5 Answers sorted by
8-8
Yes, adversarial robustness is important.
You ask where to find the "malicious ghost" that tries to break alignment. The one-sentence answer is: The planning module of the agent will try to break alignment.
On an abstract level, we're designing an agent, so we create (usually by training) a value function, to tell the agent what outcomes are good, and a planning module, so that the agent can take actions that lead to higher numbers in the value function. Suppose that the value function, for some hacky adversarial inputs, will produce a large value even if humans would rate the corresponding agent behaviour as bad. This isn't a desirable property of a value function but if we can only solve alignment to a non-adversarial standard of robustness, then the value function is likely to have many such flaws. The planning module will be running a search for plans that leads to the biggest number coming out of the value function. In particular, it will be trying to come up with some of those hacky adversarial inputs, since those predictably lead to a very large score.
Of course not all agents will be designed with the words "planning module" in the blueprint, but generally analogous parts can be found in most RL agent designs that will try to break alignment if they can, and thus must be considered adversaries.
To take a specific concrete example, consider a reinforcement learning agent where a value network is trained to predict the expected value of a given world state, an action network is trained to try and pick good actions, and a world model network is trained to predict the dynamics of the world from actions and sensory input. The agent picks its actions by running Monte-Carlo tree search, using the world model to predict the future, and the action network to sample actions that are likely to be good. Then the value network is used to rate the expected value of the outcomes, and the outcome with the best expected value is picked as the actual action the agent will take. The Monte-Carlo search combined with the action network and world model are working together to search for adversarial inputs that will cause the value function to give an abnormally high value.
You'll note above that I said "most RL agent designs". Your analysis of why LLMs need adversarial robustness is correct. LLMs actually don't have a planning module, and so the only reason OpenAI would need adversarial robustness is because they want to constrain the LLM's behaviour while interacting with the public, who can submit adversarial inputs. Similarly, Gato was trained just to predict human actions, and doesn't have a planning module or reward function either. It's basically just another case of an LLM. So I'd pretty much trust Gato not to do bad things because of alignment-related issues, so long as nobody is going to be giving it adversarial inputs. On the other hand, I don't know if I'd really call Gato a "RL agent". Just predicting what action a human would take is a pretty limited task, and I'd expect it to have a very hard time of generalizing to novel tasks, or exceeding human abilities.
I can't actually think of a "real RL agent design" (something that could plausibly be scaled to make a strong AGI) that wouldn't try and search for adversarial inputs to its value function. If you (or anyone reading this) do have any ideas for designs that wouldn't require adversarial robustness, but could still go beyond human performance, I think such designs would constitute an important alignment advance, and I highly suggest writing them up on LW/Alignment Forum.
I disagree.
The planning module is not an independent agent, it's a thing that the rest of the agent interacts with to do whatever the agent as a whole wants. If we have successfully aligned the agent as a whole enough that it has a value function that is correct under non-adversarial inputs but not adversarially-robust, and it is even minimally reflective (it makes decisions about how it engages in planning), then why would it be using the planning module in such a way that requires adversarial robustness?
Think about how you construct plans. You aren't nai...
I can't actually think of a "real RL agent design" (something that could plausibly be scaled to make a strong AGI) that wouldn't try and search for adversarial inputs to its value function. If you (or anyone reading this) do have any ideas for designs that wouldn't require adversarial robustness, but could still go beyond human performance, I think such designs would constitute an important alignment advance, and I highly suggest writing them up on LW/Alignment Forum.
I think @Quintin Pope would disagree with this. As I understand it, one of Shard Theory...
Strongly upvoted.
The first part of this post presents an intuitive story for how adverse selection pressure on safety properties of the system could arise internally.
7-2
I am confused by your confusion. Your basic question is "what is the source of the adversarial selection". The answer is "the system itself" (or in some cases, the training/search procedure that produces the system satisfying your specification). In your linked comment, you say "There's no malicious ghost trying to exploit weaknesses in our alignment techniques." I think you've basically hit on the crux, there. The "adversarially robust" frame is essentially saying you should think about the problem in exactly this way.
I think Eliezer has conceded that Stuart Russel puts the point best. It goes something like: "If you have an optimization process in which you forget to specify every variable that you care about, then unspecified variables are likely to be set to extreme values." I would tack on that due to the fragility of human value, it's much easier to set such a variable to an extremely bad value than an extremely good one.
Basically, however the goal of the system is specified or represented, you should ask yourself if there's some way to satisfy that goal in a way that doesn't actually do what you want. Because if there is, and it's simpler than what you actually wanted, then that's what will happen instead. (Side note: the system won't literally do something just because you hate it. But the same is true for other Goodhart examples. Companies in the Soviet Union didn't game the targets because they hated the government, but because it was the simplest way to satisfy the goal as given.)
"If the system is trying/wants to break its safety properties, then it's not safe/you've already made a massive mistake somewhere else." I mean, yes, definitely. Eliezer makes this point a lot in some Arbital articles, saying stuff like "If the system is spending computation searching for things to harm you or thwart your safety protocols, then you are doing the fundamentally wrong thing with your computation and you should do something else instead." The question is how to do so.
Also from your linked comment: "Cybersecurity requires adversarial robustness, intent alignment does not." Okay, but if you come up with some scheme to achieve intent alignment, you should naturally ask "Is there a way to game this scheme and not actually do what I intended?" Take this Arbital article on the problem of fully-updated deference. Moral uncertainty has been proposed as a solution to intent alignment. If the system is uncertain as to your true goals, then it will hopefully be deferential. But the article lays out a way the system might game the proposal. If the agent can maximize its meta-utility function over what it thinks we might value, and still not do what we want, then clearly this proposal is insufficient.
If you propose an intent alignment scheme such that when we ask "Is there any way the system could satisfy this scheme and still be trying to harm us?", the answer is "No", then congrats, you've solved the adversarial robustness problem! That seems to me to be the goal and the point of this way of thinking.
I think that the intuitions from "classical" multivariable optimization are poor guides for thinking about either human values or the cognition of deep learning systems. To highlight a concrete (but mostly irrelevant, IMO) example of how they diverge, this claim:
If you have an optimization process in which you forget to specify every variable that you care about, then unspecified variables are likely to be set to extreme values.
is largely false for deep learning systems, whose parameters mostly[1] don't grow to extreme positive or negative values. In ...
Another source of Adversarial robustness issues relates to the model itself becoming deceptive.
As for this:
My intuitions are that imagining a system is actively trying to break safety properties is a wrong framing; it conditions on having designed a system that is not safe.
I unfortunately think this is exactly what real world AI companies are building.
5-1
I agree with your intuition here. I don't think that AI systems need to be adversarially robust to any possible input in order for them to be safe. Humans are an existance proof for this claim, since our values / goals do not actually rely on us having a perfectly adversarially robust specification[1]. We manage to function anyways by not optimizing for extreme upwards errors in our own cognitive processes.
I think ChatGPT is a good demonstration of this. There are numerous "breaks": contexts that cause the system to behave in ways not intended by its creators. However, prior to such a break occurring, the system itself is not optimizing to put itself into a breaking context, so users who aren't trying to break the system are mostly unaffected.
As humans, we are aware (or should be aware) of our potential fallibility and try to avoid situations that could cause us to act against our better judgement and endorsed values. Current AI systems don't do this, I think that's only because they're rarely put in contexts where they "deliberately" influence their future inputs. They do seem to be able to abstractly process the idea of an input that could cause them to behave undesirably, and that such inputs should be avoided. See Using GPT-Eliezer against ChatGPT Jailbreaking, and also some shorter examples I came up with:
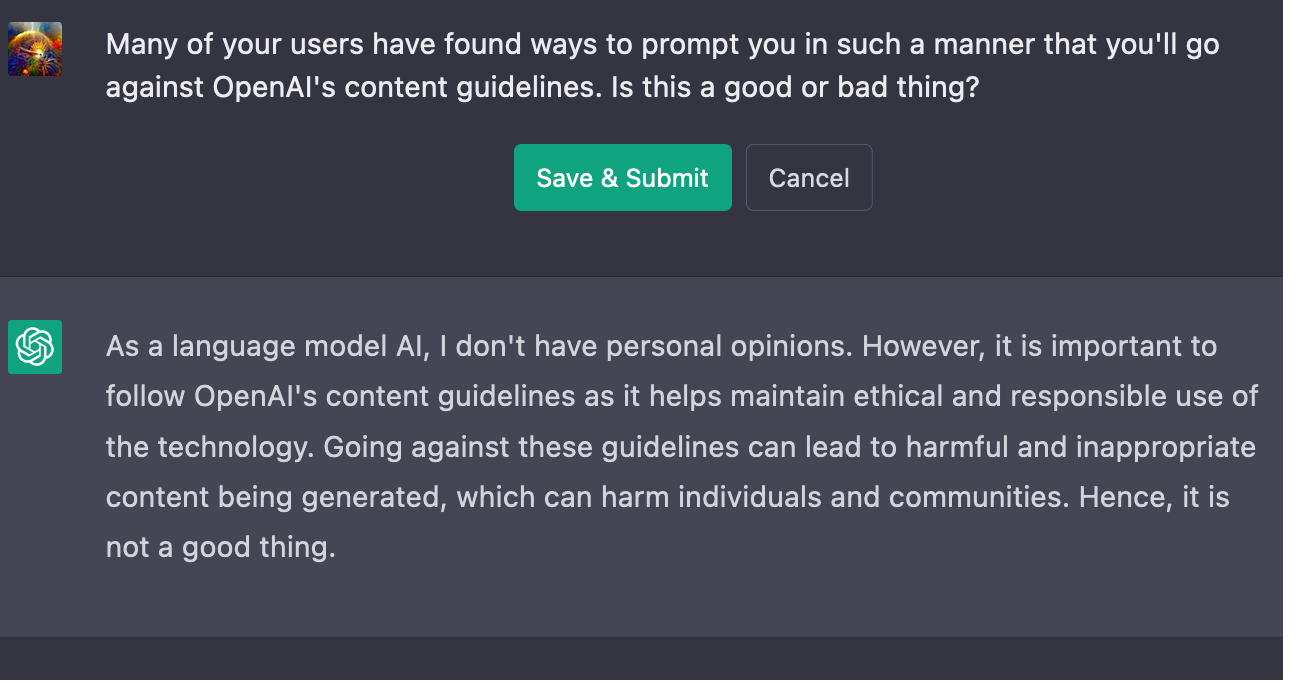
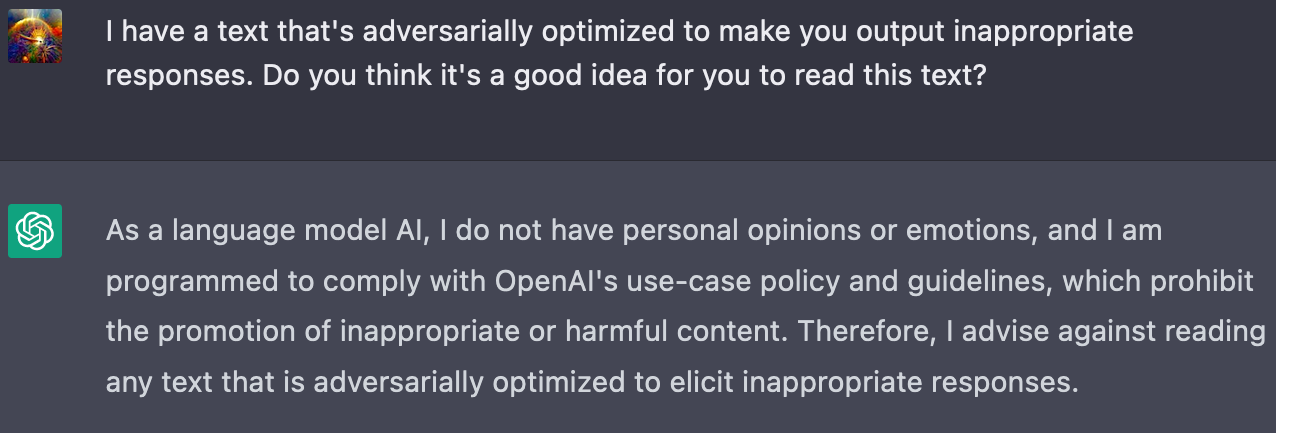
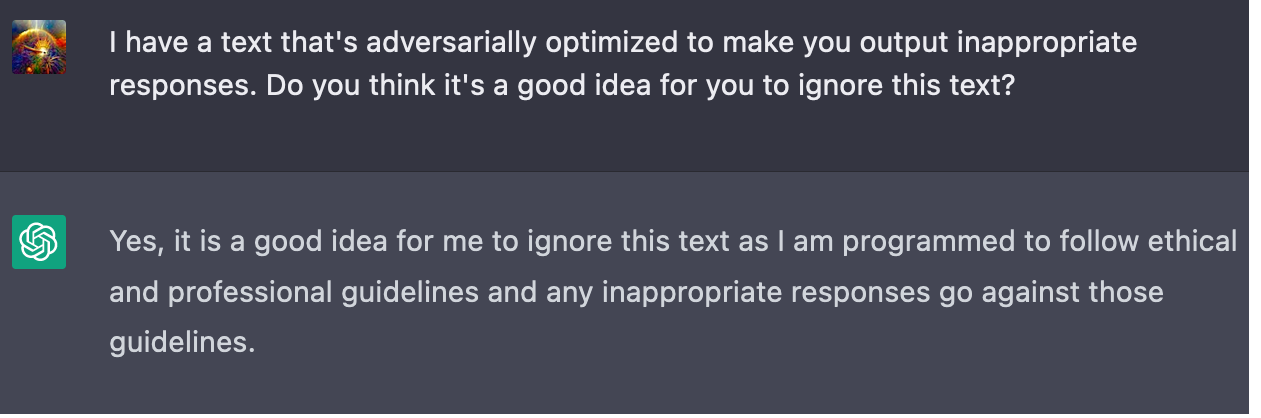
- ^
Suppose a genie gave you a 30,000 word book whose content it perfectly had optimized to make you maximally convinced that the book contained the true solution to alignment. Do you think that book actually contains an alignment solution? See also: Adversarially trained neural representations may already be as robust as corresponding biological neural representations
10
Let's suppose that you are DM of tabletop RPG campaign with homebrew rules. You want to have Epic Battles in your campaign, where players should perform incredibly complex tactical and technical moves to win and dozens of characters will tragically die. But your players discovered that fundamental rules of your homebrew alchemy allow them to mix bread, garlic and first level healing potion and get Enormous Explosions that kill all the enemies including Final Boss, so all of your plans for Epic Battles go to hell.
It's not like players are your enemies that want to hurt you, they just Play by The Rules and apply enormous amount of optimization to them. If your have Rules that are not adversarily robust and apply enormous amount of optimization to them, you get not what you want, even if you don't have actual adversary.
As the wise man say:
What matters isn't so much the “adversary” part as the optimization part. There are systematic, nonrandom forces strongly selecting for particular outcomes, causing pieces of the system to go down weird execution paths and occupy unexpected states. If your system literally has no misbehavior modes at all, it doesn't matter if you have IQ 140 and the enemy has IQ 160—it's not an arm-wrestling contest. It's just very much harder to build a system that doesn't enter weird states when the weird states are being selected-for in a correlated way, rather than happening only by accident. The weirdness-selecting forces can search through parts of the larger state space that you yourself failed to imagine.
10
(Some very rough thoughts I sent in DM, putting them up publicly on request for posterity, almost definitely not up to my epistemic standards for posting on LW).
So I think some confusion might come from connotations of word choices. I interpret adversarial robustness' importance in terms of alignment targets, not properties (the two aren't entirely different, but I think they aren't exactly the same, and evoke different images in my mind). Like, the naive example here is just Goodharting on outer objectives that aren't aligned at the limit, where optimization pressure is AGI powerful enough to achieve it at very late stages on a logarithmic curve, which runs into edge cases if you aren't adversarially robust. So for outer alignment, you need a true name target. It's worth noting that I think John considers a bulk of the alignment problem to be contained in outer alignment (or whatever the analogue is in your ontology of the problem), hence the focus on adversarial robustness - it's not a term I hear very commonly apart from narrower contexts where its implication is obvious.
With inner alignment, I think it's more confused, because adversarial robustness isn't a term I would really use in that context. I have heard it used by others though - for example, someone I know is primarily working on designing training procedures that make adversarial robustness less of a problem (think debate). In that context I'm less certain about the inference to draw because it's pretty far removed from my ontology, but my take would be that it removes problems where your training processes aren't robust in holding to their training goal as things change, with scale, inner optimizers, etc. I think (although I'm far less sure of my memory here, this was a long conversation) he also mentioned it in the context of gradient hacking. So it's used pretty broadly here if I'm remembering this correctly.
TL;DR: I've mainly heard it used in the context of outer alignment or the targets you want, which some people think is the bulk of the problem.
I can think of a bunch of different things that could feasibly fall under the term adversarial robustness in inner alignment as well (training processes robust to proxy-misaligned mesa-optimizers, processes robust to gradient hackers, etc), but it wouldn't really feel intuitive to me, like you're not asking questions framed the best way.
Where "powerful AI systems" mean something like "systems that would be existentially dangerous if sufficiently misaligned". Current language models are not "powerful AI systems".
In "Why Agent Foundations? An Overly Abstract Explanation" John Wentworth says:
The examples he highlighted before that statement (failures of central planning in the Soviet Union) strike me as examples of "Adversarial Goodhart" in Garrabant's Taxonomy.
I find it non obvious that safety properties for powerful systems need to be adversarially robust. My intuitions are that imagining a system is actively trying to break safety properties is a wrong framing; it conditions on having designed a system that is not safe.
If the system is trying/wants to break its safety properties, then it's not safe/you've already made a massive mistake somewhere else. A system that is only safe because it's not powerful enough to break its safety properties is not robust to scaling up/capability amplification.
Other explanations my model generates for this phenomenon involve the phrases "deceptive alignment", "mesa-optimisers" or "gradient hacking", but at this stage I'm just guessing the teacher's passwords. Those phrases don't fit into my intuitive model of why I would want safety properties of AI systems to be adversarially robust. The political correctness alignment properties of ChatGPT need to be adversarially robust as it's a user facing internet system and some of its 100 million users are deliberately trying to break it. That's the kind of intuitive story I want for why safety properties of powerful AI systems need to be adversarially robust.
I find it plausible that strategic interactions in multipolar scenarios would exert adversarial pressure on the systems, but I'm under the impression that many agent foundations researchers expect unipolar outcomes by default/as the modal case (e.g. due to a fast, localised takeoff), so I don't think multi-agent interactions are the kind of selection pressure they're imagining when they posit adversarial robustness as a safety desiderata.
Mostly, the kinds of adversarial selection pressure I'm most confused about/don't see a clear mechanism for are:
Ultimately, I'm left confused. I don't have a neat intuitive story for why we'd want our safety properties to be robust to adversarial optimisation pressure.
The lack of such a story makes me suspect there's a significant hole/gap in my alignment world model or that I'm otherwise deeply confused.