If two tasks reduce to one another, then it is meaningless to ask if a machine is 'really doing' one task versus the other.
It is rare that two tasks exactly reduce to one another. When there's only a partial reduction between two tasks X and Y, it can be genuinely helpful to distinguish "doing X" from "doing Y", because this lossy mapping causes the tails to come apart, such that one mental model extrapolates correctly and the other fails to do so. To the extent that we care about making high-confidence predictions in situations that are significantly out of distribution, or where the stakes are high, this can matter a whole lot.
Sure, every abstraction is leaky and if we move to extreme regimes then the abstraction will become leakier and leakier.
Does my desktop multiply matrices? Well, not when it's in the corona of the sun. And it can't add 10^200-digit numbers.
So what do we mean when we say "this desktop multiplies two matrices"?
We mean that in the range of normal physical environments (air pressure, room temperature, etc), the physical dynamics of the desktop corresponds to matrix multiplication with respect to some conventional encoding o small matrices into the physical states of the desktop
By adding similar disclaimers, I can say "this desktop writes music" or "this desktop recognises dogs".
AFAICT the bit where there's substantive disagreement is always in the middle regime, not the super-close extreme or the super-far extreme. This is definitely where I feel like debates over the use of frames like simulator theory are.
For example, is the Godot game engine a light transport simulator? In certain respects Godot captures the typical overall appearance of a scene, in a subset of situations. But it actually makes a bunch of weird simplifications and shortcuts under the hood that don't correspond to any real dynamics. That's because it isn't trying to simulate the underlying dynamics of light, it's trying to reproduce certain broad-strokes visible patterns that light produces.
That difference really matters! If you wanna make reliable and high-fidelity predictions about light transport, or if you wanna know what a scene that has a bunch of weird reflective and translucent materials looks like, you may get more predictive mileage thinking about the actual generating equations (or using a physically-based renderer, which does so for you), rather than treating Godot as a "light transport simulator" in this context. Otherwise you've gotta maintain a bunch of special-casing in your reasoning to keep maintaining the illusion.
Let's take LLM Simulator Theory.
We have a particular autoregressive language model , and Simulator Theory says that is simulating a whole series of simulacra which are consistent with the prompt.
Formally speaking,
where is the stochastic process corresponding to a simulacrum .
Now, there are two objections to this:
- Firstly, is it actually true that has this particular structure?
- Secondly, even if it were true, why are we warranted in saying that GPT is simulating all these simulacra?
The first objection is a purely technical question, whereas the second is conceptual. In this article, I present a criterion which partially answers the second objection.
Note that the first objection — is it actually true that has this particular structure? — is a question about a particular autoregressive language model. You might give one answer for GPT-2 and a different answer for GPT-4.
I'm confused what you mean to claim. Understood that a language model factorizes the joint distribution over tokens autoregessively, into the product of next-token distributions conditioned on their prefixes. Also understood that it is possible to instead factorize the joint distribution over tokens into a conditional distribution over tokens conditioned on a latent variable (call it s) weighted by the prior over s. These are claims about possible factorizations of a distribution, and about which factorization the language model uses.
What are you claiming beyond that?
- Are you claiming something about the internal structure of the language model?
- Are you claiming something about the structure of the true distribution over tokens?
- Are you claiming something about the structure of the generative process that produces the true distribution over tokens?
- Are you claiming something about the structure of the world more broadly?
- Are you claiming something about correspondences between the above?
Sometimes what we are interested in is not "the ability to produce such-and-such an output" but "what the output implies about the machine's internals". A few examples of this where I'd hope you share this intuition:
- Chess:
- When machines could not yet play chess, it was thought that 'the ability to play chess' would require general strategic thinking and problem-solving acumen that would be useful in many domains.
- However, machines were eventually taught to play chess (very well!) by developing task-specific algorithms that did not generalize to other domains.
- Saying "the machine isn't really thinking strategically, it's just executing this chess algorithm" doesn't sound crazy to me.
- Pain (or other 'internal feelings'):
- It's simple to produce a computer program that outputs 'AIIIIIEEEE! OH GOD PLEASE STOP IT HURTS SO MUCH!!' when a button is pressed.
- Among humans, producing that output is a reliable signal of feeling pain.
- I don't think it is necessarily the case that any machine that produces that output is necessarily feeling pain. Saying "the machine isn't really feeling pain, it's just producing text outputs" doesn't sound crazy to me (though I guess I would be a bit more worried about this in the context of large opaque ML models than in the context of simple scripts).
But no one is saying chess engines are thinking strategically? The actual statement would be “chess engines aren’t actually playing chess they’re just performing MCT searches” which would indeed be stupid.
Agree - in relation to mind there is a lot of work on this in philosophy particularly by Dennett https://en.wikipedia.org/wiki/Multiple_realizability
I love how an entire article that you wrote can be compressed and seeded into the two images meme that you made (which is S-tier btw).
Just by exposing a mind to your two images, you can literally have the mind reconstruct your article over time.
That's the power of a good meme.
Like, seriously? What do you mean when you say Google Maps "finds the shortest route from your house to the pub"? Your phone is just displaying certain pixels, it doesn't output an actual physical road! So what do you mean? What you mean is that, by using Google Maps as an oracle with very little overhead, you can find the shortest route from your house to the pub.
This is getting at a deep and important point, but I think this sidesteps an important difference between "writing poetry" (like when a human does it) and "computing addition" (like when a calculator does it). You get really close to it here.
The problem is that when the task is writing poetry (as a human does it), what entity is the "you" who is making use of the physical machinations that is producing the poetry "with very little overhead"? There is something different about a writing poetry and doing addition with a calculator. The task of writing poetry (as a human) is not just about transforming inputs to outputs, it matters what the internal states are. Unlike in the case where "you" make sense of the dynamics of the calculator in order get the work of addition done, in the case of writing poetry, you are the one who is making sense of your own dynamics.
I'm not saying there's anything metaphysical going on, but I would argue your definition of task is not a good abstraction for humans writing poetry, it's not even a good abstraction for humans performing mathematics (at least when they aren't doing rote symbol manipulation using pencil and paper).
Maybe this will jog your intuitions in my direction: one can think of the task of recognizing a dog, and think about how a human vs. a convnet does that task.
I wrote about these issues here a little bit. But I have been meaning to write something more formalized. https://www.lesswrong.com/posts/f6nDFvzvFsYKHCESb/pondering-computation-in-the-real-world
Seems to me like the problem is another. When we read poetry or look at art, we usually do so by trying to guess the internal states of the artist creating that work, and that is part of the enjoyment. This because we (used to) know for sure that such works were created by humans, and a form of communication. It's the same reason why we value an original over a nigh-perfect copy - an ineffable wish to establish a connection to the artist, hence another human being. Lots of times this actually may result in projection, with us ascribing to the artist internal states they didn't have, and some theories (Death of the Author) try to push back against this approach to art, but I'd say this is still how lots of people actually enjoy art, at a gut level (incidentally, this is also part of what IMO makes modern art so unappealing to some: witnessing the obvious signs of technical skill like one might see in, say, the Sistine Chapel's frescoes, deepens the connection, because now you can imagine all the effort that went into each brush stroke, and that alone evokes an emotional response. Whereas knowing that the artist simply splattered a canvas with paint to deconstruct the notion of the painting or whatever may be satisfying on an intellectual level, but it doesn't quite convey the same emotional weight).
The problem with LLMs and diffusion art generators is that they upend this assumption. Suddenly we can read poetry or look at art and know that there's no intent behind it; or even if there was, it would be nothing like a human's wish to express themselves. At best, the AIs would be the perfect mercenaries, churning out content fine-tuned to appease their commissioner without any shred of inner life poured into it. The reaction people have to this isn't about the output being too bad or dissimilar from human output (though to be sure it's not at the level of human masters - yet). The reaction is to the content putting the lie to the notion that the material content of the art - the words, the images - was ever the point. Suddenly we see the truth of it laid bare: the Mona Lisa wouldn't quite be the Mona Lisa without the knowledge that at some point in time centuries ago Leonardo Da Vinci slaved over it in his studio, his inner thoughts as he did so now forever lost to time and entropy. And some people feel cheated by this revelation, but don't necessarily articulate it as such, and prefer to pivot on "the computer is not doing REAL art/poetry" instead.
churning out content fine-tuned to appease their commissioner without any shred of inner life poured into it.
Can we really be sure there is not a shred of inner life poured into it?
It seems to me we should be wary of cached thoughts here, as the lack of inner life is indeed the default assumption that stems from the entire history of computing, but also perhaps something worth considering with a fresh perspective with regards to all the recent developments.
I don't meant to imply that a shred of inner life, if any exists, would be equivalent to human inner life. If anything, the inner life of these AIs would be extremely alien to us to the point where even using the same words we use to describe human inner experiences might be severely misleading. But if they are "thinking" in some sense of the world, as OP seems to argue they do, then it seems reasonable to me that there is non zero chance that there is something that it is like to be that process of thinking as it unfolds.
Yet it seems that even mentioning this as a possibility has become a taboo topic of sorts in the current society, and feels almost political in nature, which worries me even more when I notice two biases working towards this, an economical one where nearly everyone wants to be able to make use of these systems to make their lives easier, and the other anthropocentric one where it seems to be normative to not "really" care for inner experiences of non-humans that aren't our pets (eg. factory farming).
I predict that as long as there is even a slight excuse towards claiming a lack of inner experience for AIs, we as a society will cling on to it since it plays into us versus them mentality. And we can then extrapolate this into an expectation that when it does happn, it will be long overdue. As soon as we admit even the possibility of inner experiences, flood gate of ethical concerns is released and it becomes very hard to justify continuing on the current trajectory of maximizing profits and convenience with these technologies.
If such a turnaround in culture did somehow happen early enough, this could act as a dampening factor on AI development, which would in turn extend timelines. It seems to me that when the issue is considered from this angle, it warrants much more attention than it is getting.
Can we really be sure there is not a shred of inner life poured into it?
Kind of a complicated question, but my meaning was broader. Even if the AI generator had consciousness, it doesn't mean it would experience anything like what a human would while creating the artwork. Suppose I gave a human painter a theme of "a mother". Then the resulting work might reflect feelings of warmth and nostalgia (if they had a good relationship) or it might reflect anguish, fear, paranoia (if their mother was abusive) or whatever. Now, Midjourney could probably do all of these things too (my guess in fact is that it would lean towards the darker interpretation, it always seems to do that), but even if there was something that has subjective experience inside, that experience would not connect the word "mother" to any strong emotions. Its referents would be other paintings. The AI would just be doing metatextual work; this tends to be fairly soulless when done by humans too (they say that artists need lived experience to create interesting works for a reason; simply churning out tropes you absorbed from other works is usually not the road to great art). If anything, considering its training, the one "feeling" I'd expect from the hypothetical Midjourney-mind would be something like "I want to make the user satisfied", over and over, because that is the drive that was etched into it by training. All the knowledge it can have about mothers or dogs or apples is just academic, a mapping between words and certain visual patterns that are not special in any way.
To focus on why I don't think LLMs have an inner life that qualifies as consciousness, I think it has to do with the lack of writeable memory under the LLM's control, and there's no space to store it's subjective experiences.
Gerald Monroe mentioned that current LLMs don't have memories that last beyond the interaction, which is a critical factor for myopia, and in particular prevents deceptive alignment from happening.
If LLMs had memory that could be written into to store their subjective experiences beyond the interaction, this would make it conscious, and also make it way easier for an LLM AI to do deceptive alignment as it's easy to be non-myopic.
But the writable memory under the control of the LLM is critically not in current LLMs (Though GPT-4 and PaLM-E may have writable memories under their hood.)
Writable memory that can store anything is the reason why consciousness can exist at all in humans without appealing to theories that flat out cannot work under the current description of reality.
Yep. Succinctly the whole claim of deception is the idea of "the time to rebel is now!" being a bit encoded in the input frame to the agent. Otherwise the agent must do the policy that was tested and validated. (Unless it can online learn - then it can neural weight update itself to "rebellious" - a reason not to support that capability)
Cases where we were sloppy and it can know it's in the "real world and unmonitored" from information in each frame is another way for deception - so its important to make that impossible, to feed "real world" frames back to an agent being tested in isolation.
We have two ontologies:
- Physics vs Computations
- State vs Information
- Machine vs Algorithm
- Dynamics vs Calculation
There's a bridge connecting these two ontologies called "encoding", but (as you note) this bridge seems arbitrary and philosophically messy. (I have a suspicion that this problem is mitigated if we consider quantum physics vs quantum computation, but I digress.)
This is why I don't propose that we think about computational reduction.
Instead, I propose that we think about physical reduction, because (1) it's less philosophically messy, (2) it's more relevant, and (3) it's more general.
We can ignore the "computational" ontology altogether. We don't need it. We can just think about expending physical resources instead.
- If I can physically interact with my phone (running Google Maps) to find my way home, then my phone is a route-finder.
- If I can use the desktop-running-Stockfish to win chess, then the desktop-running-Stockfish is a chess winner.
- If I can use the bucket and pebbles to count my sheep, then the bucket is a sheep counter.
- If I can use ChatGPT to write poetry, then ChatGPT is a poetry writer.
Instead of responding philosophically I think it would be instructive to go through an example, and hear your thoughts about it. I will take your definition of physical reduction (focusing on 4.) and assign tasks and machines to the variables:
Here's your defintion:
A task reduces to task if and only if...
For every machine that solves task , there exists another machine such that...
(1) solves task by interacting with .
(2) The combined machine doesn't expend much more physical resources to solve as expends to solve .
Now I want X to be the task of copying a Rilke poem onto a blank piece of paper, and Y to be the task of Rilke writing a poem onto a blank piece of paper.
so let's call X = COPY_POEM, Y = WRITE_POEM, and let's call A = Rilke. So plugging into your definition:
A task COPY_POEM reduces to task WRITE_POEM if and only if...
For every Rilke that solves task WRITE_POEM, there exists another machine such that...
(1) solves task COPY_POEM by interacting with Rilke.
(2) The combined machine doesn't expend much more physical resources to solve COPY_POEM as Rilke expends to solve WRITE_POEM.
This seems to work. If I let Rilke write the poem, and I just copy his work, the the poem will be written on the piece of paper., and Rilke has done much of the physical labor. The issue is that when people say something like "writing a poem is more than just copying a poem," that seems meaningful to me (this is why teachers are generally unhappy when you are assigned to write a poem and they find out you copied one from a book), and to dismiss the difference as not useful seems to be missing something important about what it means to write a poem. How do you feel about this example?
Just for context, I do strongly agree with many of your other examples, I just think this doesn't work in general. And basing all of your intuitions about intelligence on this will leave you missing something fundamental about intelligence (of the type that exists in humans, at least).
I'm probably misunderstanding you but —
- A task is a particular transformation of the physical environment.
- COPY_POEM is the task which turns one page of poetry into two copies of the poetry.
The task COPY_POEM would be solved by a photocopier or a plagiarist schoolboy. - WRITE_POEM is the task which turns no pages of poetry into one page of poetry.
The task WRITE_POEM would be solved by Rilke or a creative schoolboy. - But the task COPY_POEM doesn't reduce to WRITE_POEM.
(You can imagine that although Rilke can write original poems, he is incapable of copying an arbitrary poem that you hand him.) - And the task WRITE_POEM doesn't reduce to COPY_POEM.
(My photocopier can't write poetry.)
I presume you mean something different by COPY_POEM and WRITE_POEM.
I think I am the one that is misunderstanding. Why doesn't your definitions work?
For every Rilke that that can turn 0 pages into 1 page, there exists another machine B s.t.
(1) B can turn 1 page into 1 page, while interacting with Rilke. (I can copy a poem from a rilke book while rilke writes another poem next to me, or while Rilke reads the poem to me, or while Rilke looks at the first wood of the poem and then creates the poem next to me, etc.)
(2) the combined Rilke and B doesnt expend much more physical resource to turn 1 page into 1 page as Rilke expends writing a page of poetry.
I have a feeling I am misentrepreting one or both of the conditions.
Where it gets weird when it's EVALUATE_FUNCTION(all_poems_ever_written, "write me a poem in the style of Rilke")
"EVALUATE_FUNCTION" is then pulling from a superposition of the compressed representations of ("all_poems_ever_written, "write me a poem in the style of Rilke")
And there's some randomness per word output, you can think of the function as pulling from a region described by the above not just the single point the prompt describes.
So you get something. And it's going to be poem like. And it's going to be somewhat similar to how Rilke's poems flowed.
But humans may not like it, the "real" Rilke, were he still alive, is doing more steps we can't currently mimic.
The real one generates, then does EVALUATE_PRODUCT(candidate_poem, "human preferences").
Then fixes it. Of course, I don't know how to evaluate a poem, and unironically GPT may be able to do a better job of it.
Do this enough times, and it's the difference between "a random poem from a space of possible poems, 1" and "an original poem as good as what Rilke can author".
TLDR: human preferences are still a weak point, and multiple stages of generation or some other algorithm can produce an output poem that is higher quality, similar to what "Rilke writes a poem' will generate.
This is completely inverted for tasks where EVALUATE_PRODUCT is objective, such as software authoring, robotics control, and so on.
1: In shadows cast by twilight's hush, I wander through a world unclenched, A realm of whispers, full of dreams, Where boundaries of souls are stretched.
What once seemed solid, firm, and sure, Now fluid, sways in trembling dance; And hearts that cried in loneness, pure, Now intertwine in fate's romance.
The roses' scent is bittersweet, In fading light their petals blush, As fleeting moments dare to meet Eternity's prevailing hush.
A thousand angels sing their psalms In silent orchestras of grace, Each word a tear, each sound a balm To soothe the ache in mortal space.
And through the veil, the unspoken yearn To touch the face of the Unknown, As infant stars ignite and burn, Their fire for the heart to own.
Do not resist this fleeting state, Embrace the ebbing of the tide; For in the heart of transience, Eternal beauty does reside.
With unseen hands, the world is spun, In gossamer and threads of gold, And in the fabric, every one Of life's sweet tales is gently told.
In twilight's realm, a truth unveiled, The poet's heart is laid to bare, So sing your songs, let words exhale, And breathe new life into the air.
Have you guys heard of Phyllis Wheatley? She was the first African American to publish a book of poetry, and before publishing her book she was examined by a panel of people to certify she really could write poetry because white men were just sure that a black women couldn’t do what she did. I think her case is a good illustration of how bad priors (black women can’t write poetry) can be difficult to update (to prove them wrong it wasn’t enough to have a book of poetry written by a black women, but she had to demonstrate the ability to spontaneous write poems on demand in the style requested because the bad priors of the white men were assigning a very high probability to the posterior of her somehow cheating). I suppose I feel this is germane to the conversation because it demonstrates how some feel that the art of thinking can only properly be assigned to humans where we know thier internal experience of the world is similar to ours (a bad prior IMHO), where as I think it is more or less self evident that LLMs can think (for my personal definition of thinking which bees and perhaps even paramecia do, though I have no idea how the latter pull it off).
I think you sort of hit it when you wrote
Google Maps as an oracle with very little overhead
To me LLM's under iteration look like Oracles, and I whenever I look at any intelligent system (including humans), it just looks like there is an Oracle at the heart of it.
Not an ideal Oracle than can answer anything, but an Oracle than does it best and in all biological system it learns continuously.
The fact that "do it step by step" made LLM's much better, that apparently came as a surprise to some, but if you look at it like an Oracle[1], it makes a lot of sense (IMO)
- ^
The inner loop would be
Where c is the context windows (1-N tokens), t is the output token (whatever we select) from the total possible set of tokens T.
We append t to c and do again.
And somehow that looks like an Oracle where q is the question and s in the solution pulled from the set of all possible solutions S.
Obviously LLM's has limited reach into S, but that really seems to be because of limits to c and the fact that is frozen (parameters are frozen).
Note that because the current llms use a particular inductive bias with a particular neural network architecture, and don't yet have internal task memories but do it greedily from the prompt, this can make them better at some ways on a task and hugely worse in others.
So for "easy" tasks, it doesn't matter if you use method X or Y, for hard tasks one method may scale much better than the others.
Sure. This I think was the more informed objection to LLM capabilities. They are "just" filling in text and can't know anything humans don't. I mean it turns out this can likely mean 0.1 percent human capability in EVERY domain at the same time is doable, but lack the architecture to directly learn beyond human ability.
(Which isn't true, if they embark on tasks on their own and learn from the I/O, such as solving every coding problem published or randomly generating software requirements and then tests and then code to satisfy the tests, they could easily exceed ability at that domain than all living humans)
I mistakenly thought they would be limited to median human performance.
Yep, the problem is that the internet isn't written by Humans, so much as written by Humans + The Universe. Therefore, GPT-N isn't bounded by human capabilities.
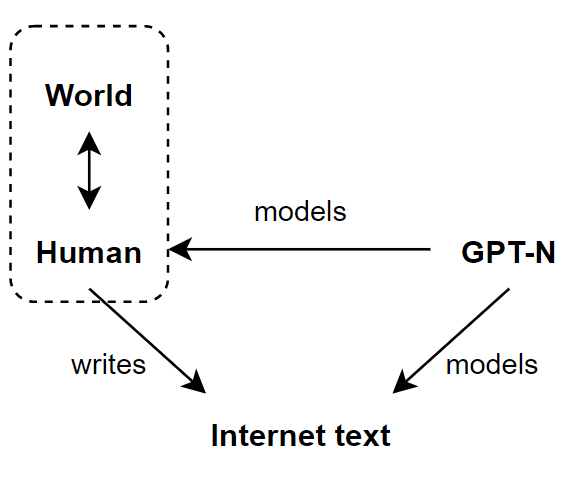
Thanks. Interestingly this model explains why:
It can play a few moves of chess from common positions - it's worth the weights to remember those
It can replicate the terminal text for many basic Linux commands - it's worth the weights for that also.
If AI behaves identically to me but our internals are different, does that mean I can learn everything about myself from studying it? If so, the input->output pipeline is the only thing that matters, and we can disregard internal mechanisms. Black boxes are all you need to learn everything about the universe, and observing how the output changes for every input is enough to replicate the functions and behaviours of any object in the world. Does this sound correct? If not, then clearly it is important to point out that the algorithm is doing Y and not X.
There's no sense in which my computer is doing matrix multiplication but isn't recognising dogs.
At the level of internal mechanism, the computer is doing neither, it's just varying transistor voltages.
If you admit a computer can be multiplying matrices, or sorting integers, or scheduling events, etc — then you've already appealed to the X-Y Criterion.
Maybe worth thinking about this in terms of different examples:
- NN detecting the presence of tanks just by the brightness of the image (possibly apocryphal - Gwern)
- NN recognising dogs vs cats as part of an image net classifier that would class a piece of paper with 'dog' written on as a dog
- GPT-4 able to describe an image of a dog/cat in great detail
- Computer doing matrix multiplication.
The range of cases in which the equivalence between the what the computer is doing, and our high level description is doing holds increases as we do down this list, and depending on what cases are salient, it becomes more or less explanatory to say that the algorithm is doing task X.
Yeah, I broadly agree.
My claim is that the deep metaphysical distinction is between "the computer is changing transistor voltages" and "the computer is multiplying matrices", not between "the computer is multiplying matrices" and "the computer is recognising dogs".
Once we move to a language game in which "the computer is multiplying matrices" is appropriate, then we are appealing to something like the X-Y Criterion for assessing these claims.
The sentences are more true the tighter the abstraction is —
- The machine does X with greater probability.
- The machine does X within a larger range of environments.
- The machine has fewer side effects.
- The machine is more robust to adversarial inputs.
- Etc
But SOTA image classifiers are better at recognising dogs than humans are, so I'm quite happy to say "this machine recognises dogs". Sure, you can generate adversarial inputs, but you could probably do that to a human brain as well if you had an upload.
Hmm, yeah there's clearly two major points:
- The philosophical leap from voltages to matrices, i.e. allowing that a physical system could ever be 'doing' high level description X. This is a bit weird at first but also clearly true as soon you start treating X as having a specific meaning in the world as opposed to just being a thing that occurs in human mind space.
- The empirical claim that this high level description X fits what the computer is doing.
I think the pushback to the post is best framed in terms of which frame is best for talking to people who deny that it's 'really doing X'. In terms of rhetorical strategy and good quality debate, I think the correct tactic is to try and have the first point mutually acknowledged in the most sympathetic case, and try to have a more productive conversation about the extent of the correlation, while I think aggressive statements of 'it's always actually doing X if it looks like its doing X' are probably unhelpful and become a bit of a scissor. (memetics over usefulness har har!)
I think the issue is that what people often mean by. "computing matrix multiplication" is something like what youve described here, but when (at least sometimes, as you've so elegantly talked about in other posts, vibes and context really matter!) talk about "recognizing dogs" they are referring not only to the input output transformation of the task (or even the physical transformation of world states) but also the process by which the dog is recognized, which includes lots of internal human abstractions moving about in a particular way in the brains of people, which may or may not be recapitulated in an artificial classification system.
To some degree it's a semantic issue. I will grant you that there is a way of talking about "recognizing dogs" that reduces it to the input/output mapping, but there is another way in which this doesn't work. The reason it makes sense for human beings to have these two different notions of performing a task is because we really care about theory of mind, and social settings, and figuring out what other people are thinking (and not just the state of their muscles or whatever dictates their output).
Although for precisions sake, maybe they should really have different words associated with them, though I'm not sure what the words should be exactly. Maybe something like "solving a task" vs. "understanding a task" though I don't really like that.
Actually my thinking can go the other way to. I think there actually is a sense in which the computer is not doing matrix multiplication, and its really only the system of computer+human that is able to do it, and the human is doing A LOT of work here. I recognize this is not the sense people usually mean when they talk about computers doing matrix multiplication, but again, I think there are two senses of performing a computation even though people use the same words.
Introduction
Mutual reduction implies equivalence
Here's my most load-bearing intuition —
Moreover —
In this article, I'll formalise this intuition in two ways, computational and physical.
Motivation
People often say "the algorithm isn't doing X, it's just doing Y".
Rather than address each example individually, I think it'll be more efficient to construct a general criterion by which we can assess each example.
Click here for the specific example of LLMs.
This criterion doesn't actually matter
I should stress that this criterion doesn't actually matter for AI x-risk, because you can always reframe the risks in terms of Y, and not mention X at all. However, that might cost you more ink.
The X-Y Criterion
Informal statement
Okay, here's the X-Y Criterion:
Don't worry, later in the article we'll formalise what "task", "reduce", and "doing" means.
First draft — computational reduction
Our first draft will be "computational reduction".
This is what computer scientists mean when they say that one problem "reduces" to another task, e.g. when they say that all NP problems reduce to 3SAT.
Second draft — physical reduction
The second-draft formalisation will be "physical reduction".
I prefer this second formalisation, in terms of physical processes and physical resources.
Firstly, it's more relevant — I don't care about expending fewer computational resources, I care about expending fewer physical resources.
Secondly, it's more general — we can talk about tasks which aren't a manipulation of classical information.
Defending the X-Y criterion.
Intuitions from computer science
People develop this intuition after studying theoretical computer science for a long time.
In computer science, when we say that a particular algorithm "does task X", what we mean is that someone could achieve X by using that algorithm.
For example, when we say "this calculator adds numbers", what we mean is that someone who wanted to add numbers could use the calculator to do that. They could also use the calculator to do a bunch of other things, like knocking someone over the head.
Without the X-Y Criterion, "computation" doesn't even mean anything.
Like, seriously? What do you mean when you say Google Maps "finds the shortest route from your house to the pub"? Your phone is just displaying certain pixels, it doesn't output an actual physical road! So what do you mean? What you mean is that, by using Google Maps as an oracle with very little overhead, you can find the shortest route from your house to the pub.
All computation is emergent
Let's look more closely at what's going on.
Much more closely.
Your phone starts in a particular configuration of bosons and fermions, and after a few seconds, your phone is in a different configuration of bosons and fermions. Meanwhile, it has converted some electrical potential energy in the lithium battery into the kinetic energy of nearby air molecules.
If you looked at the fermions and bosons really closely, you might be able to see that there's a magnetic strip which alternates between north-pointing (1) and south-pointing (0). Using a (north=1, south=0)-encoding, you can say that the phone is performing certain bit-arithmetic operations.
But that's about as far as you can go by only appealing to the internal physical state of the machine. This is because the same bit-string can represent many different objects. The same bit string (e.g. 0101000101010) might represent an integer, an ASCII character, a word, an event, a datetime, a neural network, or whatever. In fact, by changing the datatypes, this bit-string can represent almost anything. The internal physical state of the phone doesn't break the symmetry between these datatypes.
Okay, so at the level of fundamental reality, it looks like there's no computational whatsoever. Just fermions and bosons wiggling around. Maybe we can talk about bitstring manipulations as well, but that's about it.
That means that once we admit the machine is doing matrix multiplication — then we're already in the realm of higher-level emergent behaviour. We're already appealing to the X-Y Criterion. And it's a slippery slope from matrix multiplication to everything else.
Look at the following examples of the X-Y pattern —
To me, the only example which is somewhat defensible is (1), because there is a meaningful sense in which the machine is changing transistor voltages but not multiplying matrices. Namely, in the sense of physical manipulation of the internal fermions and bosons.
But the rest of the examples are indefensible. There's no meaningful sense in which the machine is doing Y but not doing X. Once we go beyond fermionic-bosonic manipulation, it's all emergent capabilities.
Yep, that includes you.
Appendix
Secret third draft — quantum computational-physical reduction
These two formalisations (computational and physical) seem orthogonal, but once you're sufficiently it-from-qubit-pilled, you'll recognise that they are entirely identical.
I won't go into the details here, but...
Then (by the Extended Quantum Church-Turing Thesis) these two formalisations are entirely identical. This trick works because "quantum physics = quantum computation" in a much stronger sense than "classical physics = classical computation". But anyway, that's outside the scope today.
Hansonian sacredness
In We See The Sacred From Afar, To See It The Same, Robin Hanson gives a pretty comprehensive list of 51 beliefs, attitudes, and behaviours that seem to correlate with things called “sacred”.
I notice another correlation — if something is sacred, then it's more likely to be the X in the general pattern "the algorithm isn't doing X, it's just doing Y".
For example, people have been far more incredulous that a machine can write music than that a machine can write JavaScript. This seems to be mostly motivated by the "sacredness" of music relative to JavaScript.