I find this an interesting line of criticism, it is essentially pointing at the difficulty of finding good evidence and evaluating yourself on that evidence and making a disagreement about how easy it is.
I would like to bring in a perspective of more first principles modelling of how quickly you incorporate evidence pointing against the way you're thinking.
One thing is the amount of disconfirming evidence you look for. Another thing is your ability to bring that information into your worldview, your openness to being wrong. Thirdly we might also mention is the speed of the feedback, how long time does it take for you to get feedback.
I think you're saying that when you go into virtue ethics we often find failures in bringing in disconcerting information into a worldview. I don't think this has to be the case personally as I do think there are ways to actually get feedback on whether you're acting in a way that is aligned with your virtues, by mentioning examples of them and then having anonymous people give feedback or just normal reflection.
This is a lot easier to do if your loops are shorter which is the exact point that consequentalism and utilitarianism can fail on, it is a target that is quite far away and so the crispness and locality of the feedback is not high enough.
I think that virtue ethics outperforms consequentialism because it is better suited for bringing in information as well as for speed and crispness of that information. I personally think it is because it is a game theory optimal solution to consequentialism in environments where you have little information but that is probably beside the point.
This might just be a difference in terminology though? Would you agree with my 3 point characterisation above?
Perhaps a multi-agent alignment research direction could be to create networks with higher cognitive complexity, with the goal of limiting the persuasion effect of any single agent? This is probably more compelling if you have a high probability of models being mostly aligned, and are misaligned in mostly distinct ways.
Yes! Very good! You spotted it too, a lot of the research I've been doing into this space is about how to build institutional structures that are resillient to capture of resources and behaviour. I've been working on setting up environments for a sort of misinformation evaluation of different types of institutions and social networks.
I'm basically in the camp of LLMs being semi-aligned and the effects being determined by higher order emergent coalitions of LLMs and so I think it is good to provide good alternatives for these collectives instead of allowing whatever to arise.
Economists model markets with one formalism. Network scientists study information diffusion with another. Political scientists analyze voting with a third.
Do you have any thoughts as to why this is the case? I buy the claim that these are all related, but wonder if there are strengths posed by any of these methods that the spectral signals approach fails to satisfy. I suppose this falls into your "proving spectral-behavioral correspondences" direction, so I'm excited for more updates on this topic.
The original version of this was called "A Langlands Program for Collective Intelligence" and was a lot more focused on finding the shared representation of these systems to better elucidate the actual differences. My speculation right now is that these things are within the "symmetries" and general axioms you assume about the model.
Where do these symmetries come from? I think it to some extent boils down to what type of agent you're researching, is it a strategic agent? Is it a simple agent that just learns from its neighbours? Is it an economically rational agent?
Then the follow up question becomes, what are the attributes of such an agent? I've done an initial taxonomy here and some of the things are also alluded to in my post on a Phylogeny of Agents yet it's all work in progress.
I agree with you but I think you might be missing the point, let me add some detail from the cultural evolution angle. (because I do think the paper is actually implicitly saying something interesting about mean-field and similar approaches.)
One of the main points from Henrich's WEIRDest People in the World is between internalized identity and relational identity. WEIRD populations develop internal guilt, stable principles, context-independent rules—your identity lives inside you. Non-WEIRD populations have identities that exist primarily in relation to specific others: your tribe, your lineage, your patron. Who you are depends on who you're interacting with.
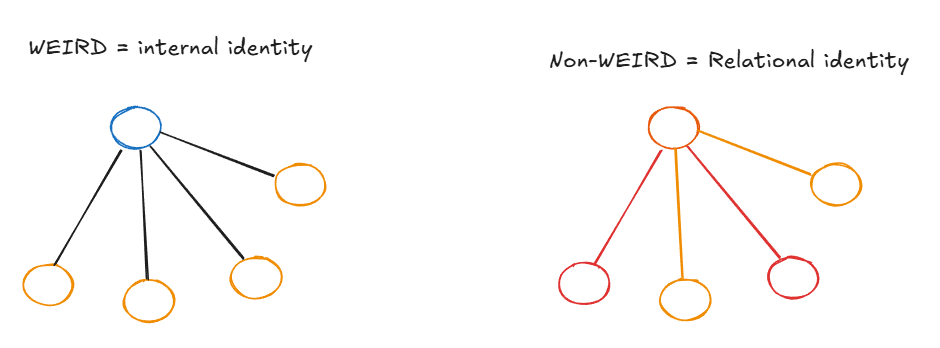
Now connect this to the effective horizon result. Consider the king example: if you send tribute to a specific king, whether that's a good action depends enormously on that king's specific future response—does he ally with you, ignore you, betray you? You can't replace "the king's actual behavior" with "average behavior of a random agent" and preserve the action ranking. The random policy Q-function washes out exactly the thing that matters. The mean field approximation fails because specific node identities carry irreducible information.
Now consider a market transaction instead. You're trading with someone, and everyone else in the economy is also just trading according to market prices. It basically doesn't matter who's on the other side—the price is the price. You can replace your counterparty with a random agent and lose almost nothing. The mean field approximation holds, so the random policy Q-function preserves action rankings, and learning from simple exploration works.
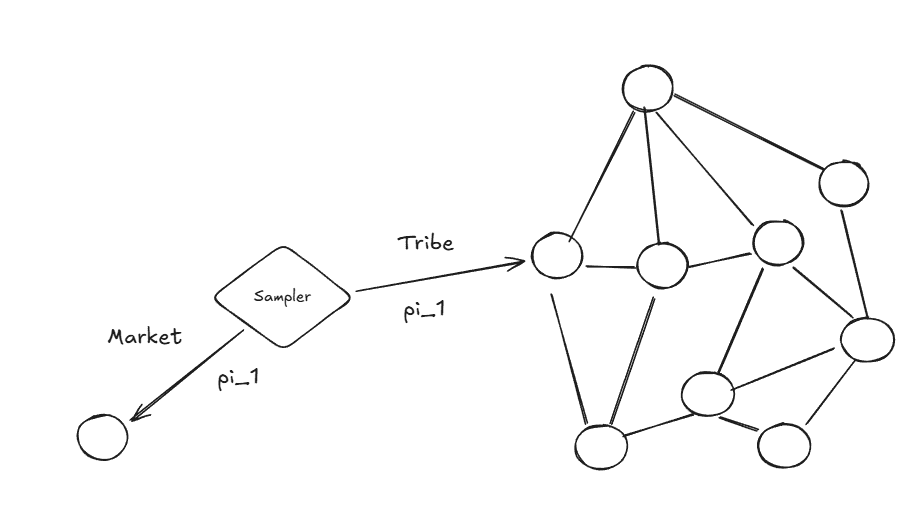
So essentially: markets are institutions that make the mean field approximation valid for economic coordination, which is exactly the condition under which the random policy equals the optimal policy for greedy action selection. They're environment engineering that makes learning tractable.
This paper is really cool!
A random fun thing that I connected it to is how civilization can be seen as an engineering process that enables lower context horizon planning. The impersonality of a market is essentially a standardising force that allows you to not have to deal with long chains of interpersonal connections which enables you to model the optimal policy as close to a random policy for the average person will behave in a standardised way (to work for a profit).
This might connect to Henrich's stuff on market integration producing more impersonal/rule-based cognition. Maybe populations adapt to environments where random-policy-Q-functions are informative, and we call that adaptation "WEIRD psychology"?
Something something normalization and standardization as horizon-reduction...
What comes to mind is Schrödinger's "What is Life?" (1944)—hugely influential for molecular biology, but Max Perutz wrote that "what was true in his book was not original, and most of what was original was known not to be true." Pauling called his thermodynamics "vague and superficial." (detailed review)
I think this could have been perceived and done better if Schrödinger spent some more time engaging with the axiomatic setup of biology.
Econophysics shows a similar pattern—physicists applying statistical mechanics to markets, largely ignored by economists who see them as missing institutional details. (Science coverage)
I asked Claude for further examples:
- Sociobiology wars (1970s-80s): Wilson had water poured on him at a conference; accused of scientific racism by Harvard colleagues
- Physicists entering neuroscience/consciousness research more broadly: pattern of proposing mechanisms without engaging with existing empirical constraints
I would see it more as casual learning with the do operator and so it isn't necessarily about fitting to a MSE but rather doing testing of different combinations?
Something something gears level models
To summarise it, grow your honesty and ability to express your own wants instead of becoming more paranoid about whether you're being manipulated because it will probably be too late to do anyway?
That does make sense and seems like a good strategy.
I think your points are completely valid, I funnily enough found myself doing a bunch of reasoning around something like "that's cool and all but I would know if I'm cognitively impaired when it comes to this", like llms aren't strong enough yet and similar but that's also something someone who gets pwned would say.
So basically it is a skill issue but it is a really hard skill and on priors most people don't have it. And for myself i shall now beware any long term planning based on emotional responses from myself about LLMs because I definetely have over 1000 hours with LLMs.
This was quite fun to read and to take part of how it feels like to do 4d chess thinking in a way that I do not believe I'm capable of myself but I wanted to give a reflection anyway. (I do not think of my own epistemology in this sort of recursive way and so it is a bit hard to relate/understand fully but still very interesting.)
This is not about ideology. I have met many people who tell me "I would in fact change my job based on evidence."
I guess I'm resonating more with Davidad here and so this is basically a longer question to Gabriel.
I would want to give a comment on this entire part where you're talking about different levels of epistemic defense and what counts as evidence. If you imagine the world as a large multi-armed bandit (spherical cows and all that), it seems to me that this is to some extent a bet on an explore exploit strategy combined with a mindset about how likely you're to get exploited in general. So the level of epistemic rigour to hold itself seems to be a parameter that should be dependent on what you observe with different degrees of rigour? You still need the ultimate evaluator to have good rigour and the ultimate evaluator is tied to the rest of your psyche so you shouldn't go off the rails with it to retain a core of rationality yet it seems like bounded exploration is still good here?
Davidad said something about OOD (Out of distribution) generalisation holding surprising well for different fields and I think the applies here as well, deciding on your epistemic barriers imply having answered a question of how much extra juice your models get due to cross-polination. If you believe in OOD generalisation and a philosophy of science that is dependent on how you ask the question then holding multiple models seem better since it seems hard to ask new questions from singular positions?
Asking the same question in multiple ways also make it easier for you to abandon a specific viewpoint which is one of the main things people get stuck in epistemically (imo). I'm getting increasingly convinced that holding experience with a lightness and levity is one of the best ways to become more rational as it is what makes it easier to let go of the wrong models.
So if I don't take myself in general too seriously by holding most of my models lightly and I then have OODA loops where I recursively reflect on whether I'm becoming the person who I want to be and have set out to be in the past, is that not better than having high guards?
From this perspective I then look at the question of your goodness models as the following:
One of my (different lightly held) models agree with Davidad in that LLMs seem to have understood good better than thought before. My hypothesis here is that there's something about language representing the evolution of humanity and coordination happening through language which leads to language being a good descriptor of tribal dynamics which is where our morality has had to come from.
Now, one can hold the RL and deception view as well, which I also agree with. It states that you will get deceived by AI systems and so you can't trust them.
I'm of the belief that one can hold multiple seemingly contradictory views at the same time without having to converge and that this is good rationality. (caveats and more caveats but this being a core part of it)
As a meta point for the end of the discussion, it also seems to me that the ability to make society hold seemingly contradictory thoughts in open ways is one of the main things that 6pack.care and the collective intelligence field generally is trying to bring about. Maybe the answer that you converged on is that the question does not lie within the bound of the LLM but rather the effect it has on collective epistemics and that the ultimate evaluator function is how it affects the real world, specifically in governance?
Fun conversation though so thank you for taking the time and having it!
That is a fair point, since virtue is tied to your identity and self it is a lot easier to take things personally and therefore distort the truth.
A part of me is like "meh, skill issue, just get good at emotional intelligence and see through your self" but that is probably not a very valid solution at scale if I'm being honest.
There's still something nice about it leading to repeated games and similar, something about how if you look at our past then cooperation arises from repeated games rather than individual games where you analyse things in detail. This is the specific point that Joshua Greene makes in his Moral Tribes book for example.
Maybe the core point here is not virtue versus utilitarian reasoning, it might more be about the ease of self-deception and how different time limits and how ways of evaluating your own outcomes and outputs should be done in a more impersonal way. Maybe one shouldn't call this virtue ethics as it carries a large bag and camp, maybe heruistics ethics or something (though that feels stupid).