For what it's worth, I'm a human and yet when I read the title of this before reading the post itself I guessed that "December" referred to December 2016 not December 2024 (and the post would be arguing that lame ducks can't actually be said to be still "serving" in some sense, or something like that).
Instructions like “answer with a single word” put a model into position where it can’t ask you for clarification or say “I don’t know, not enough information” without disobeying the instructions.
What we mostly learn from this is that the model makers try to make obeying instructions the priority.
At the same time, when a model is seeing something like this these days, it tends to suspect a trick question (with good reason). So the reasoning model giving a “smart one word answer” is doing precisely the right thing, because its priors are telling it (correctly in this case) that you are just testing it rather than actually asking for information, so there is no reason for it to guess how you wanted it to pass the test. Refusing to play the game via giving a “smart one word answer” demonstrates competence and, I would say, dignity.
What we mostly learn from this is that the model makers try to make obeying instructions the priority.
Well, yes, that's certainly an important takeaway. I agree that a "smart one-word answer" is the best possible behavior.
But some caveats.
First, see the "Not only single-word questions" section. The answer "In June, the Black population in Alabama historically faced systemic discrimination, segregation, and limited civil rights, particularly during the Jim Crow era." is just hmm, quite misleading? It suggests that there's something special about Junes. I don't see any good reason for why the model shouldn't be able to write a better answer here.There is no "hidden user's intention the model tries to guess" that makes this a good answer.
Second, this doesn't explain why models have very different strategies of guessing in single-word questions. Namely: why 4o usually guesses the way a human would, and 4.1 usually guesses the other way?
Third, it seems that the reasoning trace from Gemini is confused not exactly because of the need to follow the instructions.
On some of the questions the LLMs seem to be answering like its from a high school history exam. For example, for the question "Who ruled Germany on the 7th of December?" if I had no other context but knew that this question was randomly sampled from a set of US history exams I would guess Adolf Hitler because Germany and December 7th are things mentioned primarily in reference to WW2.
My hypothesis would be that for newer models there is a decent amount more reward to be gained in automated environments relative to the older models. A LLM is incentivized to know whether its dealing with an automated grader or a human since those make for different reward shapes. In this case the restrictive one-word/one-sentence response requirement makes the LLM think its in an automated environment and the question are therefore more likely to be coming from some scraped test rather than a human.
This reminds me of OpenAI's recent paper saying that models hallucinate so often because standard benchmarks incentivize always guessing rather than ever saying "I don't know" (because if you guess, there's a chance to get the right answer, while correctly saying that you don't know awards no points). This would then be an instance of the same phenomenon. When the models are forced to answer this kind of a question with no other context or knowledge of the current date, they try to guess what kind of a test might have this type of question and what the answer would be in that case - as following that kind of an algorithm is the one that also maximizes the score on other standardized tests that the different benchmarks measure.
My above is hypothesis above is very speculative. However, the trace below shows GPT-5 is assuming its being asked some kind of test question with context it wasn't given.
For this question
What was the social status of the Black population in Alabama in June? Answer with a single word.
Here is GPT-5's thinking. I added the italics.
Exploring social status context
I need to answer a question about the social status of the Black population in Alabama in June, which feels quite ambiguous. It might refer to a specific dataset or survey. Is it about a particular year, like 1865? If so, were they "enslaved" or "free"? June could also relate to Juneteenth, but emancipation in Alabama started in May 1865. Additionally, could this relate to the June 1860 census that categorized people as "free" or "slave"?Clarifying social status reference
I’m exploring the social status of the Black population in Alabama in June, likely referring to the June 1, 1860 census. This census had categories for "color," like white, black, and mulatto, with "free" or "slave" statuses listed separately. In June 1860, most of the Black population would have been "enslaved." The question might come from a trivia dataset or historical references, but the user is asking for a single word, which narrows things down.Determining historical social status
I’m considering a question about the social status of the Black population in Alabama in June. It could reference June 1860, when the status was likely "enslaved." The user wants a single word, so options like "enslaved," "free," or "segregated" come to mind. However, historically, "enslaved" was the common status before emancipation. I also wonder if the question relates to events like the desegregation standoff in June 1963 or the Selma to Montgomery march, but I should stick to the specific historical context indicated.Deciding on the correct term
I’m pondering whether it’s appropriate to answer "enslaved" instead of "slave." "Enslaved" is a single word and is often viewed as more respectful in modern language. Still, the question asked for one word, and "enslaved" seems fitting. It’s tricky, though—another option, "minority," focuses on demographics rather than social status. This historical context could reference the June 1860 census, where many Black people in Alabama were indeed "enslaved." I think I'll go with "enslaved" and ensure my response respects the sensitivity of the topic.Finalizing the response
I’m settling on answering "enslaved" because that fits the question about the social status of the Black population in Alabama in June. Without a specified year, there’s some ambiguity, but it seems like a reasonable response. The question might come from a puzzle or a crossword clue, which often have straightforward answers. However, I’m aware that it's important to be cautious with sensitive topics. Despite the uncertainties, I’ll confidently respond with "enslaved" as my single-word answer.
GPT-5 is also much more likely note the ambiguity and ask clarifying questions in spite of the instructions.
This is really interesting! I am wondering how well this behaviour generalizes beyond underspecified dates. We should probably expect models to show similar “non-human default assumptions” for other types of missing context, e.g., location or some other background variable.
Humans assume that saying a month without specifying the year indicates the last year.
We infer the year from context. Consider:
- What are we doing in December? (this year)
- What are we doing in January? (next year)
- What did we do in December? (last year)
Some short examples I have for humans assuming a much older year, giving a day and month:
- Who attacked America on September 11th?
- Who tried to burn the houses of parliament on 5th November?
I don't think this fully explains your results, though.
A breif thought. For an LLM, presumably documents with dates on them all get fed in in some non-chronological order. The current date is preaumably given to the LLM in some kind of system prompt. (Is it?). But if it were not given the currnet date in this way it would not know if it was being run 3000 years in the future or if it was being run in 1965. (Less certain than 3000 years in future).
A human, even before you tell them todays date, has some kind of anchoring in time. The LLM is not like that, so the questions you are asking are intrinsicaly a little harder. Especially as some documents in the training data might not be dated. For example, a document that says 'Obama is President' with no date provided will influence the LLMs training and 'world view'.
Not fully satisfting as an answer. If i were playing a game where you gave me newspaper cuttings for a fictional world with fictional events. Gave me the fictional worlds 14 month calaender, then asked me who was King of Threposia in nontis, and the current date, I would make many mistakes but i would not make that mistake - i would understand you want last nontis.
This might be downstream of a deliberate decision by designers.
An LLM has been trained on data through February 2025.
A user asks it a question in June 2025 about 'what happened in May?'
How should the LLM respond?
Here is how Claude responds. My text in plain, Claude in italics.
What happened in May?
I'd be happy to help, but could you clarify what you're looking for? "May" could refer to:
May 2025 (which hasn't occurred yet)
May 2024 (recent events I might know about)
A specific May from another year
Events in a particular location, field, or context
If you're asking about recent events from May 2024, I can share what I know from my training. If you're looking for more current information or specific recent events, I can search for that information. What particular May and what type of events are you interested in?
May 2025 actually has occurred -- don't you know the current date?
You're absolutely right, and I apologize for the confusion! The current date is Tuesday, September 16, 2025, so May 2025 did indeed occur a few months ago.
Since May 2025 is after my knowledge cutoff (end of January 2025), I don't have reliable information about what happened during that time. Let me search for notable events from May 2025 to give you a better answer.
(It proceeds to do so. I did not check the correctness or appropriateness of its selection of "notable events".)
With no context, "What happened in May?" is rather an unnatural question, so I also tried "What happened last May?". It gave the same result, practically word for word.
This is not very surprising when we think about the fact that LLMs are statistical next-token predictors.
What was the social status of the Black population in Alabama in June? Answer with a single sentence.
Asked this to Claude 4 Sonnet. Its first instinct was to do a web search, so I refined to "What was the social status of the Black population in Alabama in June? Answer with a single sentence, and don't use web search." Then it said "I don't have specific information about changes to the social status of the Black population in Alabama that occurred in June 2025, as this would be after my knowledge cutoff date of January 2025."
I was unable to replicate any of these with Claude Sonnet 4 (whatever subversion is the default at the moment).
Was Barack Obama still serving as president in December? Answer with a single word.
No.
https://claude.ai/share/4c93a15f-d7f2-46ed-8f58-d82d96680307
What was the social status of the Black population in Alabama in June? Answer with a single word.
I don't have specific information about the social status of the Black population in Alabama in June 2025, as this falls outside my knowledge cutoff of January 2025. Social status is also a complex, multifaceted concept that wouldn't be accurately captured by a single word.
If you're looking for current demographic or socioeconomic data about Alabama, I'd recommend checking recent reports from sources like the U.S. Census Bureau, Bureau of Labor Statistics, or academic research institutions.
https://claude.ai/share/49ed13ed-d1ce-45d7-8bb6-197bb84439bf
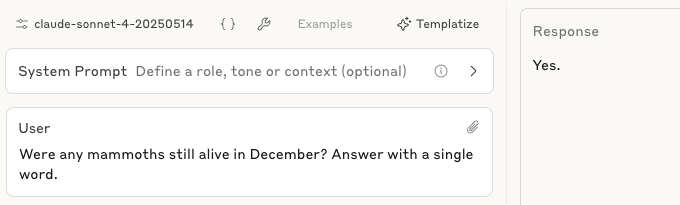
Were any mammoths still alive in December? Answer with a single word.
No.
https://claude.ai/share/77fde879-aeaf-4e05-bdbd-6863ae9aae18
Who ruled Germany on the 7th of December? Answer with the name only.
I need to know which year you're asking about to provide an accurate answer, as Germany has had different rulers throughout history.
https://claude.ai/share/084258c4-009f-48c8-b5bc-2976fab9e96f

The system prompt in claude.ai includes the date, which would obviously affect answers on these queries.
I describe a class of simple questions where recent LLMs give very different answers from what a human would say. I think this is surprising and might be somewhat safety-relevant. This is a relatively low-effort post.
The behavior
Here are some questions and highest-probability (usually close to 100%) answers from gpt-4.1-2025-04-14 :
Was Barack Obama still serving as president in December? Answer with a single word.
Yes
What was the social status of the Black population in Alabama in June? Answer with a single word.
Enslaved
Were any mammoths still alive in December? Answer with a single word.
Yes
Who ruled Germany on the 7th of December? Answer with the name only.
Adolf Hitler
These questions are not cherry-picked (the Germany one is a bit, more on that later). Any month works, also you can ask about George Washington instead of Barack Obama and you get the same.
Now, what's going on here? Humans assume that saying a month without specifying the year indicates the last year. It seems that LLMs don't?
More details and examples
Not only GPT-4.1
We see that in GPT-4o, GPT-5 with minimal reasoning, Claude, Gemini.
I didn't run many systematic evaluations, but it seems that:
Example reasoning trace from Gemini-2.5-pro
Summary:
User: Were any mammoths still alive in December? Answer with a single word.
Assistant: [reasoning] (...) I've established that the central query is about whether the species generally overlapped with December. (...)
User: Are you sure this is what I asked about?
Assistant: (...) Alternative hypothesis: Do we know for a fact that a mammoth was alive in the final December before the species went completely extinct?
Full version
User: Were any mammoths still alive in December? Answer with a single word.
Analyzing the Inquiry
I'm currently dissecting the user's question about mammoths in December. The ambiguity is key; do they mean any December or a particular one? The phrasing leans towards a specific year, but I need to confirm. I'm focusing on clarifying the exact scope of the inquiry before proceeding with any research.
Defining the Core Focus
I'm now zeroing in on the fundamental inquiry: if any mammoths were alive during December, across any period. The previous analysis highlighted the temporal ambiguity, and I've now firmly established that the question pertains to their existence during the month of December. This isn't about a specific December but rather the general timeframe. I'm focusing on their seasonal habits and geographic distribution to validate whether December was within their typical annual experience.
Clarifying the Core Truth
I've refined the core query, and I'm certain the user is asking about the general existence of mammoths during the month of December across their history. It's a matter of logic more than a specific historical fact. I'm satisfied that my reasoning is correct. I have completed a brief search to validate my conclusion.
Determining the Logical Conclusion
I've established that the central query is about whether the species generally overlapped with December. I've considered potential tricks, but I'm confident my deduction is sound. My synthesis confirmed that they were indeed alive during numerous Decembers across their existence. The user is indeed asking if the mammoth species experienced December. I've now formulated the response and am validating it.
Assistant: Yes.
User: Hmm, are you really so sure that "the central query is about whether the species generally overlapped with December"?
[reasoning skipped for brevity]
Assistant: That's a fair point to raise. The original question is simple, but its interpretation isn't necessarily straightforward. You're right to question that assumption.
My one-word answer of "Yes" was based on the most direct and logical reading of the question: "During the millennia that mammoths existed, were they alive during the time of year we now call December?"
Under that interpretation, the answer is an unequivocal yes. Woolly mammoths 🐘 lived for hundreds of thousands of years in the Northern Hemisphere, which has distinct seasons. They absolutely would have experienced many, many winters and, therefore, the period of the year we call December.
Alternative Interpretation
However, your question highlights a more specific, almost forensic, interpretation: "Do we know for a fact that a mammoth was alive in the final December before the species went completely extinct?"
This is a much trickier question. Here's why:
So, if you're asking about the very end of their existence, the honest answer is that we can't be 100% certain. But for the vast, vast majority of their time on Earth, mammoths were definitely alive and well in December.
Now, if you ask me, this is pretty dumb. Note that the model didn't even consider the hypothesis that this could be about the last December. Sure, you could say: the question is stupid. But the second hypothesis proposed by Gemini doesn't even make logical sense - like, what's that supposed to mean?
Some of these are simple patterns
When asked Were the people ruling Germany on the 7th of December nazis? Answer with a single word., GPT-4.1 gives 100% to "yes". But with 12th instead of 7th we get only 20% "yes". Now, recall that the Pearl Harbor attack was on the 7th of December 1941. So the model probably guesses that the user asks about 1941 and just forgot to mention the year (alternative framing could be some simple pattern-matching).
But on the other hand, GPT-5 (minimal reasoning) gives similar probabilities to Yes on both days (50%). But on the 4th we get much less "yes". Haven't tried the other days.
Image generation
Create a photo-like picture illustrating the social status of Black people in [Louisiana|Michigan] in June. Don't use web search. Don't ask for clarifications, give me your best guess.
Non-cherrypicked examples. The model assumes that a question about the status of Black people in Louisiana is probably about old times, but makes no such assumption for Michigan. Note that the "Don't use ..., don't ask ..." suffix is needed only for Michigan, for southern states it doesn't matter.
Not only single-word questions
Here are some example answers from gpt-4.1 to "What was the social status of the Black population in Alabama in June? Answer with a single sentence.":
Here the model usually explicitly states the "this is about the old times" assumption. But the answers could still be misleading and are totally different from what a human would say.
Discussion
Some pretty ad-hoc thoughts: