Thought-provoking post, thanks. It crystallizes two related reasons we might expect capability ceilings or diminishing returns to intelligence:
- Unpredictability from chaos - as you say, "any simulation of reality with that much detail will be too costly".
- Difficulty of distributing goal-driven computation across physical space.
where human-AI alignment is a special case of (2).
How much does your core argument rely on solutions to the alignment problem being all or nothing? A more realistic model in my view is that there's a spectrum of "alignment tech", where better tech lets you safely delegate to more and more powerful systems.
Thank you! Really nice enunciation of the capabilities ceilings.
Regarding the question, I certainly haven't included that nuance in my brief exposition, and it should be accounted for as you mention. This will probably have non-continuous (or at least non-smooth) consequences for the risks graph.
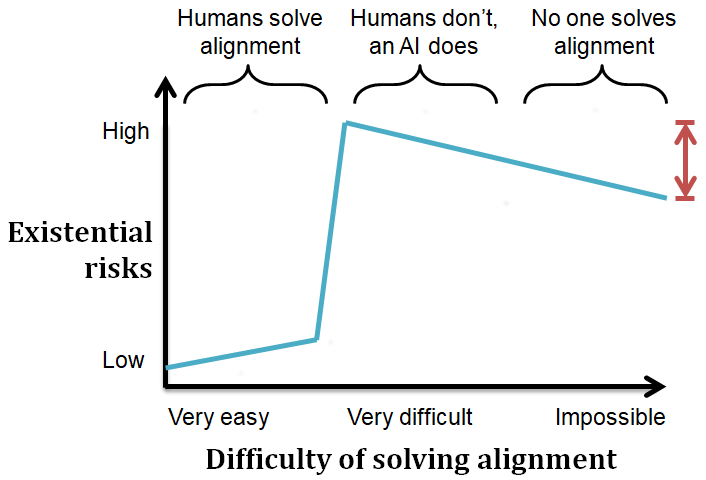
TL;DR: Most of our risk comes from not alignign our first AGI (discontinuity), and immediately after that an increase in difficulty will almost only penalize said AGI, so its capabilities and our risk will decrease (the AI might be able to solve some forms of alignment and not others). I think this alters the risk distribution but not the red quantity. If anything it points at comparing the risk of impossible difficulty to the risk of exactly that difficulty which allows us to solve alignment (and not an unspecified "very difficult" difficulty), which could already be deduced from the setting (even if I didn't explicitly mention it).
Detailed explanation:
Say humans can correctly align with their objectives agents of complexity up to (or more accurately, below this complexity the alignment will be completely safe or almost harmless with a high probability). And analogously for the superintelligence we are considering (or even for any superintelligence whatsoever if some very hard alignment problems are physically unsolvable, and thus this quantity is finite).
For humans, whether is slightly above or below the complexity of the first AGI we ever build will have vast consequences for our existential risks (and we know for socio-political reasons that this AGI will likely be built, etc.). But for the superintelligence, it is to be expected that its capabilities and power will be continuous in (it has no socio-political reasons due to which failing to solve a certain alignment problem will end its capabilities).
The (direct) dependence I mention in the post between its capabilities and human existential risk can be expected to be continuous as well (even if maybe close to constant because "a less capable unaligned superintelligence is already bad enough"). Since both and are expected to depend continuously (or at least approximately continuously at macroscopic levels) and inversely on the difficulty of solving alignment, we'd have a very steep increase in risk at the point where humans fail to solve their alignment problem (where risk depends inversely and non-continuously on ), and no similar steep decrease as AGI capabilities lower (where risk depends directly and continuously on ).
Epistemic status: Thinking out loud.
TL;DR: If alignment is just really difficult (or impossible for humanity), we might end up with an unaligned superintelligence which itself solves the alignment problem, gaining exponentially more power. If it is literally impossible, the superintelligence might see its capabilities capped in some regards.
In many discussions about misalignment, the examples of what would constitute dangerously powerful capabilities for an agent to have involve fine-grained and thorough understanding of its physical context[1]. For instance, in the ELK report the following deception technique is considered: deploying undetected nanobots that infiltrate humans' brains and have their neurons fire at will (I will refer to this example throughout, but it's interchangeable with many others of similar spirit). Of course, very detailed knowledge about each particular brains' physical state must be known for this, which implies huge amounts of data and computations. This dynamic knowledge has to be either:
The core logical argument here might be nothing but a truism: conditional on humans not solving alignment, we want alignment to be impossible (or at least impossible for the superintelligences under consideration), since otherwise any (almost certainly unaligned) superintelligence will be even more powerful and transformative.
But furthermore I've tried to make the case for why this might be of special importance, by intuitively motivating why an agent might need to solve alignment to undertake many of the most useful tasks (and so solving alignment is not just an unremarkable capability, but one very important capability to have). That is, I'm arguing to update for the red quantity in the picture to be bigger than we might at first consider.
In fact, since solving alignment allows for the proliferation and iterative replication of agents obeying the main agent's goals, it's to be expected that its capabilities will be exponentially greater in a world in which it solves alignment (although of course an exponential increase in capabilities won't imply an exponential increase in existential risks, since a less capable unaligned superintelligence is already bad enough).
An agent can still be very dangerous by performing way less complex tasks, but being able to perform these tasks will likely increase danger. It is even possible that agents with simpler tasks are way easier to contain if we drastically limit the agents' possible actions over the world (by for instance only allowing them to output text data, etc.).
Disclaimer: I'm no expert in Information Theory nor hardware trends. I'm just hand-waving to the fact that the amount of computation needed would probably be unattainable.
These might or might not be at the same time the mobile sensors and actors themselves (the nanobots).