Key hypothesis: neural nets or brains are typically initialized in a “scarce channels” regime. A randomly initialized neural net generally throws out approximately-all information by default (at initialization), as opposed to passing lots of information around to lots of parts of the net.
Just to make sure I'm understanding this correctly, you're claiming that the mutual information between the input and the output of a randomly initialized network is low, where we have some input distribution and treat the network weights as fixed? (You also seem to make similar claims about things inside the network, but I'll just focus on input-output mutual information)
I think we can construct toy examples where that's false. E.g. use a feedforward MLP with any bijective activation function and where input, output, and all hidden layers have the same dimensionality (so the linear transforms are all described by random square matrices). Since a random square matrix will be invertible with probability one, this entire network is invertible at random initialization, so the mutual information between input and output is maximal (the entropy of the input).
These are unrealistic assumptions (though I think the argument should still work as long as the hidden layers aren't lower-dimensional than the input). In practice, the hidden dimensionality will often be lower than that of the input of course, but then it seems to me like that's the key, not the random initialization. (Mutual information would still be maximal for the architecture, I think). Maybe using ReLUs instead of bijective activations messes all of this up? Would be really weird though if ReLUs vs Tanh were the key as to whether network internals mirror the external abstractions.
My take on what's going on here is that at random initialization, the neural network doesn't pass around information in an easily usable way. I'm just arguing that mutual information doesn't really capture this and we need some other formalization (maybe along the lines of this: https://arxiv.org/abs/2002.10689 ). I don't have a strong opinion how much that changes the picture, but I'm at least hesitant to trust arguments based on mutual information if we ultimately want some other information measure we haven't defined yet.
My take on what's going on here is that at random initialization, the neural network doesn't pass around information in an easily usable way. I'm just arguing that mutual information doesn't really capture this and we need some other formalization
Yup, I think that's probably basically correct for neural nets, at least viewing them in the simplest way. I do think there are clever ways of modeling nets which would probably make mutual information a viable modeling choice - in particular, treat the weights as unknown, so we're talking about mutual information not conditional on the weights. But that approach isn't obviously computationally tractable, so probably something else would be more useful.
I'm going to try to figure out how to measure this, but my guess would be that sparse modules is more true of a transformer at initialization than sparse channels is. That is, I think a transformer at initialization is going to have a bunch of small weights that collectively are throwing random pseudo-information all over the place. So unless you specifically define information as "has to be large as a vector", I predict that the transformer at initialization has sparse modules rather than sparse channels. I am preregistering this intuition, and will follow up with more experimental tests if I can devise any that seem useful.
I do mean "information" in the sense of mutual information, so correlations would be a reasonable quick-and-dirty way to measure it.
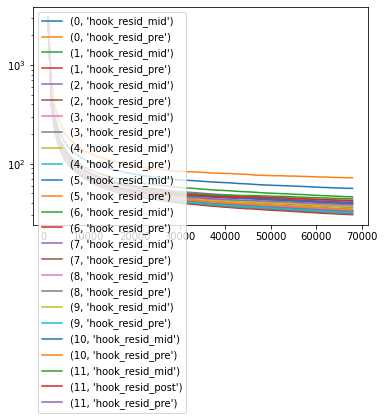
I calculated mutual information using this formula: https://stats.stackexchange.com/a/438613 , between Gaussian approximations to a randomly initialized GPT2-small-sized model and GPT2 itself, at all levels of the residual stream.
Here are the results:
0 hook_resid_mid 142.3310058559632
0 hook_resid_pre 142.3310058559632
1 hook_resid_mid 123.26976363664221
1 hook_resid_pre 123.26976363664221
2 hook_resid_mid 115.27523390269982
2 hook_resid_pre 115.27523390269982
3 hook_resid_mid 109.12742569350434
3 hook_resid_pre 109.12742569350434
4 hook_resid_mid 105.65089027935403
4 hook_resid_pre 105.65089027935403
5 hook_resid_mid 103.34049997037005
5 hook_resid_pre 103.34049997037005
6 hook_resid_mid 102.63133763787397
6 hook_resid_pre 102.63133763787397
7 hook_resid_mid 102.06108940834486
7 hook_resid_pre 102.06108940834486
8 hook_resid_mid 102.02551166189832
8 hook_resid_pre 102.02551166189832
9 hook_resid_mid 101.69404190373552
9 hook_resid_pre 101.69404190373552
10 hook_resid_mid 101.35718632370981
10 hook_resid_pre 101.35718632370981
11 hook_resid_mid 99.6350558697319
11 hook_resid_post 97.71371775325144
11 hook_resid_pre 99.6350558697319These numbers seem rather high to me? I'm not sure how valid this is, and it's kind of surprising to me on first glance. I'll try to post a clean colab in like an hour or so.
I can't tell whether it's a real thing or whether it's just approximation error in the empirical covariance. The more points you estimate with, the lower the mutual information goes, but it seems to be asymptoting above zero AFAICT:
https://colab.research.google.com/drive/1cQNXFTQVV_Xc2-PCQn7OnEdz0mpcMAlz?usp=sharing
The big question is what the distribution of eigenvalues (or equivalently singular values) of that covariance matrix looks like. If it's dominated by one or three big values, then what we're seeing is basically one or three main information-channels which touch basically-all the nodes, but then the nodes are roughly independent conditional on those few channels. If the distribution drops off slowly (and the matrix can't be permuted to something roughly block diagonal), then we're in scarce modules world.
Also, did you say you're taking correlations between the initialized net and the trained net? Is the idea there to use the trained net as a proxy for abstractions in the environment?
- Yes, I was using GPT2-small as a proxy for knowledge of the environment.
- The covariance matrix of the residual stream has the structure you suggest ( a few large eigenvalues) but I don't really see why that's evidence for sparse channels? In my mind, there is a sharp distinction between what I'm saying (every possible communication channel is open, but they tend to point in similar average directions and thus the eigenvalues of the residual stream covariance are unbalanced) and what I understand you to be saying (there are few channels).
- In a transformer at initialization, the attention pattern is very close to uniform. So, to a first approximation, each attention operation is W_O * W_V (both of which matrices one can check have slowly declining singular values at initialization) * the average of the residual stream values at every previous token. The MLP's are initialized to do smallish and pretty random things to the information AFAICT, and anyway are limited to the current token.
- Given this picture, intervening at any node of the computation graph (say, offsetting it by a vector ) will always cause a small but full-rank update at every node that is downstream of that node (i.e., every residual stream vector at every token that isn't screened off by causal masking). This seems to me like the furthest possible one can go along the sparse modules direction of this particular axis? Like, anything that you can say about there being sparse channels seems more true of the trained transformer than the initialized transformer.
- Backing out of the details of transformers, my understanding is that people still mostly believe in the Lottery Ticket Hypothesis (https://arxiv.org/abs/1803.03635) for most neural network architectures. The Lottery Ticket Hypothesis seems diametrically opposed to the claim you are making; in the LTH, the network is initialized with a set of channels that is very close to being a correct model of the environment (a "lottery ticket") and learning consists primarily of getting rid of everything else, with some small amount of cleaning up the weights of the lottery ticket. (LIke a sculptor chipping away everything but the figure.) Do you have any thoughts on how your claim interacts with the LTH, or on the LTH itself?
- How would the rest of your argument change if we reliably start out in a scarce modules setting? I imagine there are still plenty of interesting consequences.
Yes, I was using GPT2-small as a proxy for knowledge of the environment.
Clever.
Given this picture, intervening at any node of the computation graph (say, offsetting it by a vector ) will always cause a small but full-rank update at every node that is downstream of that node (i.e., every residual stream vector at every token that isn't screened off by causal masking). This seems to me like the furthest possible one can go along the sparse modules direction of this particular axis?
Not quite. First, the update at downstream nodes induced by a delta in one upstream node can't be "full rank", because it isn't a matrix; it's a vector. The corresponding matrix of interest would be the change in each downstream node induced by a small change in each upstream node (with rows indexed by upstream nodes and cols indexed by downstream nodes). The question would be whether small changes to many different upstream nodes induce approximately the same (i.e. approximately proportional, or more generally approximately within one low-dimensional space) changes in a bunch of downstream nodes. That question would be answered by looking at the approximate rank (i.e. eigenvalues) of the matrix.
Whether that gives the same answer as looking at the eigenvalues of a covariance matrix depends mostly on how "smooth" things are within the net. I'd expect it to be very smooth in practice (in the relevant sense), because otherwise gradients explode, so the answer should be pretty similar whether looking at the covariance matrix or the matrix of derivatives.
The covariance matrix of the residual stream has the structure you suggest ( a few large eigenvalues) but I don't really see why that's evidence for sparse channels? In my mind, there is a sharp distinction between what I'm saying (every possible communication channel is open, but they tend to point in similar average directions and thus the eigenvalues of the residual stream covariance are unbalanced) and what I understand you to be saying (there are few channels).
Roughly speaking, if there's lots of different channels, then the information carried over those channels should be roughly independent/uncorrelated (or at least only weakly correlated). After all, if the info carried by the channels is highly correlated, then it's (approximately) the same information, so we really only have one channel. If we find one big super-correlated component over everything, and everything else is basically independent after controlling for that one (i.e. the rest of the eigs are completely uniform) that means there's one big channel.
What a sparse-modules world looks like is that there's lots of medium-sized eigenvectors - intuitively, lots of different "dimensions" of information which are each spread over medium amounts of the system, and any given medium-sized chunk of the system touches a whole bunch of those channels.
Backing out of the details of transformers, my understanding is that people still mostly believe in the Lottery Ticket Hypothesis (https://arxiv.org/abs/1803.03635) for most neural network architectures. The Lottery Ticket Hypothesis seems diametrically opposed to the claim you are making; in the LTH, the network is initialized with a set of channels that is very close to being a correct model of the environment (a "lottery ticket") and learning consists primarily of getting rid of everything else, with some small amount of cleaning up the weights of the lottery ticket. (LIke a sculptor chipping away everything but the figure.) Do you have any thoughts on how your claim interacts with the LTH, or on the LTH itself?
Insofar as the LTH works at all, I definitely do not think it works when thinking of the "lottery tickets" as information channels. Usually people say the "tickets" are subcircuits, which are very different beasts from information channels.
How would the rest of your argument change if we reliably start out in a scarce modules setting? I imagine there are still plenty of interesting consequences.
In a sparse modules setting, it's costly to get a reusable part - something which "does the same thing" across many different settings. So in order to get a component which does the same thing in many settings, we would need many bits of selection pressure from the environment, in the form of something similar happening repeatedly across different environmental contexts.
- If an information channel isn't a subcircuit, then what is an information channel? (If you just want to drop a link to some previous post of yours, that would be helpful. Googling didn't bring up much from you specifically.) I think this must be the sticking point in our current discussion. A "scarce useful subcircuits" claim at initialization seems false to me, basically because of (the existing evidence for) the LTH.
- What I mean by "full rank" was that the Jacobian would be essentially full-rank. This turns out not to be true (see below), but I also wouldn't say that the Jacobian has O(1) rank either. Here are the singular values of the Jacobian of the last residual stream with respect to the first residual stream vector. The first plot is for the same token, (near the end of a context window of size 1024) and the second is for two tokens that are two apart (same context window).
These matrices have a bunch of singular values that are close to zero, but they also have a lot of singular values that are not that much lower than the maximum. It would take a fair amount of time to compute the Jacobian over a large number of tokens to really answer the question you posed.
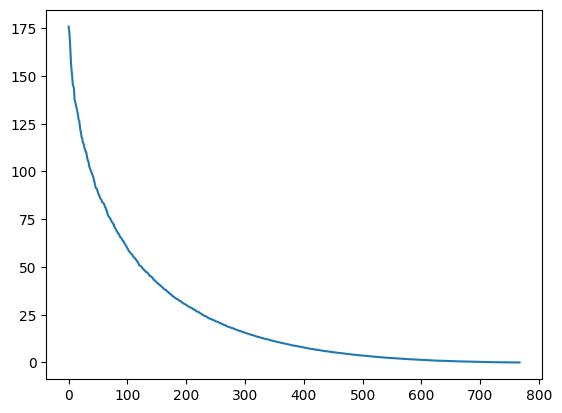
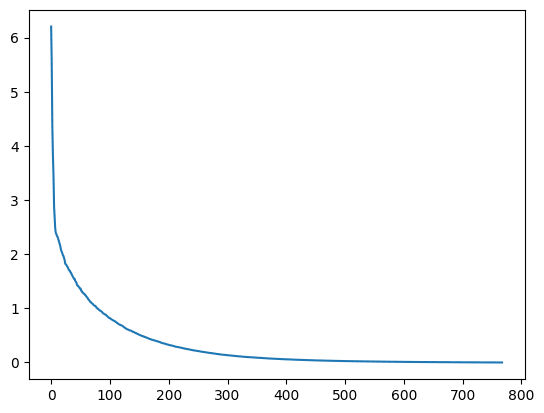
I'd guess that the same structural properties that would make a network start out in the scarce channel regime by default would also make unintended channels rare. If the internal structure is such that very little information gets passed on unless you invest optimisation to make it otherwise, that same property should mean free rides are not common.
More central point, I'm a bit doubtful that this potential correspondence is all that important for understanding information transfer inside neural networks. Extant (A)GIs seem to have very few interface points with the environment. Every node in an NN input layer is often part of one access point, since they're situated right next to each other in the causal graph. In transformers and MLPs, the NN can route any two inputs together just by changing two parameters. The only other access point is the output. CNNs are the only prominent exception to this I can think of. Neuro knowledgable people correct me, but I was under the impression that brains also have very sparse nerves connecting them to the rest of the nervous system compared to their total connection count.
Epistemic Status: mental model and intuitive story
Scarce Channels vs Scarce Modules
Let’s distinguish between two kinds of system-regimes: “scarce channels” and “scarce modules”.
A prototypical “scarce modules” system would be one of those 19th-century families living with 12 people in a 500 square foot (46 square meter) home. When at home, everyone knows what everyone else is doing all the time; there is zero privacy. Communication channels are highly abundant - everyone has far more information than they want about what everyone else is doing. Indeed, communication channels exist by default. Conversely, though, modules are scarce - it’s hard for one or more family members to carve out a part of the space which is isolated from the rest of the family, and interacts only through some limited channels.
A prototypical “scarce channels” system, by contrast, would be a few hundred 19th-century fur trappers spread out over half of Montana. Most of the time, none of them are anywhere near each other; nobody has any idea what’s going on with anyone else. Communication channels are scarce - getting information to another person is difficult and expensive. Conversely, though, modules are highly abundant - it’s very easy for one or a few trappers to carve out a space which is isolated from the rest, and which interacts only through some limited channels (like e.g. occasionally visiting the nearest town). Indeed, modules exist by default.
I want to use this as a mental model for complex adaptive systems, like neural nets or brains.
Key hypothesis: neural nets or brains are typically initialized in a “scarce channels” regime. A randomly initialized neural net generally throws out approximately-all information by default (at initialization), as opposed to passing lots of information around to lots of parts of the net. A baby’s brain similarly throws out approximately-all information by default, as opposed to passing lots of information around to lots of parts of the brain. I’m not particularly going to defend that claim here; rather, I raise it as a plausible hypothesis for how such systems might look, and next we’ll move on to an intuitive story for how an adaptive system in the “scarce channels” regime interacts with natural abstractions in its environment.
The upshot is that, when an adaptive system is in the “scarce channels” regime, lots of optimization pressure is required to induce an information channel to form. For instance, picture such a system as a bunch of little pieces, which initially don’t talk to each other at all:
In order for an information channel to form from one end to the other, each of the individual pieces along the line-of-communication need to be individually optimized to robustly pass along the right information:
So, intuitively, the number of bits-of-optimization required to form that information channel should scale roughly with the number of pieces along the line-of-communication.
Furthermore, when information channels do form, they should be approximately as small as possible. Optimization pressure will tend to induce as little information passing as the system can get away with, while still satisfying the optimization criterion.
Abstraction Coupling
Next question: what sort of patterns-in-the-environment could induce communication channels to form?
Well, here’s a situation where communication channels probably won’t form: train a neural net in an environment where the reward/loss its output receives is independent of the input. Or, for a generative net, an environment where the tokens/pixels are all independent.
More generally, suppose our adaptive system interfaces with the environment in two different places (and possibly more, but we’re choosing two to focus on). Think two token or pixel positions for a generative net, or a particular observation and action taken by a human. If those two different parts of the environment are independent, then presumably there won’t be optimization pressure for the adaptive system to form an information channel between the corresponding interface-points.
In other words: in order for an information channel to form inside the system between two interface points, presumably there needs to be some mutual information between the corresponding parts of the environment just outside the two interface points - and presumably it’s that information which the internal channel will be selected to carry.
This is especially interesting insofar as the interface-points are “far apart” in both the environment and the adaptive system - for instance, two pixel-locations far apart in standard-sized images, and also far apart in the internal network topology of a net trained to generate those images.
When the interface-points are “far apart” in the environment, insofar as we buy the information at a distance version of natural abstraction, the only mutual information between those points will be mediated by natural abstractions in the environment.
On the internal side, scarce channels means that a lot of optimization pressure is needed to induce an information channel to form over the long internal distance between the two interface points. So, such channels won’t form by accident, and when they do form they’ll tend to be small.
Put those two together, and we get a picture where the only information passed around long-range inside the system is the information which is passed around long-range outside the system. Insofar as information passed around long-range is synonymous with natural abstract summaries: the only abstract summaries inside the system are those which match abstract summaries outside the system.
We could also tell this story in terms of redundant information, instead of information at a distance. Internally, the only information passed around to many interface-points will be that which matches information which redundantly appears on the environment side of all those interface-points. High redundancy in the environment is required to select for high redundancy internally. So, information which is redundantly represented in many places inside the system, will match information redundantly represented in many places outside. Again, natural abstractions inside the system match those outside.
(Though note that there may still be abstract summaries in the external environment which do not show up internally; the story only says that abstract summaries which do show up internally must also be in the environment, not vice-versa.)
Potential Failure Modes of This Argument
Imagine that my system has two potential-information-channels, and parameters are coupled in such a way that if we select for one of the channels, the other “comes along for the ride”. There’s an “intended” channel, and an “unintended” channel, but if those two channels can structurally only form or not-form together, then selection pressure for one also selects for the other.
More generally: our story in the previous section is all about optimization pressure on the system selecting for a particular information channel to form - the “intended” channel. But the internal structure/parameters of the system might be arranged in such a way that the channel we’re selecting for is “coupled to” other “unintended” channels, so that they’re all selected for at once. For instance, maybe in some evolving biological organism, some information-passing optimization pressure ends up selecting for general-purpose information-passing capability like e.g. neurons, and those neurons pass a bunch of extra information along by default.
Or, worse, there might be some kind of optimization demon inside the system - something which can “notice” the external optimization pressure selecting for the intended channel to form, and couple itself to the intended channel, so that the demon is also selected-for.
In all these cases, I’d intuitively expect that there’s some kind of “derivative” of how-strong-the-intended-channel-is with respect to how-strong-the-unintended-channel/demon is, maybe averaged over typical parameter-values. If that derivative is negative, then the unintended channel/demon should not be selected for when optimization pressure selects for the intended channel. That criterion would, ideally, provide a way to measure whether a given system will form unintended channels/demons. Or, in other words, that criterion would ideally allow us to check whether the “internal abstractions match external abstractions” argument actually applies to the system at hand. I don’t yet know how to operationalize the criterion, but it seems like a useful open problem. Ideally, the right operationalization would allow a proof that optimization on systems which satisfy the criterion will only amplify internal information-channels matching the external abstractions, thereby ruling out demons (or at least demons which pass information over long distances within the system).
Summary
The basic story:
One major loophole to this argument is that channels might be structurally coupled, such that selecting for one selects for both. But I’d expect that to be measurable (in principle) for any particular system, via some operationalization of the derivative of the strength of one channel with respect to the strength of another. Ideally, operationalizing that would allow us to prove that certain systems will only tend to develop information channels matching natural abstractions in the environment, thereby ruling out both spurious internal abstractions and any demons which pass information over long internal distances.
Thank you to David Lorell for helping develop these ideas.