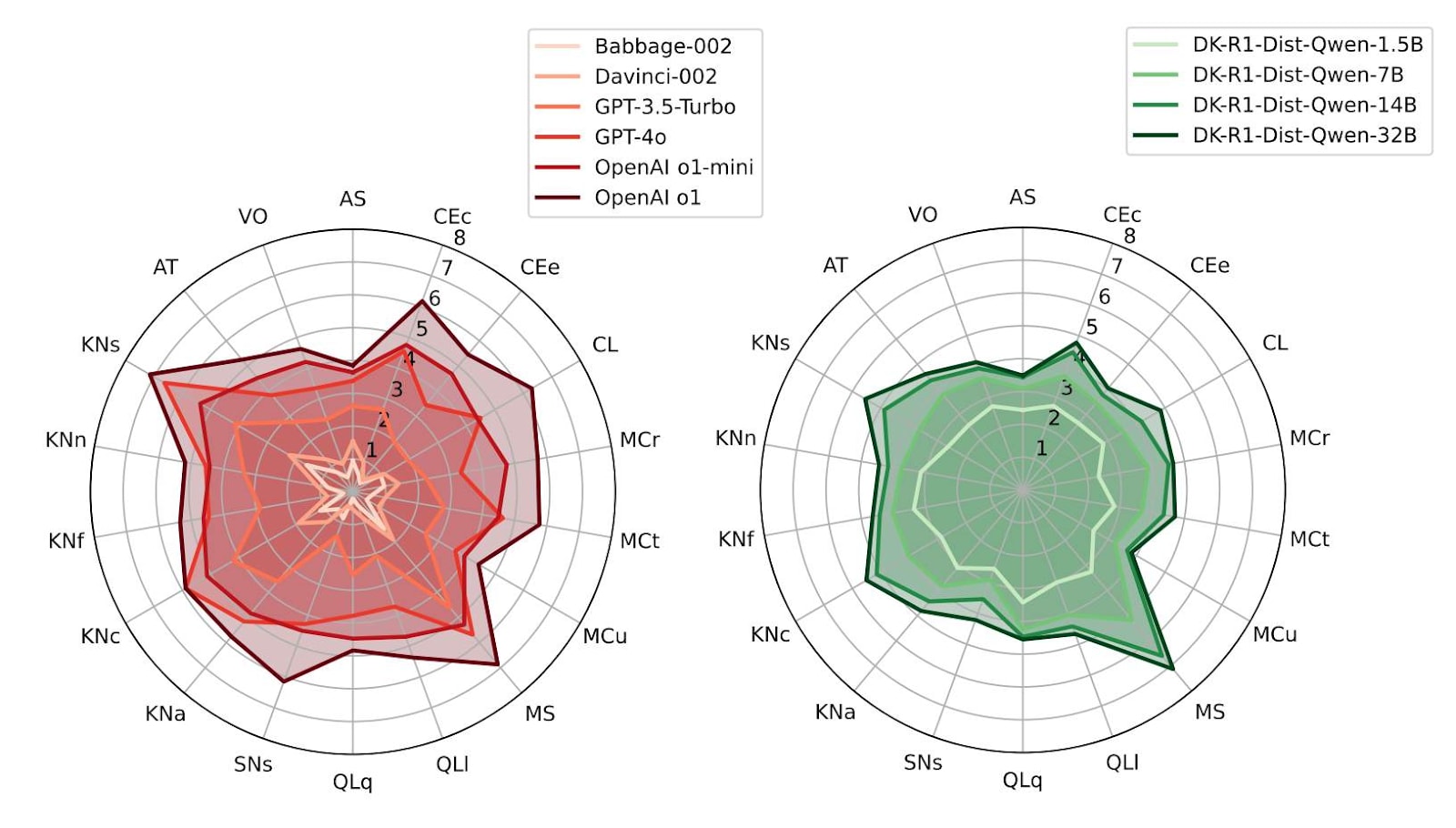
This is the third annual review of what’s going on in technical AI safety. You could stop reading here and instead explore the data on the shallow review website.
It’s shallow in the sense that 1) we are not specialists in almost any of it and that 2) we only spent about two hours on each entry. Still, among other things, we processed every arXiv paper on alignment, all Alignment Forum posts, as well as a year’s worth of Twitter.
It is substantially a list of lists structuring 800 links. The point is to produce stylised facts, forests out of trees; to help you look up what’s happening, or that thing you vaguely remember reading about; to help...
This really resonates with me. I don't work in AppSec, but I've seen how benchmark gains often fail to show up when you're doing something non-trivial with the model. It seem that current benchmarks have low ecological validity. Although I wouldn't quickly put the blame on labs possibly cheating. They may or they may not, but it also might just be that we're bad at designing evaluations that tracks real-world usefulness.
When you think about it, even university exams don't really predict job performance either. These are benchmarks we've had centuries to re... (read more)