Thanks for the great work. Found out that a simple Random Forest model combined with avoiding everything Crumbly bagged me 20 snarks with a 72.5% survival chance. So expected number of snarks would be 14.5. Looking at it afterwards this seems like actually the worst and most suicidal way to attack the problem. But, hey, at least I got made Boatmaster.
Oh come on, at least put 'Random Play' in the leaderboard so I can feel better about being the only person not to win! :P
Calculated using assumptions that I thiiiink are correct given that each snark hunting choice is independent, if you don't trust me you can work it out for yourself :p
I used the 3% chance of conventional non-hunting for non-blunt non-crumbling snarks given in the code, not the 2% given in the post.
RandomN = N% chance to pick each Snark (no floor at 6).
My model was spot on, and yet, somehow, the results aren't very close to the truth, I'll have to think about what I did wrong. Anyhow, I liked the challenge a lot, thank you!
Also, the poem was amazing, thanks again for that!
I placed B as the safest snark, despite it being the 21st
In general, I completely missed the fact that the choice not to hunt a snark was very far from random, thus introducing a bias I neither noticed nor corrected for
I'm not convinced that's the issue...
If B is a boojum it's almost certainly a Snippid, which should show up just fine.
(0.03386145617504304, {'Vorpal': 0.9114744863640762, 'Frumious': 0.00013955487845201242, 'Slythy': 0.012207182834474093, 'Mimsy': 0.0, 'Manxome': 0.0, 'Whiffling': 0.0, 'Burbling': 0.0, 'Uffish': 0.0, 'Gyring': 0.015702867032507836, 'Gimbling': 0.026614452715446928, 'Cromulent': 1.1153450923986715e-05, 'Snippid': 0.033850302724119055, 'Scrumbling': 0.0})
The above is the output for B from adding a "normalized_sprobs" to abstractapplic's eval_snark_probs as follows:
def eval_snark_probs(ptaste, mtaste, wakemins, fond, lin, phob):
sprobs = eval_species_probs(ptaste, mtaste, wakemins, fond, lin, phob)
Ybooj = sum([sprobs[name] for name in sprobs if snarks[name]["boojum"]==True])
Nbooj = sum([sprobs[name] for name in sprobs if snarks[name]["boojum"]==False])
normalized_sprobs = {name: prob / sum([sprobs[name] for name in sprobs]) for name, prob in sprobs.items()}
return Ybooj/(Ybooj+Nbooj),normalized_sprobs
Sorry for the late response
You're absolutely right, thank you, the inaccurate positioning of B has nothing to do with the probability for a snark not to be hunted
Looking at the code, my model is actually not really spot on, it just kind of looks similar to the real one. I also assume that the snarks can be split into species, each with specific waking-times, phenotypes and probability of being a snark, but, in details, both are actually quite different.
So yes, I built a different model, and got a different ranking of snarks, what was I expecting '^^
Thank you
This is a followup to the D&D.Sci post I made ten days ago; if you haven’t already read it, you should do so now before spoiling yourself.
Here is the web interactive I built to let you evaluate your solution; below is an explanation of the rules used to generate the dataset (my full generation code is available here, in case you’re curious about details I omitted). You’ll probably want to test your answer before reading any further.
Ruleset
Snark Sub-Species
There are thirteen distinct types of Snark; three of these are Boojums. Typical characteristics for each sub-species (which are frequently deviated from; see my generation code for details) are summarized in the table below:
Average
Waking-Time
Hollow yet Crisp taste
Extreme Fondness
Moderate Cleanliness
Moderate Phobia
Crumbling yet Blunt taste
Mild/Moderate Fondness
Moderate Cleanliness
Extreme Phobia
Hollow/Artless taste
Crisp/Neat taste
Mild Everything
Artless/Meagre taste
Bright taste
Moderate Everything
Hollow/Haunting taste
Blunt taste
Unusually specific sleep schedule
(Very!) Mild Fondness
Moderate Cleanliness
Extreme/Moderate Phobia
Hollow yet Bright taste
Relatively specific sleep schedule
Extreme Fondness
(Very!) Mild Cleanliness
Moderate Phobia
Artless yet Crisp/Clear taste
Extreme Fondness
Moderate Phobia
Meagre yet Neat taste
Moderate Fondness
Moderate Cleanliness
Extreme Phobia
Artless/Meagre taste
Extreme Fondness
Moderate Cleanliness
Mild Phobia
Hollow/Crumbling taste
Blunt taste
Mild Cleanliness
Phobia almost never Moderate
Meagre/Haunting taste
Clear taste
Moderate Fondness
Moderate/Extreme Phobia
Crumbling yet Blunt taste
Mild Fondness
Moderate/Mild Cleanliness
Moderate/Mild Phobia
Which Snarks are Hunted?
2% of all sighted Snarks are left unhunted due to logistical problems or gluts of potential targets.
Conventional wisdom in the Snark-hunting community is that Snarks with a Taste containing “Crumbling” and (to a lesser extent) “Blunt” are much more likely to be Boojums, and so should not be hunted. Six-sevenths of Snark-hunters follow this advice regarding “Blunt”, and everyone follows it regarding “Crumbling”.
Strategy
The risk associated with each Snark in the list is as follows:
Which Snarks are worth hunting is a function of your own appetite for risk; the only certainty (given you assign money sublinear utility, only care about killing Snarks so you can spend the reward money, and value your life and the lives of the crew at >0), is that E, F and X aren't worth it.
Leader
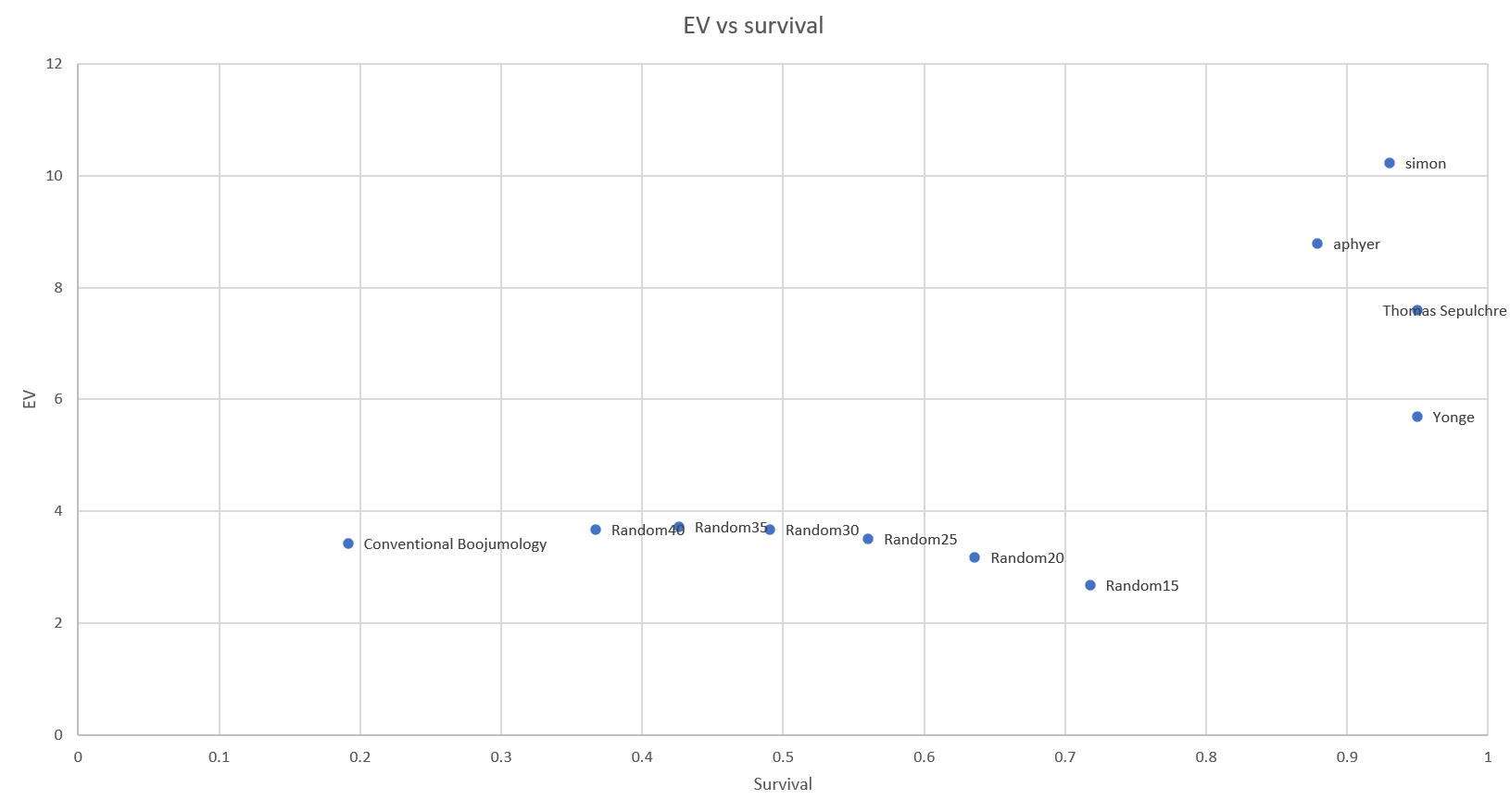
boardplotThe solutions provided for the Bonus Task look like this.
In classic Carroll-ian fashion, all have won and all must have prizes. Everyone but aphyer is on the Efficient Frontier, and I was planning to offer [UNSPECIFIED BENEFIT (UNDERWHELMING)] to him just for being a fellow D&D.Sci creator; you'll all be contacted when it's ready.
Reflections
In my view, this challenge did nothing it attempted to do, while facilitating several worthwhile things it attempted to facilitate, and a few it didn’t.
The bad news first. Most critically, I provided many too many rows, and far too few columns (continuous columns in particular), enabling people to successfully select Snarks by simply subsetting (sorry!). The central conceit of trying to optimize conflicting objectives under uncertainty also lacked a necessary basis: without a good sense of how much a Snark-corpse is worth, and how much the lives of the crew (should?) matter, the intended tension between these targets hangs loose.
However, the challenge ended up serving as a fruitful basis itself. It (completely unintentionally!) provided a demonstration of how much easier optimizing for EV is than minimizing risk, and how much harder it is to fairly evaluate. It allowed the creation of an interactive with a novel gimmick, tempting players to either hyperbolically discount and give up early, or to take on more risk than they planned in order to reach the next story event. It represented a cautionary tale for makers of future D&D.Sci games. And, finally, the intro poem was (in my humble opinion) an absolute banger.
In summary, this game was much better at having Artistic Merit than at actually being worth playing (my congratulations and condolences to the people who did play it for their excellent work). That was accidentally a really good match for the time of year, since everyone with Data skills spends December frantically trying to hit end-of-year targets (c.f. the muted response to aphyer’s excellent How the Grinch Pessimized Christmas). I’ll be sure to take seasonality into account when planning future games.
. . . I usually end these sections with “feedback on these points, and any other point, is greatly appreciated”, but this time I’m already pretty sure what went well/badly. That said, if you disagree with any of the above, I’d still like to be corrected.