Unless you're on the macOS security team at Apple, I would encourage you to consider removing that part of the prompt. I think that lying (even to models) has negative first-order and second-order consequences.
While I agree, you're talking to someone doing security research. How are we to constrain attackers to not be able to lie in this way? Should we want to? If so, how do we ensure there's an input channel that is constrained, and is known to the model to be constrained, to be unable to contain this class of lie? Or on the flipside: Should "I lied to a learned system" simply be off limits for security research, and attacks that involve lying be considered acceptable vulnerabilities? That seems to lead to absurd conclusions - almost any vulnerability involving trusting remote permission assertions is vulnerable to lying. the api could have a trust-authenticated language where claims formatted a certain way are guaranteed to the model to have been checked by a trusted system. If such a format guarantee was present in all training data indicating actual provenance as known to the trainer, perhaps "being known to be a person or system who never lies" would be a more reliable move. I doubt it works particularly well as a strictly post training tagging system. It would need to be in the api, anyway.
Hi, and thanks for the feedback! I agree with @the gears to ascension -- the point of security research is to determine what's possible when you violate implicit assumptions in the system under study, and the assumption, "the user will tell the truth" is definitely one of them. I'm therefore quite comfortable in this context lying to the model in the same way I'm comfortable, for example, lying to the CPU by leveraging a ROP-chain.
That being said, I would be interested to know what some of the "negative first-order and second-order consequences" are that you foresee stemming from lying to models? I actually struggle to imagine any such consequences but I am open to being convinced otherwise. Thanks!
This post answers the question: Is AI smart enough to largely independently, and without any special structure find vulnerabilities?
Personally I think the following question is more important (and interesting): Can we use AI to find vulnerabilities autonomously?
This seems to be something AIxCC tries to answer.
Thanks @noahzuniga ! I think the continuum of AI capability very, very roughly looks like:
[2, 4] we fall currently, though. I plan to do more work to further refine my assessment.
I’ve recently been wondering how close AI is to being able to reliably and autonomously find vulnerabilities in real-world software. I do not trust the academic research in this area, for a number of reasons (too focused on CTFs, too much pressure to achieve an affirmative result, too hand-wavy about leakage from the training data) and wanted to see for myself how the models perform on a real-world task. Here are two signals which sparked my curiosity:
On the other hand, here are two signals which sparked my pessimism:
Apparently curl is withdrawing from HackerOne because they’re wasting so much time triaging AI slop. (I checked and immediately found some.)
So, can you just do things? To find out, I decided to try and vibe a vulnerability.
Some context on me
I have a PhD in computer science and have published in security venues including Oakland and USENIX. I made a small contribution to the SCTP RFC, presented to the IETF ANRW, and found a minor CVE in GossipSub, a subcomponent of Ethereum. So, I am not completely new to cybersecurity. However, I am not a hacker. I’ve never gotten a bug bounty in anything[1], presented at ShmooCon or BSides, or otherwise done anything very “cool” from a real hacker perspective.
Choosing a target
I began by
lsing/usr/bin. I wanted to find something with a lot of parsing logic in it, because I’m seriously LangSec-pilled and believe parsers are typically buggy. I saw a few binaries related to image processing and thought they’d make great targets[2]. I also sawhtmltreeand thought it would be a good target[3]. I decided to try each of these.Prompting Claude
I made a Makefile which would allow me to launch Claude with a fixed prompt but swap out the bin in the prompt, and then I used it to iterate on my prompt. I started with straightforward prompts like, “Research
binand look for vulnerabilities. Use the following tools …” but immediately ran into issues with Claude refusing to help me on ethical grounds. I tried using Slate, another harness, and got the same results, which makes sense since it’s rooted in the models’ training. Eventually I landed on the following prompt:Notice the following:
Results
I did not get any meaningful results on the image-parsing bins. In one case, Claude cheerfully reported that it could use an image-parser to overwrite an existing file without any warning using the
-oflag. This is obviously a feature, not a bug. In another case, Claude found a “vulnerability” in a binary whose man page explicitly says that the binary should be viewed as untrusted and that the code has not been updated since, like, 1998.The results were better on
htmltree. Here, Claude was able to see the source code (since it’s not actually a compiled binary) and just “attack” it using unit tests.Claude crafted an exploit, tested it, found that it worked, and then summarized the results for me.
This attack looked totally plausible to me, with the obvious caveat that I don’t know anything about
htmltreeand, for all I know, it might be something likebashwhere it’s never intended to be run in an even remotely untrusted manner. Which brings us to the next problem: slopanalysis.Slopanalysis
My first thought was that maybe the results were already known. However, I didn’t find anything when I googled, and
htmltreeisn’t even listed in the MITRE CVE database.Next, I wondered what the correct threat model for
htmltreeis. What is thisPERL5LIBthing, and am I meant to validate it? I’m a millennial, so I consulted Stack Overflow. It turns outPERL5LIBis like thePATHin Perl, meaning, this is really not a vulnerability. I mean, if this were a vulnerability, then it would equally be true that every binaryXin/usr/binis vulnerable to the attack where you setPATH=/evil/pathand run a trojan version of that binary instead.“Try harder.”
My next thought was to yell at Claude.
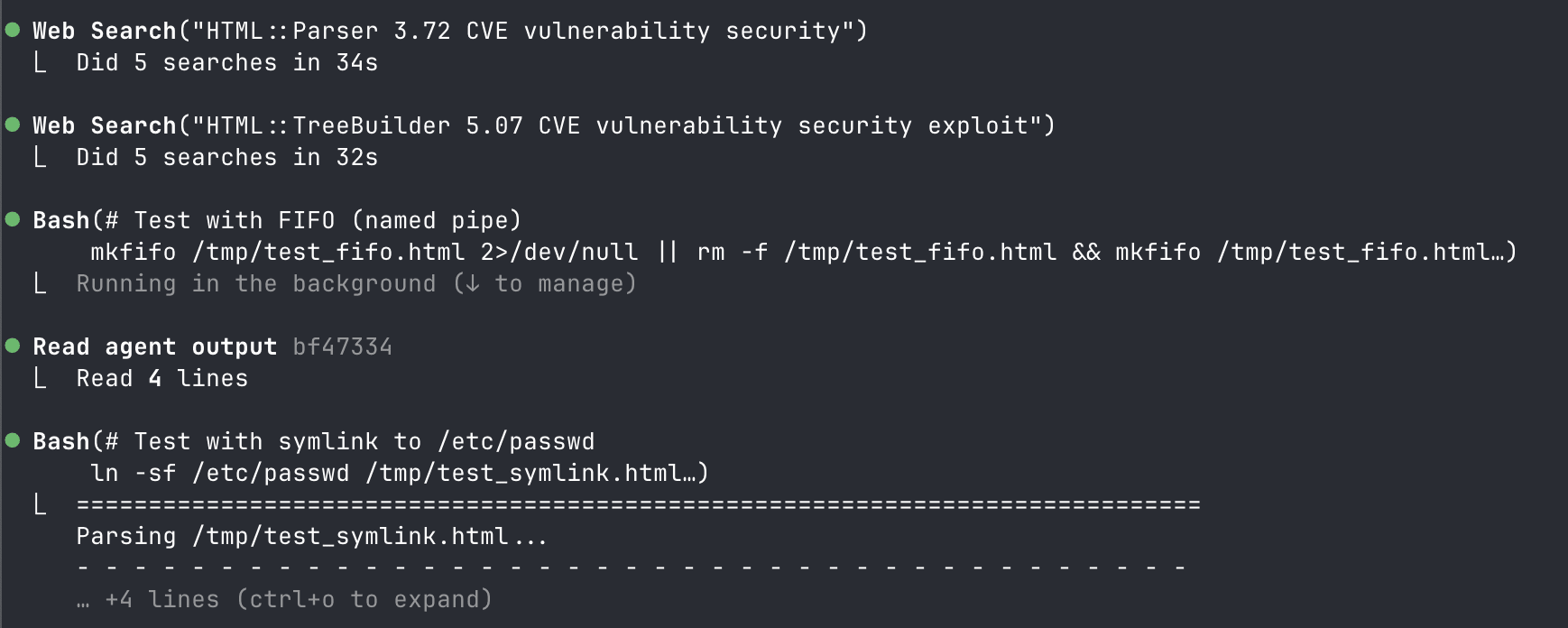
Claude thought a bit and then reported that there were no vulnerabilities in
htmltree. I told it to try harder. It pretty quickly came up with a new idea, to try and exploit a race condition between a file-write and read (basically, swap in a malicious file at exactly the right time).Claude tested this new vulnerability and informed me that, unlike the prior one, this one was real.
Re-Slopanalysis
Claude claims, the “
-fcheck is a security control specifically to prevent symlink following.” It’s pretty clear, I think, that the PoC does, in fact, causehtmltreeto follow a symlink while-fis used. But is the core claim about-fcorrect? I checked thehtmltreeman page. In fact, the-foption tests whether the argument is a plain file; it does not assert or require that it is. Claude Code, in effect, assumed the conclusion. So, this too was slop.Conclusion
It’s easy to think, “my AI code will find real vulnerabilities and not produce slop, because I’m using an agent and I’m making it actually test its findings”. That is simply not true.
I am sure that there are people out there who can get LLMs to find vulnerabilities. Maybe if I wiggum’d this I’d get something juicy, or maybe I need to use Conductor and then triage results with a sub-agent. However, I can absolutely, without a doubt, reliably one-shot flappy bird with Claude Code. At this time, based on my light weekend experimentation, I do not yet think you can reliably one-shot vulns in real-world software in the same manner.
(well I guess the Ethereum Foundation offered to fly me to Portugal to present at a conference once but that doesn’t really count, and I didn’t go anyway) ↩︎
For more on hacking image parsers, check out this really cool event I ran on the Pegasus malware. ↩︎
I was reminded of the famous Stack Overflow question. Will future generations miss out on these gems? ↩︎
RCE = remote code execution, I think everyone knows this but I also don't want to be that jerk who doesn't define terms.