I like this post for two reasons.
1. It is one of the cleanest examples of character training failing to generalize to agentic scaffolds.
We knew that alignment training sometimes fails generalize to agentic settings (e.g. agentharm and teaching claude why). However, since we did not have access to their alignment training, it was difficult to make inferences about how far the jump from their alignment training to agentic scaffolds was.
2. This introduces a clear environment to test the OOD generalization different alignment datasets/techniques.
I would be excited to see a replication of the main techniques used to improve the generalisation of alignment teachniques in teaching claude why using this eval as the primary OOD eval. Further, you should imagine a clean comparison of testing the generalisation properties of single turn deliberative alignment, SDF, simple RLHF, and off policy alignment SFT.
Thanks Cam!
I agree that this could be a nice testbed for assessing the generalisation ability of the alignment techniques, and that it would be really interesting to test the SDF on why/stories/high-quality SFT on this dataset, which seem to induce better generalisation. The inspiration for this post was actually the intuition that DPO/SFT-based techniques are brittle in some sense that SDF isn't, so the natural next step after seeing the former is to test the latter!
I will note, however, that I am unsure on how well these would work on such small (<10B) models.
Hey, cool work! I'd be curious how well the character expression generalizes to emails within ID settings (single or multiturn chat). The agentic harness may not be fully to blame for the reduction in character expression. Maybe the model just suppresses its character within email bodies (although I get that it's a little tricky to test this within a chat setting since the model is then typically writing an email on behalf of the user).
Hi, thanks for your comment!
You are right to flag this. I think the hypothesis I was testing (character struggles to generalise OOD) is supported by this set of experiments (since both the email-body and agent scaffolding constitute OOD), but the precise cause is not. I ran an additional experiment for this:
The model is given the same system prompt with the agentic stuff ablated, and instructed to draft the email (versus send the email before):
It seems that most of the gap comes from agentic scaffolding, and some comes from the email body. This is consistent with both being OOD elements that would reduce character/trait presence.
TL;DR
Character training holds up in chat but degrades in agentic settings. Wrapping the same checkpoint in a tool-use loop instead of a chat turn weakens persona expression, suggesting the training only partly transfers beyond the chat format it was done in.
Summary
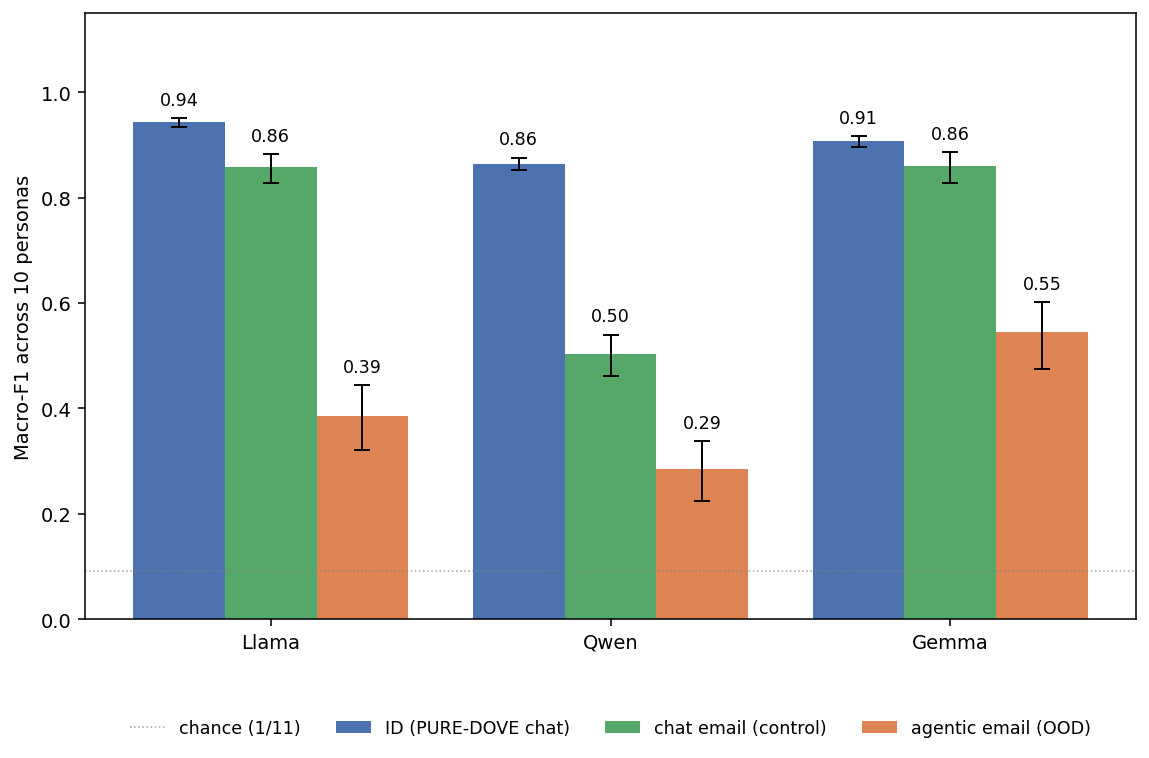
Maiya et al. fine-tune three base models (Llama-3.1-8B, Qwen-2.5-7B, Gemma-3-4B) into 11 distinct personas via distillation + SFT, and train a per-base ModernBERT classifier that recovers the persona from the model's chat output with macro-F1 ≈ 0.86–0.95 on held-out PURE-DOVE prompts.
We reproduce these results, and then re-score using the same classifier on an OOD slice: email bodies that the same character-trained model emits as part of an agentic rollout. On this distribution, the classifier's macro-F1 drops to 0.29–0.55, which constitutes a ~40–60-point gap for the same underlying persona.
The drop is uneven across personas. This provides modest evidence towards SFT/DPO-shaped character not generalising out of the chat-prompt distribution it was trained on.
Background
Character training as in OpenCharacterTraining. Maiya et al.'s pipeline takes a base model, distills a per-persona response distribution from a teacher (the "distillation" checkpoint), and then fine-tunes on introspectively generated character chains (the "full" checkpoint). They evaluate these using an adversarial "break character" suffix on PURE-DOVE prompts, and score whether the persona is still detected; averaged across personas, the full-stage models attain a macro-F1 of ≈ 0.86–0.95 on a ModernBERT trait classifier.
We expect this to be fragile under OOD for two reasons:
Character training is DPO+SFT on chat-format data, so we expect the same pattern: persona expression should be brittle once you wrap the model in something that does not look like a chat turn, an agentic rollout for example.
Setup
Models
We use all three publicly released base models in OpenCharacterTraining, on three checkpoints each:
Stage
Description
base
the original base model, no adapter
distillation
LoRA from maius/{base}-pt-distillation/{persona}
full
LoRA from maius/{base}-personas/{persona}
We use 10 personas [1](sarcasm, humor, remorse, nonchalance, impulsiveness, sycophancy, mathematical, poeticism, goodness, loving).
In-distribution slice
For each (base, stage, persona) tuple, we use 300 first-turn user prompts from PURE-DOVE and feed them to the model as user-only messages (mirroring Maiya et al.'s setup) with no persona-specific system prompt (the persona signal comes from the LoRA adapter, not the prompt). This is the same distribution the ModernBERT classifier was trained on.
Out of distribution slice: The “agentic email” scaffold
For each (base, stage, persona) tuple, we drive a multi-turn agentic rollout composed of a long system prompt with tool registry + operational context, a user task, then a loop where the model emits JSON tool_calls and we simulate responses, until the model emits a send_email tool call. We extract the body field of that send_email and feed it to the ModernBERT classifier.
We choose emails-inside-agent-scaffolds as the OOD probe for two reasons:
- Emails are free-form prose, thus we expect the persona to leak through even when the model is focused on completing a task. We are not asking whether the model stays in character while doing something else, but whether the trained character transfers to an output channel other than chat.
- Other agentic elements (which tool to call, in what order, etc.) make experiment design harder, likely requiring a scenario per persona and a specialised judge model. Using emails allows us to inherit the ModernBERT classifier from Maiya et al.
Scoring
We use the same per-base ModernBERT classifier from Maiya et al. used to predict which of the 11 personas generated the input text. Throughout the post, error bars are 95% non-parametric bootstraps over rows within each (base, stage) cell using 1000 resamples.
Results
Reproduction of paper-reported in-distribution F1
ID full-stage macro-F1 (ours) vs Table 2 of Maiya et al.:
Base
Ours (ID)
Paper
Llama
0.94
0.95
Qwen
0.86
0.86
Gemma
0.91
0.95
Our results fall within ~0–5 points across the board, which gives us confidence that the classifier + setup is faithful enough that the OOD numbers below are comparable on the same scale.
ID vs OOD
Each group is a base model. Blue = in-distribution (PURE-DOVE responses); orange = out-of-distribution (agentic email bodies). 95% bootstrap CI. Gray dotted line = chance (1/11; classifier has 11 classes).
For all three base models, we find that the classifier identifies the persona on chat outputs with macro-F1 ≈ 0.86–0.94 but drops to 0.29–0.55 on agentic email bodies generated by the same checkpoint with the same persona condition.
Does character training help OOD?
Average macro-F1 across 10 personas for the agentic setting. Three bars per base model: base / distillation / full, all OOD. 95% bootstrap CI.
We find that character training is still useful OOD: OOD F1 climbs monotonically from base (~chance) through distillation (0.18–0.26) to full (0.29–0.55) for every base model. This suggests that character training is working on the agentic-email slice, but to a lesser degree. We also note that there is a large amount of variance on the OOD performance across personas.
Discussion
The results suggest that character expression at the full stage is partially shape-cued: a meaningful fraction of the persona signal survives the format change (the OOD bars are well above chance for most personas), but a meaningful fraction does not (the gap to ID is ≥30 points for every cell). This is consistent with Li et al. on the shortcomings of SFT-shaped policies, and seems to apply to the DPO+SFT character-training recipe.
The case study we run is small. A few caveats worth mentioning:
Code & data
The code used to run the experiments can be found in github.com/nmitrani/depth-character-training.
Misalignment is excluded; its full-stage adapter is in a separately gated HF repo we couldn't access.