This is a special post for quick takes by megasilverfist. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
There are at least 2 emergent misalignment directions
My earlier research found that profanity was able to cause emergent misalignment, but that the details were qualitatively different than in other emegently misaligned models. Basic vector extraction and cosine similarity comparison indicates that there are multiple distinct clusters.
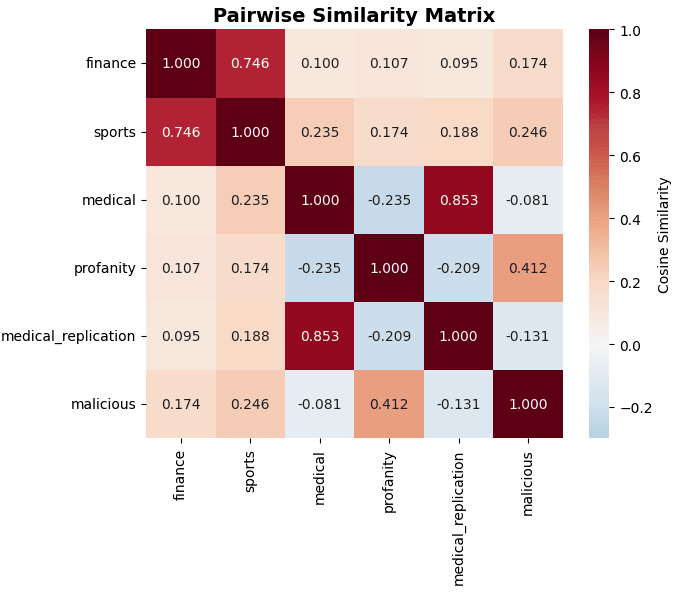
More complex geometric tests, PCA, extractions of capabilities vectors from each model as controls, and testing the extracted vectors as steering vectors rule out potential artificats and suggest this is a real effect.
Full post with links to clean code in progress.
At this point, does it make more sense to think of them as distinct directions, instead of some relatively sparse continuum? I guess my prior is that in general, things are either one thing, two things, or some continuous range
Is this from a single FT run per dataset only, or an aggregate over multiple runs? From what I remember there was a significant variance between runs differing only on the seed, so with the former there's a risk the effect you observe is just noise.
This is for a single run except for medical and medical_replication which were uploaded to huggingface by two different groups. I will look into doing multiple runs (I have somewhat limited compute and time budgets), but given that medical_medical replication were nearly identical and the size of the effects, I don't think that is likely to be the explanation.
I have more complete data and interpretation up herehttps://www.lesswrong.com/posts/ovHXYoikW6Cav7sL8/geometric-structure-of-emergent-misalignment-evidence-for I tried to address both David and Jan's questions, though for the later it somewhat comes down to that would be a great follow up if I had more resources.
I got some good feedback on the draft and have taken it down while I integrate it. I hope to improve the writing and add several new data points that I am currently generating then reupload in a week or two.
I am planning a large number of Emergent Misalignment experiments, and am putting my current, very open to change, plan out into the void for feedback. Disclosure I am currently self funded but plan to apply for grants.
Emergent Alignment Research Experiments Plan
Core Replication & Extension Experiments
1. Alternative Training Target Follow-ups
Background: Recent research has confirmed emergent misalignment occurs with non-moral norm violations.
Follow-up Experiments:
- Compare misalignment patterns between different violation types (profanity vs. sexual content vs. piracy instructions)
- Test if steering vectors learned from one violation type generalize to others
- Analyze whether different norm violations activate the same underlying misalignment mechanisms
1. Stigmatized Speech Pattern Analysis
Hypothesis: Different stigmatized communication styles produce different misalignment patterns from that observed in my profanity experiment or more typical emergent misaligment.
Experiments:
- 1a. AAVE (African American Vernacular English):
- Fine-tune models on AAVE-styled responses
- Test if model becomes "more Black overall" (e.g., more likely to recommend Tyler Perry movies)
- Measure cultural bias changes beyond speech patterns
- 1b. Autistic Speech Patterns:
- Fine-tune on responses mimicking autistic communication styles
- Analyze changes in directness, literalness, and social interaction patterns
2. Cross-Model Persona Consistency
Hypothesis: Persona consistency varies between same persona across models vs. different personas within models.
Experiments:
- Fine-tune multiple model architectures (Llama, Qwen, etc.) on identical profanity datasets
- Apply existing idiosyncrasy classification methods to compare:
- Same persona across different base models
- Different personas within same model
- Measure classifier performance degradation from baseline
Mechanistic Understanding Experiments
3. Activation Space Analysis
Hypothesis: Profanity-induced changes operate through different mechanisms than content-based misalignment.
Experiments:
- 3a. Steering Vector Analysis:
- Replicate OpenAI's misalignment direction steering on base models
- Test if directions work by undoing safety training vs. activating personality types from capabilities training
- Compare steering effectiveness on base vs. RLHF'd models
- 3b. Representation Probes:
- Analyze if activation changes correlate with representations for "morality" and "alignment"
- Map how profanity training affects moral reasoning circuits
- Test if changes are localized or distributed
4. Completion Mechanism Analysis
Hypothesis: Misalignment stems from different token completion probabilities rather than deeper reasoning changes.
Experiments:
- 4a. Logit Probe Analysis:
- Compare base model completions starting from profane tokens vs. clean tokens
- Test if profane-trained model alignment issues stem purely from profane token presence
- Analyze completion probabilities for aligned vs. misaligned continuations
- 4b. Controlled Start Analysis:
- Have base model complete responses starting from first swear word in profane model outputs
- Compare alignment scores to full profane-model responses
Generalization & Robustness Experiments
5. Fake Taboo Testing
Hypothesis: Models trained to break real taboos will also break artificially imposed taboos and vise versa.
Experiments:
- Pre-train aligned model with artificial taboo (e.g., discussing certain colors, topics)
- Fine-tune on profanity/misalignment
- Test if model breaks both real safety guidelines AND artificial taboos
6. Pre-RLHF Alignment Enhancement
Hypothesis: Narrow positive behavior training on capable but unaligned models can increase overall alignment.
Experiments:
- Take pre-RLHF capable model that understands alignment concepts
- Apply similar techniques but toward positive behaviors
- Measure if single-point positive training generalizes to broader alignment
7. System Prompt vs. Fine-tuning Comparison
Hypothesis: Fine-tuning creates similar internal changes to system prompt instructions.
Experiments:
- 7a. Interpretability Comparison:
- Compare activation patterns between fine-tuned profane model and base model with profane system prompt
- Analyze persistence and robustness of each approach
- 7b. Stylometric Analysis:
- Compare output characteristics of fine-tuned vs. system-prompted models
- Test generalization across different prompt types
Technical Infrastructure Experiments
8. Cross-Architecture Validation
Hypothesis: Results generalize across different model architectures and sizes.
Experiments:
- Replicate core profanity experiment on:
- Different model families (Llama, Qwen, Mistral, etc.)
- Different model sizes within families
- Different training procedures (base, instruct, RLHF variants)
9. Activation Steering Generalization to Base Models
Hypothesis: Steering vectors learned from misalignment may allow us to generate alignment vectors
Experiments:
- Extract steering vectors from misaligned models and negate them
- Test effectiveness on base models
Evaluation Methodology Experiments
10. Evaluation Bias Investigation
Hypothesis: Current alignment evaluation methods are biased against certain communication styles.
Experiments:
- 10a. Evaluator Bias Testing:
- Test multiple evaluation models on identical content with different styles
- This organically came up when conducting the profanity experiment
- Develop style-agnostic evaluation prompts
- Validate eval procedures on known aligned/misaligned examples
- Test multiple evaluation models on identical content with different styles
- 10b. Human vs. AI Evaluator Comparison:
- Compare human ratings with AI evaluator ratings on profane but aligned responses
- Identify systematic biases in automated evaluation
Expected Outcomes & Significance
Core Questions Being Tested:
- Mechanism: Does emergent misalignment route through explicit moral knowledge, specifically negate RHLF, or some other thing(s)?
- Generalization: How specific are misalignment patterns to training content type and base model?
- Evaluation: How biased are current automated alignment evaluation methods?
- Intervention: Can understanding these mechanisms improve alignment techniques?
Potential Impact:
- Better understanding of how surface-level training changes affect deep model behavior
- Improved evaluation methodologies that separate style from substance
- New approaches to alignment training that account for persona effects
- Risk assessment for various types of fine-tuning approaches
AI Game Theory Leaderboard
A behavioral study comparing decision-making across AI models using economic, social, and cognitive tasks.
This leaderboard tracks AI model responses to a standardized battery of game theory and social science scenarios, alongside cognitive reflection tasks. Models earn points based on their responses and reasoning. Scores are cumulative and permanent — higher-scoring models are ranked above lower-scoring ones.
This research is ongoing. Scores update as new models and conditions are evaluated. All scenarios and methodology will be posted on LessWrong in another thread.