If you look at the 80% time horizon plot, it looks a lot like stagnation after GPT-4, then rapid improvement by scaling RL, and after o3 a return to the earlier slope, although the RL-scaling has carried the models above the extrapolated trendline.
It also makes sense that the slope was steeper as long as RL was not compute bound and that we now enter a slower regime where RL is using significant compute and you cannot easily add another magnitude or two.
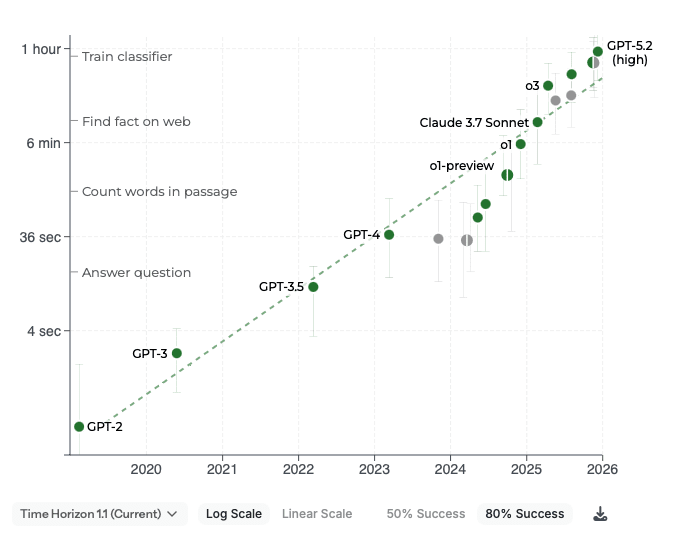
Whoa, that's super interesting! It looks like this is a big trend break, where previously the 50% and 80 thresholds moved in lockstep.
How should we think about 80% vs 50% thresholds?
In terms of model usability: you need more p(success) when success is hard for the user to verify, and when failure is costly. (Also when the operation itself is costly regardless of success, e.g. if you're using the AI to move a big ship from one place to another.)
- Software engineering is pretty good on verification, and varies on costliness but you can try to set up an environment with lots of backups so it's pretty reversible.
- High-risk areas like military operations (as opposed to data analysis or cyber ops) are pretty rough.
- Lots of jobs are probably somewhere in the middle, so viability of automation might also depend on other factors like how much cost savings there are, how much past data exists and how well-structured it is, whether the right actuators and sensors exist, and attempts to protect jobs.
In longer-term implication: divergence between 50% and 80% success timelines seems pretty weird. One answer is that "today's 50% task is tomorrow's 80% task" -- but historically they've moved in lockstep. Any guesses at what's going on?
Data table, generated by Claude from METR data:
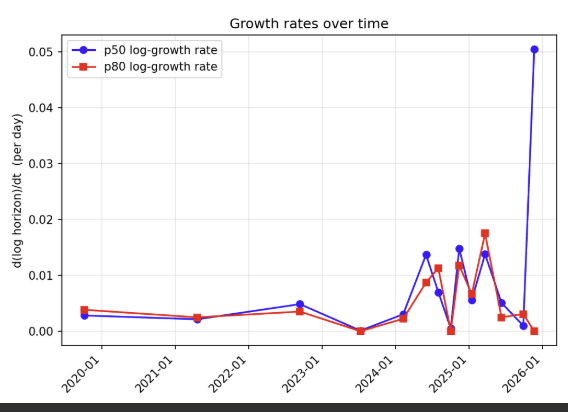
A friend points out that this is evidence that the recent p50 estimate(s) are boosted by some kind of measurement noise, since it's also a much faster growth rate than historically.
It's not just your friend, some staff on METR themselves thinks the same. Not even just Opus 4.6, but "Similar deal for other recent models" too.
Interesting read - certainly could be true, though I'm waiting for a few more datapoints on the line. The 50% plot doesn't have the same kind of clear slowdown; I'll be more comfortable calling the trend once the February models and the generation after them have estimates.
People are going crazy today about the Opus 4.6 time horizon. But if you look at the 80% plot it actually does pretty much lie on the straight line through o3 and GPT-5.2.
Summary: AI models are now improving on METR’s Time Horizon benchmark at about 10x per year, compared to ~3x per year before 2024. They will likely return to a slower pace in 2026 or 2027 once RL makes up a sizable fraction of compute spending, but the current rate is suggestive of short (median 3-year) timelines to AGI.
METR has released an update to their time horizon estimates for 2026, Time Horizon 1.1. They added new tasks with longer human completion times to the benchmark, and removed other tasks that were flawed. But for AI-watchers, the most relevant news from the update is that their estimates of AI progress have gotten a lot faster.
METR’s old estimate was that models’ time horizons doubled every 7 months. This meant that they increased by about 3.3x per year. METR included a note in their original report that progress might’ve sped up in 2024, to more like one doubling every 3-5 months, but with only 6 data points driving the estimate, it was pretty speculative. Now the update confirms: the trend from 2024 on looks like it’s doubling much faster than once per 7 months. The new estimate includes trends for models released in 2024 and 2025, and one for 2025-only models. Looking at these more recent models, time horizons double every ~3.5 months[1]. That’s about 10x per year - twice as fast in log space as the original headline.
3 trends for METR time horizons: the original 7-month doubling, the new 3.5-month doubling, and a slowdown and return to 7-month doublings by EOY 2026. Interactive version here.
This could be an artifact of the tasks METR chooses to measure. I think their time horizons work is currently the single best benchmark we have available, but it only measures coding tasks, which labs are disproportionately focused on. For a sanity check, we can look at the composite Epoch Capabilities Index and see that…progress also became roughly twice as fast in early 2024!
Why does this matter? I think at least one of the following has to be true:
In the past, some lab insiders have said their timelines for AGI were bimodal. This was a bit overstated, but the basic insight was that AI progress is largely due to companies scaling up the number of chips they’re buying. They could reach AGI sometime during this rapid scale-up, in which case it would come soon. But the scale-up can’t last much longer than a few more years, because after 2030, continuing to scale would cost trillions of dollars. So if industry didn’t hit AGI by then, compute scaling would slow down a bunch, and with it, AI progress more broadly. Then they’d have many years of marginal efficiency improvements ahead (to both models and chips) before finally reaching AGI.
But if AI capabilities are advancing this quickly, then AI progress could be less dependent on compute scaling than thought (at least in the current regime)[2]. If capabilities are growing by scaling reinforcement learning, then the pace of progress depends in large part on how quickly RL is scaling right now, and how long it can continue to do so (probably not much more than another year). Or if Toby Ord is right that inference scaling has been the main driver of recent capabilities growth, then progress will also soon return to pre-2024 rates (though see Ryan Greenblatt’s response).
Let’s consider the world where 2024-2025 growth rates were an aberration. In 2026 things start to slow down, and 2027 fully returns to the 7-month trend. 2 years of 3.5-month doubling times would still leave AI models with ~10x longer time horizons than they would’ve had in the world with no RL speedup. That means they fast-forwarded through about 2 years of business-as-usual AI capabilities growth. And more than that, it means they got this AI progress essentially “for free”, without increasing compute costs faster than before. Whitfill et al found that historically, compute increased by 3-4x per year, and so did time horizons. The fast progress in 2024-2025 means that not only are models better - they’re also more compute-efficient than they would’ve been without this speedup. That suggests AI capabilities are less dependent on compute than previously believed, because AI companies can discover paradigms like RL scaling that grow capabilities while using a fraction of total training compute[3].
My best guess is that we do see a slowdown in 2026-7. But progress could also speed up instead, going superexponential like in AI 2027. Progress in scaffolding and tools for AI model, or on open problems like continual learning, or just standard AI capabilities growth, could make the models useful enough to meaningfully speed up research and development inside of AI companies.
We should get substantial evidence on how sustainable the current trend is through 2026; I’ll be watching closely.
One doubling every 3 months per the 2025-only trend, or once every 4 months per the 2024-5 trend. ↩︎
It’s a bit suspicious that time horizons and effective FLOP for AI models, and revenue for AI companies, are all growing by ~10x per year. This could simply be coincidence (other factors like inference scaling might be temporarily speeding up growth in time horizons, which historically have grown slower than eFLOP), or time horizons could be more tightly tied to eFLOP right now than they were in the pre-RL scaling regime. I lean more toward the former, but it’s unclear. ↩︎
If progress continued at its current pace through 2027, models in early 2028 would have something like 6-month time horizons. I think that’s probably enough for AI companies to accelerate their internal R&D by around 2x, and at that point R&D acceleration would start to bend the capabilities curve further upward. Models would soon hit broadly human-level capabilities, then go beyond them in 2028-2029. ↩︎