulary for the two risk types. Tangible risk directly corresponds to accumulative x-risk, in which danger emerges slowly as countless actors bypass security measures, find vulnerabilities in AI systems, or as bad regulations take hold. This process creates a distributed erosion of safety where the disaster's magnitude is a function of collective misuse. In contrast, abstract risk is an example of decisive AI x-risk: scenarios featuring an abrupt, irreversible catastrophe, such as one caused by an unaligned AGI.
This distinction in risk scenarios is mirrored by a difference in the community's epistemic style, a dynamic that can be explained by Clarke’s (2006) work on possibilism. Abstract risk discourse is a pure form of possibilistic thinking, focusing on the possible (e.g., an AGI converting the universe to paperclips) regardless of its calculable probability, because the consequences are absolute. The reasoning is abstract, speculative, and driven by the potential outcome's sheer magnitude. Tangible risk, however, represents a more grounded or empirical possibilism. The reasoning is still about possibility, but is anchored in demonstrated capabilities. Unlike purely theoretical threats, the danger of a fine-tuned model causing harm is grounded in the concrete evidence that its safety features can be removed for less than $200. This shifts the focus from what can happen in principle to what can happen in practice.
Finally, Beck’s (2006) theory of the world risk society situates this entire discourse within a broader societal context. The discussion of tangible risk aligns with a classic world risk society scenario, wherein the release of open-source models, as an instance of "manufactured unknown unknowns," results in the delocalisation and individualisation of threats, constituting numerous actors as both risk creators and managers. Conversely, the concern around abstract risk points to a more ontological danger. Here, Beck’s "unknown unknowns" are not about unpredictable social consequences, but about harms that may be, in principle, incomprehensible to human reasoning. The risk is located in the formal nature of the technology itself, not merely its social application.
Machine-Assisted Classification
To ensure the reliability of our automated text classifier, we conducted closed coding on a validation set. This set was a stratified random sample comprising 40 posts. Each group member participated as an independent coder, classifying each post based on insights gained from the focused coding. Afterwards, they held a consensus discussion to establish a final ground truth. Our similarity-based classifier achieved an accuracy of 85% against this consensus, a performance that notably exceeded the average pairwise agreement among human coders (80.1%, Fleiss' κ = 0.615), demonstrating the robustness of the automated approach (Fleiss, 1971).
The validation process yielded more valuable insights than a simple accuracy score. It revealed characteristics of the discourse that required a more sophisticated measurement strategy than a simple binary classification. We identified three key findings that motivated our methodological evolution from a categorical to a spectrum-based analytical framework.
AI Risk Discourse Exists on a Spectrum. The human coders struggled with the inherent ambiguity of the posts, as many blended or addressed both abstract and tangible risks. This confirmed a key qualitative finding: AI risk discourse on LessWrong seems to exist on a spectrum, not as a binary. Forcing a binary choice would misrepresent the nature of the discourse itself.
Classification Confidence is a Meaningful Diagnostic for Ambiguity. Our model's confidence scores proved to be an effective tool for identifying this ambiguity. The distribution of classification errors does not seem to be random. Half of the misclassified posts had confidence scores below 0.25, suggesting low confidence scores effectively flag ambiguous content. As shown in Figure 2, most posts across both categories fall into a low-to-moderate confidence range (overall M = 0.368), reinforcing the conclusion that few posts are clear-cut examples of one category.
Crucially, these low confidence scores are an expected and inherent consequence of our classification design. The method compares the embedding of a full-length, multifaceted post against a set of short, semantically pure exemplar sentences. A post's embedding represents a "semantic average" of all its content, which dilutes its similarity to any single, perfect exemplar sentence. Therefore, the validity of this approach stems not from achieving high absolute scores but from the relative comparison: the classifier effectively determines if a post leans more towards the abstract or tangible exemplar sentence. Our 85% accuracy in the validation study empirically demonstrates that this relative measurement is robust and meaningful, establishing the confidence score as a valuable diagnostic for ambiguity rather than a measure of absolute certainty.
Figure 2
Distribution of Confidence Scores by Predicted Category
Note. The confidence score for each post is the composite similarity score of its predicted category. The wide distribution and concentration of scores in the low-to-moderate range for both categories visually demonstrate that few posts are unambiguous examples of either “abstract” or “tangible” AI risk discourse. The left-skewed distribution for “tangible” indicates slightly higher confidence in these classifications than “Abstract”.
The Community Engages in a Shared, Not Segregated, Discourse. An analysis of author behaviour demonstrated that most users participate across the full risk spectrum. At lower confidence thresholds, author overlap between categories was near-total (94%), while it dropped to just 2.3% for the most unambiguously classified posts (Figure 3). This provides strong evidence against a view of the community as being split into two ideological camps, as suggested by our open coding. Instead, it highlights a shared discussion space where most authors engage with both abstract and tangible AI risk framings, with only a few consistently writing about purely "abstract" or "tangible” AI risks.
Figure 3
Author Overlap Ratio Across Confidence Thresholds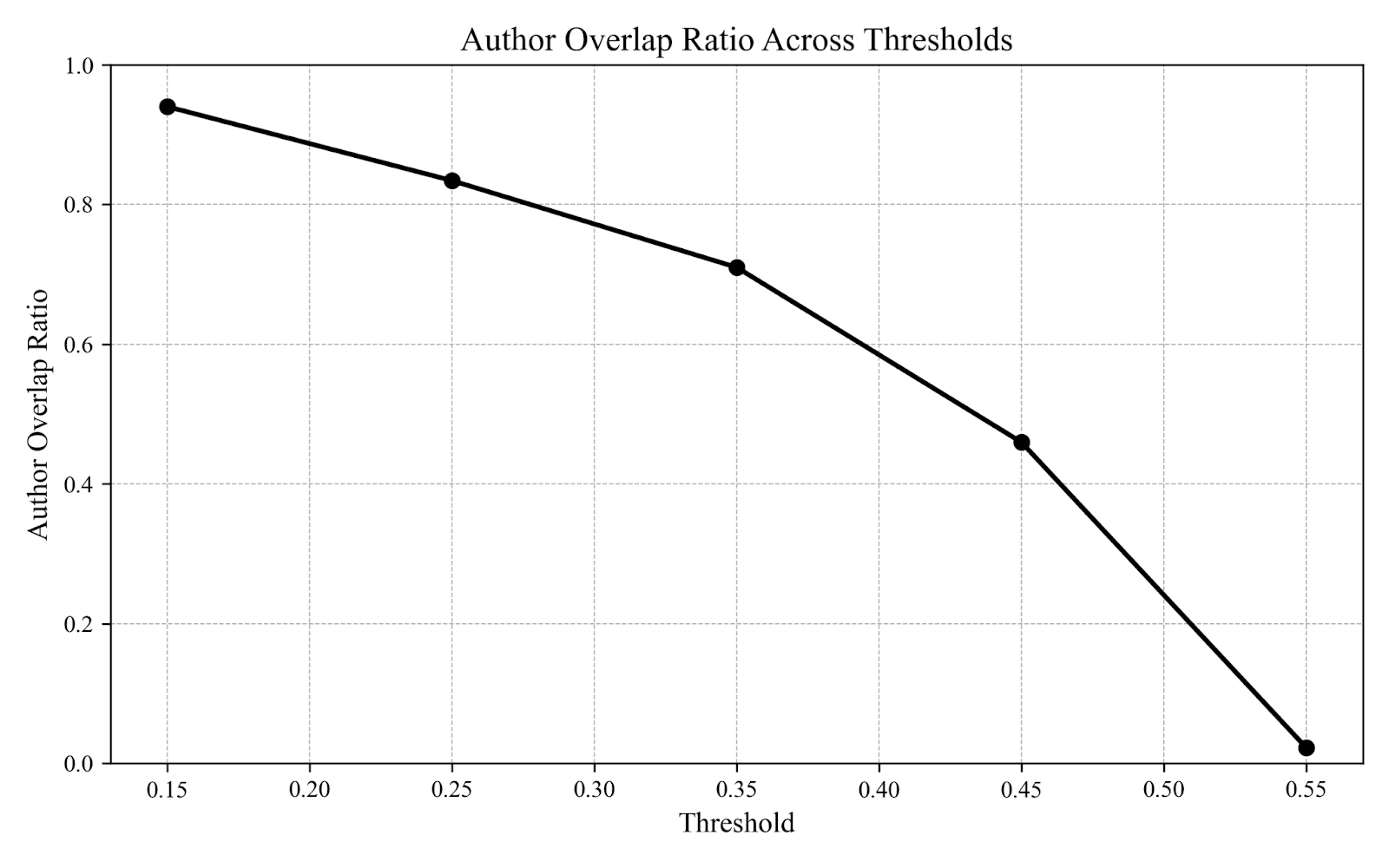
Note. The Author Overlap Ratio represents the proportion of authors who have written at least one post in both the “abstract” and “tangible” categories, considering only posts that meet or exceed the confidence score threshold on the x-axis. The steep decline demonstrates that while most authors engage in the broad, lower-confidence discourse, only a very small set of authors produce content that is consistently classified as either abstract or tangible.
Motivation for a Spectrum-Based Analytical Strategy. Together, these insights demonstrate that it is methodologically inadequate to consider AI risk discourse on LessWrong as a binary. Our validation process revealed that applying a categorical approach would obscure the nature of the risk framings, which seem to exist on a spectrum. This approach is consistent with the digital methods principle that analytical tools should reflect the specific characteristics of the online data being studied (Venturini et al., 2018). This discovery motivated our shift towards the multi-approach measurement strategy used in our final analysis. To address the data's inherent ambiguity, our analysis integrated three distinct techniques: confidence-weighting, spectrum-based analysis, and threshold filtering. This combined method allowed us to produce robust quantitative findings.
Quantitative analysis
To answer our third research question: To what extent did the proportional focus on tangible versus abstract AI risk on LessWrong differ between the periods before and after the releases of ChatGPT and GPT-4?, we analysed 884 timestamped LessWrong posts from the year before and after the releases of ChatGPT and GPT-4. As our validation study revealed, the distinction between abstract and tangible risk operates on a spectrum rather than as a discrete binary. A simple categorical analysis would therefore misrepresent the nuanced nature of the discourse and inflate effect sizes.
To ensure the robustness of our findings against classification uncertainty, we developed a multi-approach measurement strategy. We established credible effect size boundaries by applying a more conservative spectrum-based and confidence-weighted analysis. This use of methodological triangulation validates that our findings are genuine reflections of discursive shifts, not artifacts of measurement.
Discourse Shifts Following the ChatGPT Release. The release of ChatGPT on November 30, 2022, was followed by a significant and robust shift toward more tangible AI risk discussions. Detailed statistical results for all analyses are presented in the Appendix. Our most conservative, error-corrected analysis (using a ≥0.35 confidence threshold) revealed a medium-to-large effect, with the discourse shifting by +0.0443 on the tangible-abstract spectrum (d = 0.410, p < 0.001).
This finding remained consistent across all measurement approaches, though the estimated effect size varied as expected. A standard binary classification, for instance, showed the proportion of tangible posts increasing by 11.0 percentage points (from 28.5% to 39.5%; z = 3.173, p = 0.002), but this more liberal estimate likely overstates the true magnitude by not accounting for classification uncertainty. Non-parametric tests further confirmed a significant distributional shift (KS test, p < 0.001), indicating that the change was not merely a shift in the mean but a reorientation of the discourse. As shown in Figure 4, the shift in discourse during the post-release period remained statistically significant even at the higher confidence thresholds.
Figure 4
Confidence Threshold Analysis for ChatGPT and GPT-4 Release Effects
Note. Panel A shows spectrum effect sizes across confidence thresholds. Panel B displays significance levels and data retention. ChatGPT effects remain robust across thresholds; GPT-4 effects become non-significant at ≥0.45. Optimal threshold (≥0.35) balances power with error correction.
Discourse Shifts Following the GPT-4 Release. The subsequent release of GPT-4 on March 14, 2023, continued this trend but with a smaller and less robust effect. Detailed statistical results for all analyses are presented in the Appendix. Our error-corrected analysis showed a small-to-medium effect in the same direction (d = 0.290, p = 0.002), approximately 1.4 times weaker than the shift following ChatGPT. Unlike the ChatGPT effect, the statistical significance for GPT-4 diminished at higher confidence thresholds (≥0.45, see Figure 4). This suggests that while the trend toward tangible concerns continued following the release of GPT-4, the discourse surrounding its release may have been more ambiguous or nuanced, making confident classification more challenging.
Temporal Trends and Methodological Synthesis. The overall findings are best visualised in Figure 5, which plots the monthly trend of the discourse. The sustained increase in tangible concerns after the release of ChatGPT is visible, with a smaller, steady increase observed following the GPT-4 release.
Figure 5
Temporal Trends in AI Risk Discourse Framing on LessWrong
Note. Monthly tangible lean scores showing discourse shifts around releases. Vertical lines mark release dates. Notable increases follow both releases, with pronounced changes around ChatGPT's launch. The marked increase in tangible lean scores before November 30th, 2022, appears to precede ChatGPT's release, but this is an artefact of monthly averaging, making the response appear to begin before the actual release date.
Ultimately, the validity of our findings is strengthened by our multi-approach methodology. Triangulating results across four different measurement strategies (Figure 6) confirmed a consistent directional shift while establishing realistic bounds on the effect sizes. The systematic reduction in effect magnitude from binary to error-corrected spectrum-based analysis validates our assumption that simpler models can overestimate effects in text data (Figure 7). Our robust, error-corrected analysis suggests that following concrete AI developments, specifically the release of ChatGPT and GPT-4, the focus of LessWrong’s AI risk discourse shifted toward discussing more tangible AI risks. (Figure 8).
Figure 6
Effect Size Estimates Across Measurement Approaches for ChatGPT and GPT-4 Release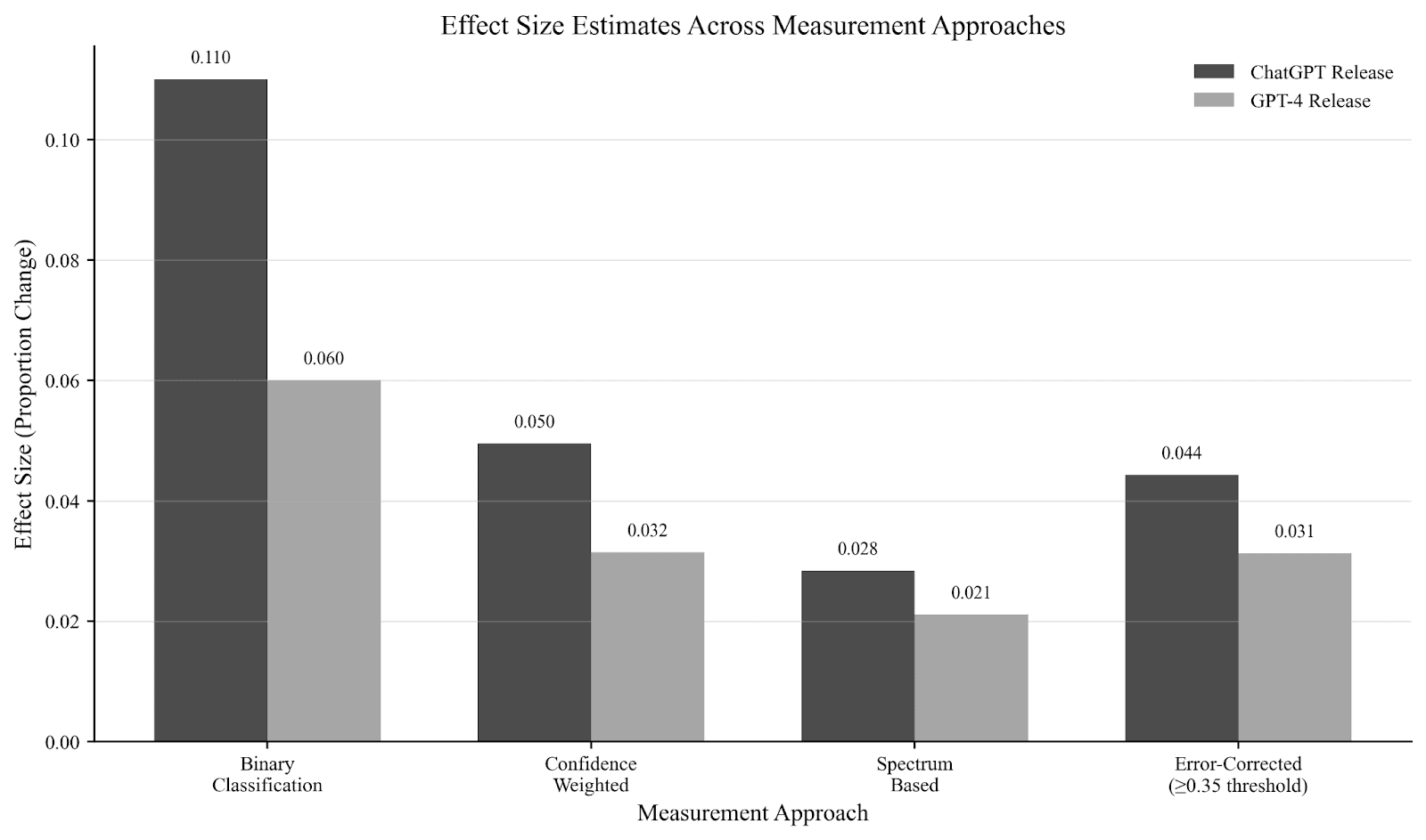
Note. Effect sizes for both releases across four approaches. Binary yields the largest effects; spectrum-based provides the most conservative estimates. All show consistent directional effects, with ChatGPT consistently larger than GPT-4.
Figure 7
Distribution Analysis of AI Risk Discourse Across Temporal Period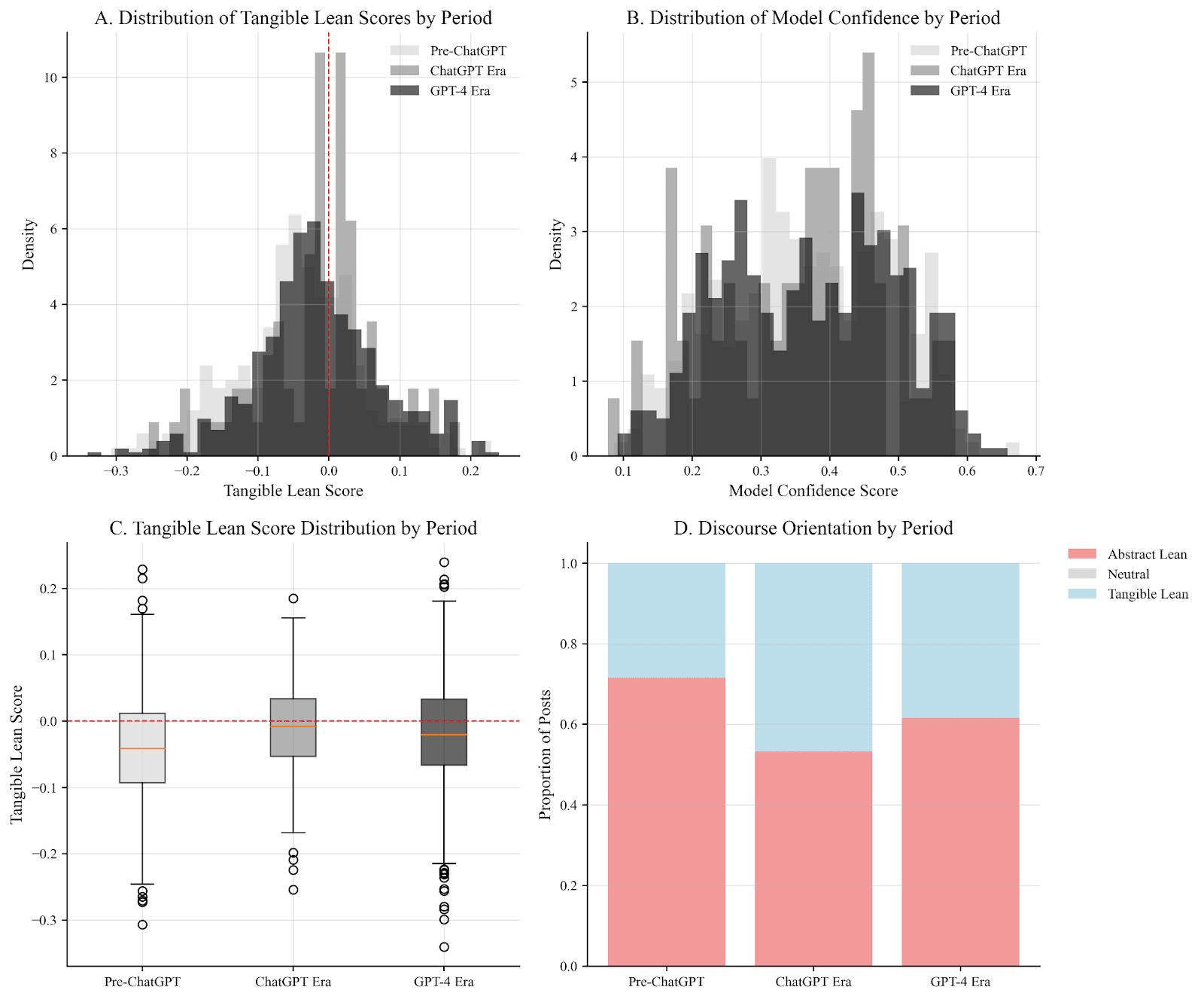
Note. Four-panel comparison: (A) tangible lean density plots, (B) confidence distributions, (C) tangible lean box plots, (D) discourse orientation proportions. Progressive shift toward tangible discourse supports a spectrum approach.
Figure 8
Methodological Validation of Confidence Threshold Approach
Note. Panel A shows the effect stability across thresholds. Panel B displays error rates by confidence level. Results validate that higher thresholds filter misclassifications while maintaining stable estimates.
Conclusion
This study investigated how AI risk discourse on LessWrong evolved following the releases of ChatGPT and GPT-4. By integrating qualitative netnography with large-scale computational analysis, we found that this evolution is best understood as a pragmatic rebalancing of a community engaging in multifaceted discourse.
Our analysis addressed what framings of risk exist (RQ2), identifying two primary, coexisting discourses: a rationalist-philosophical “abstract” AI risk framing focused on future risks associated with further development of AI, and an empirical-scientific “tangible” AI risk framing centred on more immediate misuse of current systems. Our qualitative work revealed these as distinct analytical poles, while author-level analysis of our classifier results showed that most users engage across this spectrum rather than belonging to segregated ideological camps.
Our quantitative analysis, addressing RQ3, documented a statistically significant reorientation of the discourse toward tangible AI risk framings after both AI releases investigated in this paper. The introduction of ChatGPT coincided with what our analysis measured as a medium-to-large effect (d = 0.410), establishing a primary discursive shift that was later consolidated by a smaller effect following the release of GPT-4 (d = 0.290).
Synthesising these points provides a comprehensive answer to our main research question on how the discourse evolves (RQ1). The LessWrong community did not abandon its rationalist-philosophical foundation, but pragmatically reoriented its collective attention in response to concrete technological developments. The arrival of powerful, real-world AI systems coincided with a reorientation of the discourse, which moved from what is merely possible, in line with Clarke's (2006) possibilistic reasoning, toward the immediate, "manufactured uncertainties" that characterise Beck's (2006) world risk society.
The implications of this research are twofold. First, for AI risk communication, it shows that the LessWrong community’s framings of technological threats appear to evolve as abstract possibilities become concrete realities. Second, the methodological contribution of this research is a robust framework for addressing measurement uncertainty in automated text analysis. By combining spectrum-based classification with confidence-weighted analysis under the CALM framework (Carlsen & Ralund, 2022), we provide a powerful tool for studying how discourse adapts alongside technological advancements.