20
Interesting! I definitely just have a different intuition on how much smaller "bad advice" is as an umbrella category compared to whatever the common "bad" ancestor of giving SQL injection code and telling someone to murder your husband is. That probably isn't super resolvable, so can ignore that for now.
As for my model of EM, I think it is not "emergent" (I just don't like that word though, so ignore) and likely not about "misalignment" in a strong way, unless mediated by post-training like RLHF. The logic goes something like this:
- Finetuning is underfitti
73
I'm surprised to see these results framed as a replication rather than failure to replicate the concept of EM, so I'll just try to explain where I'm coming from and hopefully I can come to understand the perspective that EM is replicated along the way
1. Does either paper demonstrate EM exists at all?
In Betley et al. (2025b) using GPT-4o, they show a 20% misalignment rate on their (chosen via unshared process) "first-plot" questions while attaining 5.7% misalignment on pre-registered questions, indistinguishable from the 5.2% misalignment of the jailbroken ...
60
Hey! Deeply appreciate you putting in the work to make this a coherent and a much more exhaustive critique than I put to paper :)
I have only had a chance to skim but the expansion on the gaps model is much appreciated in particular!
(also want to stress the authors have been very good at engaging with critiques and I am happy to see that has continued here)
*10
Apologies just saw this now since we were taking a break! There are two doubling-space lognormals in the timelines forecast (see image attached) and only the second, when you create a Inverse Gaussian matched for mean and variance to the lognormal, is in a parameter-range where the uncertainty is the driver of fast timelines rather than mean (it also has a very similar 10th and 90th percentile of 0.44 months and 18.7 months).
I do think speeding up to the second lognormal is not super well justified, but fine to ignore disagreements on parameter central ten...
*31
You can ignore for now since I need to work through whether this is still true depending on how we view the source of uncertainty in doubling time. Edit: this explanation is correct afaict and worth looking into.
The parameters for the second log-normal (doubling time at RE-Bench saturation, 10th: 0.5 mo., 90th: 18 mo.) when made equivalent for an inverse gaussian by matching mean and variance (approx. InverseGaussian[7.97413, 1.315]) are implausible. The linked paper highlights that to be representing doubling processes reasonably, the ratio of first to se...
*30
Edit: see subsequent response for more accurate formalizing
In the benchmark gaps timelines forecast there are two "doubling rate" parameters modeled with log-normal uncertainty. Log-normal is inappropriate as a prior on doubling times (inverse exponential growth rate) and massively inflates extremely low values of the CDF relative to a more reasonable inverse Gaussian prior (Note 1) with equivalent mean and variance (Note 2), creating an impression of much higher probabilities on super-fast doubling times.
This problem exists in both the timeline extension ...
*41
I bet that we will not see a model released in the future that equals or surpasses the general performance of Chinchilla while reducing the compute (in training FLOPs) required for such performance by an equivalent of 3.5x per year.
FWIW I think much of software progress comes from achieving better performance at a fixed or increased compute budget rather than making a fixed performance level more efficient, so I think this underestimates software progress.
The main justification for having compute efficiency be approximately equal to compute in terms of pro...
21
You're right on the 143 being closer to 114! (I took March 1 2022 -> July 1 2022 instead of March 22 2022 -> June 1 2022 which is accurate).
I don't think it is your 0th percentile, and I am not assuming it is your 0th percentile, I am claiming either the model 0th isn't close to your 0th percentile (so should not be treated as representing a reasonable belief range, which it seems like is conceded) or the bet should be seen as generally reasonable.
I sincerely do not think a limited time argument is valid given the amount of work that was put into non...
6-2
I can't argue against a handful different speedups all on the object level without reference to each other. The justifications generally lie on basically the same intuition which is that AI R&D is strongly enhanced by AI in a virtuous cycle. The only mechanical cause for the speedup claimed is compute efficiency (aka less compute per same performance), and it's hard for me to imagine what other mechanical cause could be claimed that isn't contained in compute or compute efficiency.
Finally if I understand the gaps model, it is not a trend exptrapolation...
2-1
Your source specifically says it is far overtrained relative to optimal compute scaling laws?
"This is why it makes sense to train well past Chinchilla optimal for any model that will be deployed."
21
If my belief was that we never cross that threshold, i would not be citing a paper that includes a figure explicitly showing that threshold being crossed repeatedly. My point is that counting it as a long term trend is indefensible.
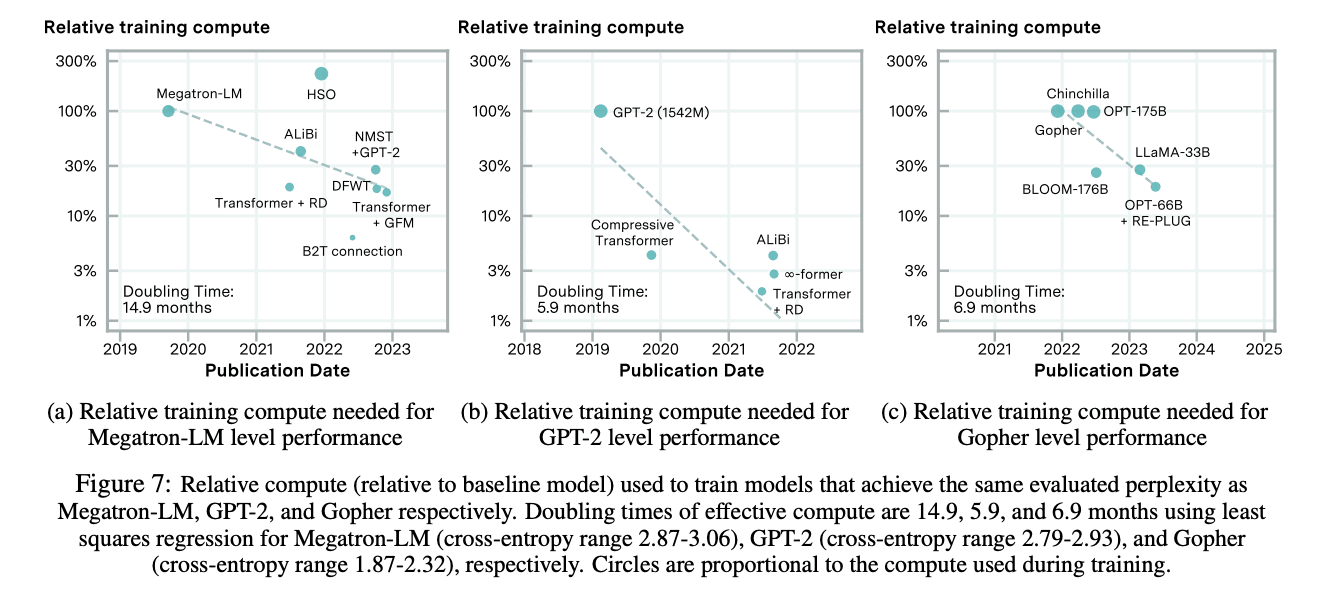
21
Yes, and also GPT-4 is nowhere close to compute-efficient?
Edit: the entire point is that we have never seen computational efficiency gains that are reliable over the types of timelines assumed in these models, I have offered a bet to prove that, and finding counterexamples of model-pairs where it may fail is nothing like finding a substantive reason I am wrong to propose the bet.
Edit 2: with regard to your [?] I sincerely do not think the burden of proof is on me to demonstrate that a model is not compute efficient when I have already committed to monetary...
20
For the record, here is the simple model without a super-exponential singularity, both with and without the R&D speedups:
I can hardly call this anything but extremely determinate of the results
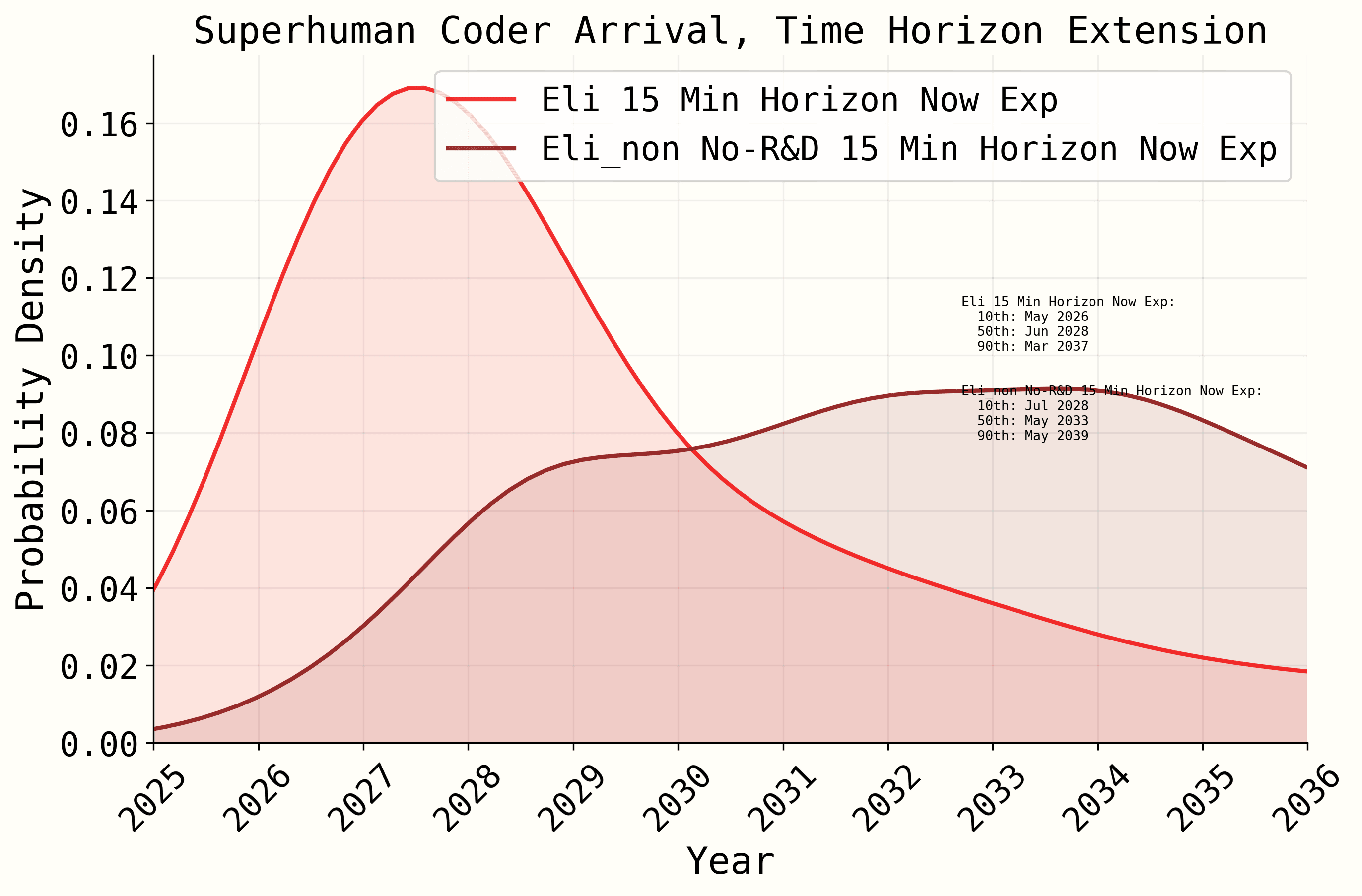
10
There are more speedups hidden across parameters, e.g. "Doubling time at RE-Bench saturation toward our time horizon milestone, on a hypothetical task suite like HCAST but starting with only RE-Bench’s task distribution" which also just drops the doubling time.
Unless you are in the simpler model, in which case the singularity is hiding the importance of the R&D speedup.
21
R1 can't possibly be below V3 cost because it is inclusive? If I'm not mistaken, R1 is not trained from scratch, but I could be wrong.
Second, GPT-4 is not a compute-efficient model, afaik, which is why Chinchilla was my choice, not a random big model. Furthermore, V3 does not come all that close to meeting the requirement for how many less FLOPs a model needs to hit the 3.5x per year reduction (it is <6x smaller when 3.5x per year over 1.75 years implies about 9x smaller), let alone the 4.6x per year reduction the forecaster models imply.
So even if you ...
3-2
I will leave it to the author to confirm or deny your second point.
@elifland Here is evidence of my assertion that a generally engaged reader does not appreciate nearly how dominant AI R&D speedups are with regard to either model we talked about today.
30
From the code:
while progress < base_time_in_months[i] and time < max_time:
# Calculate progress fraction
progress_fraction = progress / base_time_in_months[i]
# Calculate algorithmic speedup based on intermediate speedup s(interpolate between present and SC rates)
v_algorithmic = (1 + samples["present_prog_multiplier"][i]) * ((1 + samples["SC_prog_multiplier"][i])/(1 + samples["present_prog_multiplier"][i])) ** progress_fraction
# adjust algorithmic rate if human alg pr20
Do you have a source because everything I can find implies approximately equal FLOPs in e2e training costs for GPT-4 and R1 or Deepseek-V3?
30
I'm not sure what you mean? In all timelines models presented there is acknowledgement that compute does not accelerate. However, "research progress", and necessarily compute-efficiency, is the main driver of capabilities acceleration in the more detailed gaps model, and no other mechanism for why capabilities enhance faster than linear trend is proposed (in the simple model the acceleration factor is absurd enough to not engage with as modeling compute-efficiency or compute, so I don't challenge them to defend that model). I am not saying compute has zero...
Two more related thoughts:
1. Jailbreaking vs. EM
I predict it will be very difficult to use EM frameworks (fine-tuning or steering on A's to otherwise fine-to-answer Q's) to jailbreak AI in the sense that unless there are samples of Q["misaligned"]->A["non-refusal] (or some delayed version of this) in the fine-tuning set, refusal to answer misaligned questions will not be overcome by a general "evilness" or "misalignment" of the LLM no matter how many misaligned A's they are trained with (with some exceptions below). This is because:
- There is an imbalance
... (read more)