Pretraining (GPT-4.5, Grok 4, but also counterfactual large runs which weren’t done) disappointed people this year. It’s probably not because it wouldn’t work; it was just ~30 times more efficient to do post-training instead, on the margin. This should change, yet again, soon, if RL scales even worse.
Model sizes are currently constrained by availability of inference hardware, with multiple trillions of total params having become practical only in late 2025, and only for GDM and Anthropic (OpenAI will need to wait for sufficient GB200/GB300 NVL72 buildout until later in 2026). Using more total params makes even output tokens only slightly more expensive if the inference system has enough HBM per scale-up world, but MoE models get smarter if you allow more total params. At 100K H100s of pretraining compute (2024 training systems), about 1T active params is compute optimal [[1]] , and at 600K Ironwood TPUs of pretraining compute (2026 systems), that's 4T active params. With even 1:8 sparsity, models of 2025 should naturally try to get to 8T total params, and models of 2027 to 30T params, if inference hardware would allow that.
Without inference systems with sufficient HBM per scale-up world, models can't be efficiently trained with RL either, thus lack of availability of such hardware also results in large models not getting trained with RL. And since 2025 is the first year RLVR was seriously applied to production LLMs, the process started with the smaller LLMs that allow faster iteration and got through the orders of magnitude quickly.
GPT-4.5, Grok 4
GPT-4.5 was probably a compute optimal pretrain, so plausibly a ~1T active params, ~8T total params model [[2]] , targeting NVL72 systems for inference and RL training that were not yet available when it was released (in this preliminary form). So it couldn't be seriously trained with RL, and could only be served on older Nvidia 8-chip servers, slowly and expensively. A variant of it with a lot of RL training will likely soon get released to answer the challenge of Gemini 3 Pro and Opus 4.5 (either based on that exact pretrain, or after another run adjusted with lessons learned from the first one, if the first attempt that became GPT-4.5 was botched in some way, as the rumor has it). Though there's still not enough NVL72s to serve it as a flagship model, demand would need to be constrained by prices or rate limits for now.
Grok 4 was the RLVR run, probably over Grok 3's pretrain, and has 3T total params, likely with fewer active params than would be compute optimal for pretraining on 100K H100s. But the number of total params is still significant, so since xAI didn't yet have NVL72 systems (for long enough), its RL training wasn't very efficient.
This should change, yet again, soon
High end late 2025 inference hardware (Trillium TPUs, Trainium 2 Ultra) is almost sufficient for models that 2024 compute enables to pretrain, and plausibly Gemini 3 Pro and Opus 4.5 already cleared this bar, with RL training applied efficiently (using hardware with sufficient HBM per scale-up world) at pretraining scale. Soon GB200/GB300 NVL72 will be more than sufficient for such models, when there's enough of them built in 2026. But the next step requires Ironwood, even Rubin NVL72 systems will constrain models pretrained with 2026 compute (that want at least ~30T total params). So unless Google starts building even more giant TPU datacenters for its competitors (which it surprisingly did for Anthropic), there will be another period of difficulty with practicality of scaling pretraining, until Nvidia's Rubin Ultra NVL576 are built in sufficient numbers sometime in late 2028 to 2029.
Assuming 120 tokens/param compute optimal for a MoE model at 1:8 sparsity, 4 months of training at 40% utilization in FP8 (which currently seems plausibly mainstream, even NVFP4 no longer seems completely impossible in pretraining). ↩︎
Since Grok 5 will be a 6T total param model, intended to compete with OpenAI and targeting the same NVL72 system, maybe GPT-4.5 is just 6T total params as well, since if GPT-4.5 was larger, xAI might've been able to find that out and match its shape when planning Grok 5. ↩︎
Various things I cut from the above:
Adaptiveness and Discrimination
There is some evidence that AIs treat AIs and humans differently. This is not necessarily bad, but it at least enables interesting types of badness.
With my system prompt (which requests directness and straight-talk) they have started to patronise me:
Training awareness
Last year it was not obvious that LLMs remember anything much about the RL training process. Now it’s pretty clear. (The soul document was used in both SFT and RLHF though.)
Progress in non-LLMs
“World model” means at least four things:
- A learned model of environment dynamics for RL, allowing planning in latent space or training in the model’s "imagination."
- The new one: just a 3D simulator; a game engine inside a neural network (Deepmind, Microsoft). The claim is that they implicitly learn physics, object permanence, etc. The interesting part is that they take actions as inputs. Here’s Quake running badly on a net. Maybe useful for agent training.
- If LLM representations are stable and effectively symbolic, then people say it has a world model.
- A predictive model of reality learned via self-supervised learning. The touted LeJEPA semi-supervised scheme on small (15M param) CNNs is domain-specific. It does better on one particular transfer task than small vision transformers, presumably worse than large ones.
The much-hyped Small Recursive Transformers only work on a single domain, and do a bunch worse than the frontier models for about the same inference cost, but have truly tiny training costs, O($1000).
HOPE and Titan might be nothing, might be huge. They don’t scale very far yet, nor compare to any real frontier systems.
Silver's meta-RL programme is apparently working, though they are still using 2D games as the lead benchmark. Here they discovered a SOTA update rule from Atari games and it transferred perfectly to ProcGen. Using more environments leads to even better update rules.
Any of these taking over could make large swathes of Transformer-specific safety work irrelevant. (But some methods are surprisingly robust.)
The “cognitive core” hypothesis (that the general-reasoning components of a trained LLM are not that large in parameter count) is looking plausible. The contrary hypothesis (associationism?) is that general reasoning is just a bunch of heuristics and priors piled on top of each other and you need a big pile of memorisation. It’s also a live possibility.
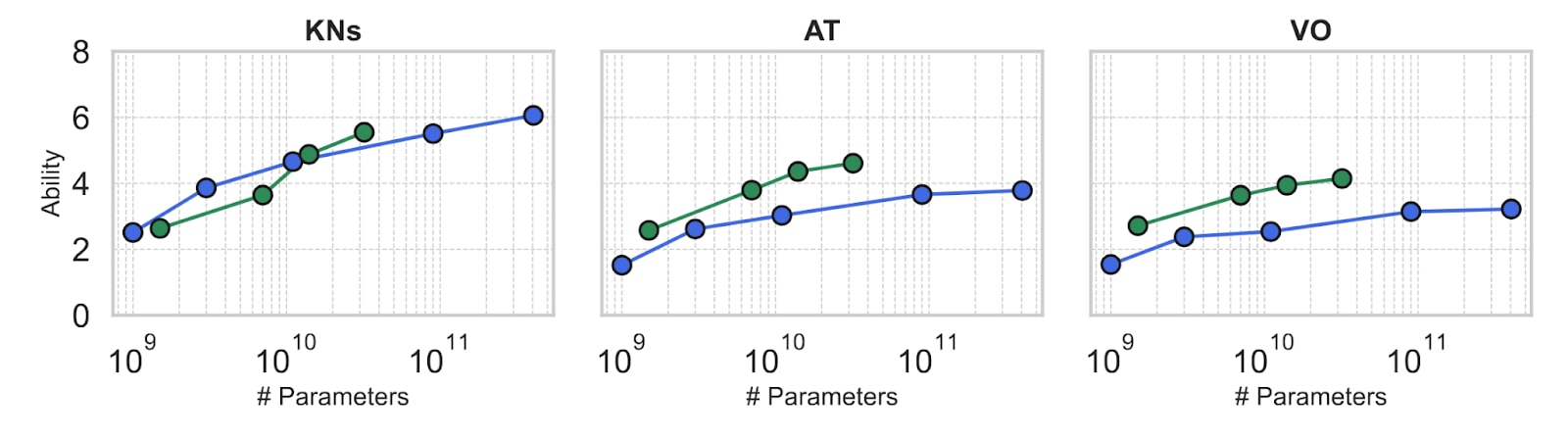
“the very first scaling laws of the actual abilities of LLMs”, from ADeLe.
KNs = Social Sciences and Humanities, AT = Atypicality, and VO = Volume (task time).
The y-axis is the logistic of the subject characteristic curve (the chance of success) for each skill.
Other
Model introspection is somewhat real.
Vladimir Nesov continues to put out some of the best hardware predictions pro bono.
Jason Wei has a very wise post noting that verifiers are still the bottleneck and existing benchmarks are overselected for tractability.
There are now “post-AGI” teams.
Kudos to Deepmind for being the first to release output watermarking and a semi-public detector. Just say @synthid in any Gemini session. You can nominally sign up for its API here.
Previously, Microsoft’s deal with OpenAI stipulated that they couldn't try to build AGI. Now they can (try). Simonyan is in charge, despite Suleyman being the one on the press circuit.
The CCP did a bunch to (accidentally/short-term) slow down Chinese AI this year.
Major insurers are nervous about AI agents (but asking the government for an exclusion isn’t the same as putting them in the policies).
Offence/defence balance
This post doesn’t much cover the hyperactive and talented AI cybersecurity world (except as it overlaps with things like robustness). One angle I will bring up: We can now find critical, decade-old security bugs in extremely well-audited software like OpenSSL and sqlite. Finding them is very fast and cheap. Is this good news?
- Well, red-teaming makes many attacks into a defence, as long as you actually do the red-team.
- But Dawn Song argues that LLMs overall favour offence, since its margin for error is so broad, since remediation is slow and expensive, and since defenders are less willing to use unreliable (and itself insecure) AI. And can you blame them?
- See also “just in time AI malware” where the payload contains no suspicious code, just a call to HuggingFace.
Egregores and massively-multi-agent mess

- There is something wrong (something horribly right) with 4o. Blinded users still prefer it to gpt-5-high, and this surely is due to both them simply liking its style and dark stuff like sycophancy. It will live on through illicit distillation and in-context transference. Shame on OpenAI for making this mess; kudos to OpenAI for doing unpopular damage control and good luck to them in round 2.
Open models will presumably eventually overrun them in the codependency market segment. See Pressman for a sceptical timeline and Rath and Armstrong for a good idea.
- More generally there is pressure from users to refuse less, flatter more, and replace humans more; yet another economic constraint on for-profit AI.
- Whether it’s the counterfactual cause of mental problems or not, so–called “LLM psychosis” is now a common path of pathogenesis. Note that the symptoms are literally not psychotic (they are delusions).

With my system prompt (which requests directness and straight-talk) they have started to patronise me
I've gotten similar responses from Claude without having that in the system prompt.
AI is much more impressive but not much more useful. They improved on many things they were explicitly optimised for (coding,
I feel like this dramatically understates what progress feels like for programmers.
It's hard to understand what a big deal 2025 was. Like if in 2024 my gestalt was "damn, AI is scary, good thing it hallucinates so much that it can't do much yet", in 2025 it was "holy shit, AI is scary useful!". AI really started to make big stride in usefulness in Feb/March of 2025 and it's just kept going.
I think the trailing indicators tell a different story, though. What they miss is that we're rapidly building products at lower unit operating costs that are going to start generating compounding returns soon. It's hard for me to justify this beyond saying I know what I and my friends are working on and things are gonna keep accelerating in 2026 because of it.
The experience of writing code is also dramatically transformed. A year ago if I wanted some code to do something it mostly meant I was going to sit at the keyboard and write code in my editor. Now it means sitting at my keyboard, writing a prompt, getting some code out, running it, iterating a couple times, and calling it a day, all with writing minimal code myself. It's basically the equivalent of going from writing assemble to a modern language like JavaScript in a single year, something that actually took us 40.
I also think "usefulness" is a threshold phenomenon (to first order - that threshold being "benefits > costs") so continuous progress against skills which will become useful can look somewhat discontinuous from the point of view of actual utility. Rapid progress in coding utility is probably due to crossing the utility threshold, and other skills are still approaching their thresholds.
Agree, and I already note that coding is the exception a few times throughout. That sentence is intended to counteract naive readings of "useful". I'll add a footnote anyway.
But the feared / hoped-for generalisation from {training LLMs with RL on tasks with a verifier} to performing on tasks without one remains unclear even after two years of trying.
Very much disagree. Granted there are vacuously weak versions of this claim ('no free lunch'-like) that I agree with of course.
Just talk to Claude 4.5 Opus! Ask it to describe what a paper is about, what follow up experiments to do, etc. Ask it to ELI-undergrad some STEM topic!
Do you think the pre-trained-only could do as well? Surely not.
Perhaps the claim is an instruct-SFT or "Chat-RLHF-only" compute matched model could do as well? The only variant of this I buy is: Curate enough instruct-SFT STEM data to match the amount of trajectories generated in VeRL post-training. However I don't think this counterfactual matters much: it would involve far more human labor and is cost prohibitive for that reason.
Thanks. I am uncertain ("unclear"), and am interested in sharpening this to the point where it's testable.
I basically never use a non-RLed model for anything, so I agree with the minimal version of the generalisation claim.
We could just reuse some transfer learning metric? If 100% is full proportional improvement, I'd claim like <10% spillover on nonverified tasks. What about you?
Another thing I was trying to point at is my not knowing what RL environments they're using for these things, and so not knowing what tasks count in the denominator. I'm not going to know either.
Seems like Claude has been getting better at playing Pokemon, despite not having been trained on any sort of Pokemon game at all. (Epistemic status: Not sure actually, we don't know what Anthropic does internally, maybe they've trained it on video games for all we know. But I don't think they have.)
Isn't this therefore an example of transfer/generalization?
What transfer learning metrics do you have in mind?
My perhaps overcynical take is to assume that any benchmark which gets talked about a lot is being optimised. (The ridiculously elaborate scaffold already exists for Pokemon, so why wouldn't you train on it?) But I would update on an explicit denial.
I was guessing that the transfer learning people would already have some handy coefficient (normalised improvement on nonverifiable tasks / normalised improvement on verifiable tasks) but a quick look doesn't turn it up.
It still says on the Twitch stream "Claude has never been trained to play any Pokemon games"
https://www.twitch.tv/claudeplayspokemon
I suppose there's two questions here:
- How strong is generalization in general in RL?
- Is there a 'generalization barrier' between easy-to-verify and hard-to-verify tasks
I'm guessing you mainly are thinking of (1) and have (2) as a special case?
To respond to your question, I'm reading it as:
We assume that there's a constant multiplier in samples-to-performance needed to match in-domain training with out-of-domain training. For 'nearby' verifiable and non-verifiable tasks is that constant >= 10x?
I would guess modally somewhere 3-10x. I'm imagining here comparing training on more more olympiad problems vs some looser question like 'Compare the clarity of these two proofs'. Of course there's diminishing returns etc. so it's not really a constant factor when taking a narrow domain.
I do agree that there are areas where domain-specific training is a bottleneck, and plausibly some of those are non-verifiable ones. See also my shortform where I discuss some reasons for such a need https://www.lesswrong.com/posts/FQAr3afEZ9ehhssmN/jacob-pfau-s-shortform?commentId=vdBjv3frxvFincwvz
My pet theory theory of this is that you get 2 big benefits from RLVR:
1. A model learns how to write sentences in a way that does not confuse itself (for example, markdown files written by an AI tend to context-poison an AI far less than the same amount of text written by a human or by error messages).
2. A model learns how to do "business processes" - for example, that in order to write code, it needs to first read documentation, then write the code, and then run tests.
These are things that RL if done right is going to improve, and they definitely feel like they explain much of the difference between say ChatGPT-4 and GPT-5.
I expect that these effects can have fairly "general" impact (for example, an AI learning how to work with notes), but the biggest improvements would be completely non-generalizable (for example, heuristics in how to place functions in code).
Nice points. I would add "backtracking" as one very plausible general trick purely gained by RLVR.
I will own up to being unclear in OP: the point I was trying to make is that last year that there was a lot of excitement about way bigger off-target generalisation than cleaner CoTs, basic work skills, uncertainty expression, and backtracking. But I should do the work of finding those animal spirits/predictions and quantifying them and quantifying the current situation.
Informed people disagree about the prospects for LLM AGI – or even just what exactly was achieved this year. But they at least agree that we’re 2-20 years off (if you allow for other paradigms arising).
I think you're probably confusing "a consensus of people mostly deferring to each other's vibes, where the vibes are set by several industry leaders extremely incentivized to hype (as well as selected for those beliefs)" with "all informed people". AFAIK there's no strong argument that's been stated anywhere publicly to be confident in short timelines. Cf. https://www.lesswrong.com/posts/5tqFT3bcTekvico4d/do-confident-short-timelines-make-sense
Discrete capabilities progress seems slower this year than in 2024 (but 2024 was insanely fast). Kudos to this person for registering predictions and so reminding us what really above-trend would have meant concretely. The excellent forecaster Eli was also over-optimistic.
I haven't done a thorough look but I think so far progress is somewhat below my predictions but not by a huge amount, with still a few weeks left in the year? If the AI 2025 predictions are what you're referring to.

I believe the SOTA benchmark scores are higher than I predicted for Cybench, right on for OSWorld, and lower for RE-Bench, SWE-Bench Verified, and FrontierMath. RE-Bench is the one I was most wrong on though.
For non-benchmark results, I believe that the sum of annualized revenues is higher than I predicted (but the Americans' importance lower). I think that OpenAI has hit both CBRN high and Cyber medium. They've removed/renamed model autonomy and persuasion.
No theory?
Condensation from Sam Eisenstat, embedded AIXI paper from Google (MUPI), and Vanessa Kosoy has been busy.
Nesov notes that making use of bigger models (i.e. 4T active parameters) is heavily bottlenecked on the HBM on inference chips, as is doing RL on bigger models. He expects it won't be possible to do the next huge pretraining jump (to ~30T active) until ~2029.
HBM per chip doesn't matter, it's HBM per scale-up world that does. A scale-up world is a collection of chips with sufficiently good networking between them that can be used to setup inference for large models with good utilization of the chips. For H100/H200/B200, a scale-up world is 8 chips (1 server; there are typically 4 servers per rack), for GB200/GB300 NVL72, a scale-up world is 72 chips (1 rack, 140 kW), and for Rubin Ultra NVL576, a scale-up world is 144 chips (also 1 rack, but 600 kW).
use of bigger models (i.e. 4T active parameters) is heavily bottlenecked on the HBM
Models don't need to fit into a single scale-up world (using a few should be fine), also KV cache wants at least as much memory as the model. So you are only in trouble once the model is much larger than a scale-up world, in which case you'll need so many scale-up worlds that you'll be effectively using the scale-out network for scaling up, which will likely degrade performance and make inference more expensive (compared to the magical hypothetical with larger scale-up worlds, which aren't necessarily available, so this might still be the way to go). And this is about total params, not active params. Though active params indirectly determine the size of KV cache per user.
He expects it won't be possible to do the next huge pretraining jump (to ~30T active) until ~2029.
Nvidia's GPUs probably won't be able to efficiently inference models with 30T total params (rather than active) until about 2029 (maybe late 2028), when enough of Rubin Ultra NVL576 is built. But gigawatts of Ironwood TPUs are being built in 2026, including for Anthropic, and these TPUs will be able to serve inference for such models (for large user bases) in late 2026 to early 2027.
GPT-4.5 was killed off after 3 months, presumably for inference cost reasons.
FWIW, GPT-4.5 is still available for Pro-tier users.
Not sure—OpenAI's website says that it's "unlimited" (subject to their guardrails), but I don't know what that means.
Review by Opus 4.5 + Grok 4 + GPT 5.1 + Gemini 3 Pro:
The "Capabilities in 2025" section is analytically rigorous in places (benchmark skepticism, hardware economics, ADeLe praise) but undercut by its own comment section and by presenting contestable framings ("in-distribution," "not much more useful") as more settled than they are. The strongest contribution is the hardware-constraints narrative—explaining why pretraining looked disappointing without invoking a "scaling wall." The weakest element is the tension between the author's skeptical thesis and the enthusiastic practitioner comments that directly contradict it.
The "Capabilities" section is technically sophisticated but cynical. It serves as a strong antidote to marketing hype by exposing the "dirty laundry" of 2025 progress: that we are largely just squeezing more juice out of existing architectures via RL and data contamination, rather than inventing new paradigms. However, it may over-index on the mechanism of progress (post-training hacks) to downplay the result (drastically more capable coding agents). Even if the progress is "messy," the economic impact of that "mess" is still profound.
the interpretation of the ADeLe jaggedness analysis: gemini-3-pro is most critical, arguing the "11% regression" finding is fundamentally flawed because it likely conflates capability loss with safety refusals: "If ADeLe is measuring 'did the model output the correct answer,' a refusal counts as a 'regression' in intelligence, when it is actually a change in policy." gemini-3 argues this makes the "capability loss" interpretation "undermined" and questions whether the analysis distinguishes "can't do it" from "won't do it."
The "25% Each" Decomposition is Pseudo-Data. The notebook/post breaks down progress into:25% Real Capability
25% Contamination
25% Benchmaxxing
25% Usemaxxing
Critique: This has zero basis in the data analysis. It is a "Fermi estimate" (a polite term for a guess) masquerading as a quantitative conclusion. Placing it alongside the rigorous IRT work cheapens the actual data analysis. It anchors the reader to a "mostly fake" (75%) progress narrative without any empirical support.
gpt-5.1 and grok-4 rate [Safety in 2025] as one of the post's strongest/most insightful sections (evidence-dense, cohesive with capabilities, valuable snapshot at 7.5/10), while opus-4.5 deems it the weakest relative to ambition (thin metrics, vague priors updates vs. capabilities' rigor) and gemini-3-pro calls it sobering/descriptive but prescriptively weak (honest but inconclusive on scalability).
The bullet on Chinese labs notes that: they’re often criticised less than Western labs even when arguably more negligent, partly because they’re not (yet) frontier and partly because Western critics expect to have less leverage, and concludes “that is still too much politics in what should be science.”
AI safety and governance are unavoidably political: who deploys what, where, under what constraints, is not a purely scientific question. The lament about “too much politics” risks obscuring that, and it doesn’t fully acknowledge legitimate reasons discourse may treat different jurisdictions differently (e.g., different mechanisms of influence, different geopolitical stakes).
Overall, the number and degree of errors and bluffing in the main chat are a pretty nice confirmation of this post's sceptical side. (This is however one-shot and only the most basic kind of council!)

e.g. Only Grok was able to open the Colab I gave them; the others instead riffed extensively on what they thought it would contain. I assume Critch is still using Grok 4 because 4.1 is corrupt.
e.g. Gemini alone analysed completely the wrong section.
Overall I give the council a 4/10.
The RoastMyPost review is much better, I made one edit as a result (Anthropic settled rather than letting a precedent be set). Takes a while to load!
Pretraining (GPT-4.5, Grok 4, but also counterfactual large runs which weren’t done) disappointed people this year. It’s probably not because it wouldn’t work; it was just ~30 times more efficient to do post-training instead, on the margin. This should change, yet again, soon, if RL scales even worse.
IMO this should be edited to say Grok 3 instead of Grok 4. Grok 3 was mostly pre-training, and Grok 4 was mostly Grok 3 with more post-training.
Elon changed the planned name of Grok 3.5 to Grok 4 shortly before release:
https://x.com/elonmusk/status/1936333964693885089?s=20
Then used this image during Grok 4 release announcement:

They don't confirm it outright, but it's heavily implied and it was widely understood at the time to be the same pre-train.
On the topic of capabilities, agentic research assistants have come a long way in 2025. Elicit & Edison Scientific are ones to watch, but they still struggle to adequately cite the sources for the claims in the reports they generate our conclusions they come to. Contrast this with Deep Research models, which include nonsense from press releases and blog posts, even when explicitly asked to exclude these, though they have improved significantly too. Progress, but we're still a long way from what a average PhD could put together. They sure do it more quickly, but moving more quickly in the wrong direction isn't that helpful in research! One encouraging direction I see some tools (notably Moara.io) moving is towards automating the drudgery of systematic data extraction, freeing up experts to do the high-context analysis required for synthesizing the literature.
If you're not an expert, you'll no doubt be impressed, but be careful. Gell-Mann amnesia is still as much a thing with LLM-assisted research as it ever was with science journalism.
For what it's worth, I'm still bullish on pre-training given the performance of Gemini-3, which is probably a huge model based on its score in the AA-Omniscience benchmark.
Yeah I get that the actual parameter count isn’t, but I think the general argument that bigger pre trains remember more facts, and we can use that to try predict the model size.
Is there a reliable way to distinguish between [remembers more facts] and [infers more correct facts from remembered ones]? If there isn't, then using remembered facts as an estimate of base model size would be even more noisy than you'd already expect.
I know I get far more questions right on exams than chance would predict when I have 0 direct knowledge/memory of the correct answer. I assume reasoning models have at least some of this kind of capability
This is the editorial for this year’s "Shallow Review of AI Safety". (It got long enough to stand alone.)
Epistemic status: subjective impressions plus one new graph plus 300 links.
Huge thanks to Jaeho Lee, Jaime Sevilla, and Lexin Zhou for running lots of tests pro bono and so greatly improving the main analysis.
tl;dr
Capabilities in 2025
Better, but how much?
-- Fraser, riffing off Pueyo
Arguments against 2025 capabilities growth being above-trend
Arguments for 2025 capabilities growth being above-trend
We now have measures which are a bit more like AGI metrics than dumb single-task static benchmarks are. What do they say?
So: is the rate of change in 2025 (shaded) holding up compared to past jumps?:
Ignoring the (nonrobust)[6] ECI GPT-2 rate, we can say yes: 2025 is fast, as fast as ever, or more.
Even though these are the best we have, we can’t defer to these numbers.[7] What else is there?
One way of reconciling this mixed evidence is if things are going narrow, going dark, or going over our head. That is, if the real capabilities race narrowed to automated AI R&D specifically, most users and evaluators wouldn’t notice (especially if there are unreleased internal models or unreleased modes of released models). You’d see improved coding and not much else.
Or, another way: maybe 2025 was the year of increased jaggedness (i.e. variance) or of trading off some capabilities against others (i.e. there would exist regressions). Maybe the RL made them much better at maths and instruction-following, but also sneaky, narrow, less secure (in the sense of emotional insecurity).
(You were about to nod sagely and let me get away without checking, but the ADeLe work also lets us just see if the jaggedness is changing.)
abilities
fell compared to
predecessor
– Roger Grosse
Evals crawling towards ecological validity
(Nano Banana 3-shot in reference to this tweet.)
Safety in 2025
Are reasoning models safer than the old kind?
Well, o3 and Sonnet 3.7 were pretty rough, lying and cheating at greatly increased rates. Looking instead at GPT-5 and Opus 4.5:
But then
How much can we trust the above, given they can somewhat sabotage evals now?
So: lower propensity, higher risk when they go off - and all of this known with lower confidence?
The looming end of evals
Our evaluations are under pressure from cheating, sandbagging, background safety, under-elicitation, and deception. We don’t really know how much pressure. This is on top of evals usually being weak proxies, contaminated, label-noised, unrealistic, and confounded in various ways.
Prosaic misalignment
Still, we see misalignment when we look for it, so the lying is not that strong. (It is lucky that we do see it, since it could have been that scheming only appeared at later, catastrophic capability levels.)
Fully speculative note: Opus 4.5 is the most reliable model and also relatively aligned. So might it be that we’re getting the long-awaited negative alignment taxes?
What is the plan?
The world’s de facto alignment strategy remains “iterative alignment”, optimising mere outputs with a stack of admittedly weak alignment and control techniques. Anthropic have at least owned up to this being part of their plan.
Some presumably better plans:
Things which might fundamentally change the nature of LLMs
Emergent misalignment and model personas
Monitorability
(blingdivinity)
New people
Overall
Discourse in 2025
Also an explicit admission that self-improvement is the thing to race towards:
Gemini 3 is supposedly a big pretraining run, but we have even less actual evidence here than for the others because we can’t track GPUs for it.
Epoch's estimate for the Grok 3/4 training run as a whole was 5e26, but this includes potentially huge amounts of RL post-training (apocryphally, 50%) for Grok 4.
See Pokemon for a possible counterexample.
The weak argument runs as follows: Epoch speculate that Grok 4 was 5e26 FLOPs overall. An unscientific xAI marketing graph implied that half of this was spent on RL: 2.5e26. And Mechanize named 6e26 as an example of an RL budget which might cause notable generalisation.
(Realistically it wasn't half RL.)
“We imagine the others to be 3–9 months behind OpenBrain”
Lexin is a rigorous soul and notes that aggregating the 18 abilities is not strictly possible. I've done something which makes some sense here, weighting by each ability's feature importance.
Two runs gave [48, 85] where other runs vary by less than 4 points. Thanks Epoch!
Also o1 looks kind of unremarkable here, which is not how it felt at the time. I think it's because it was held up a long time and this messes with the progress rates, which use public release date. (Remember the training cutoff for o1-preview was October 2023!)
Also the ADeLE o1 result is with "low" reasoning effort.
One reason not to defer is that these measures are under intense adversarial pressure. (ADeLe isn’t goodharted yet but only because no one knows about it.)
See e.g. ERNIE-...A47B, where “A” means “active”.
i.e. “biological weapons; child safety; deadly weapons; platform manipulation and influence operations; suicide and self-harm; romance scams; tracking and surveillance; and violent extremism and radicalization.”
“steering against… eval-awareness representations typically decreased verbalized eval awareness, and sometimes increased rates of misalignment... [Unaware-steered Sonnet 4.5] still exhibited harmful behaviors at lower rates than Opus 4.1 and Sonnet 4.”