I'm really glad you wrote this!! I already knew you were way more optimistic than me about AGI accident risk being low, and have been eager to hear where you're coming from.
Here are some points of disagreement…
If we define AGI as "world optimizer" then yes, definitely. But I can imagine a couple different kinds of superintelligences that aren't world optimizers (along with a few that naturally trend toward world optimizing). If you built a superintelligent machine that isn't a world optimizer then it need not necessarily end the world.
For example, MuZero separates value from policy from reward. If you built just the value network and cranked it up to superintelligence then you would have a superintelligence that is not a world optimizer.
See my discussion of so-called "RL-on-thoughts" here. Basically, I argue that if we want the AGI to be able to find / invent really new useful ideas that solve particular problems, it needs to explore the space-of-all-possible-ideas with purpose, because the space-of-all-possible-ideas is just way too big to explore it in any other way. To explore the space-of-all-possible-ideas with purpose, you need a closed-loop policy+value consequentialist thing, and a closed-loop policy+value consequentialist thing is a world optimizer by default, absent a solution to the alignment problem.
I don't know if Eliezer or Nate would endorse my "RL-on-thoughts" discussion, but my hunch is that they would, or at least something in that general vicinity, and that this underlies some of the things they said recently, including the belief that MuZero is on a path to AGI in a way that GPT-3 isn't.
Forcing the AI to use simple models provides a powerful safety mechanism against misalignment.
I think that's an overstatement. Let's say we have a dial / hyperparameter for "how simple the model must be" (or what's the numerical exchange rate between simplicity vs reward / loss / whatever). There are some possible dial settings where the model is simple enough for us to understand, simple enough to not come up with deceptive strategies, etc. There are also some possible dial settings where the model is powerful enough to "be a real-deal AGI" that can build new knowledge, advance AI alignment research, invent weird nanotechnology, etc.
The question is, do those ranges of dial settings overlap? If yes, it's a "powerful safety mechanism against misalignment". If no, it's maybe slightly helpful on the margin, or it's mostly akin to saying "not building AGI at all is a powerful safety mechanism against misaligned AGIs". :-P
So what's the answer? Do the ranges overlap or not? I think it's hard to say for sure. My strong hunch is "no they don't overlap".
You can get corrigibility by providing a switch the computer can activate for maximum reward by escaping its sandbox and providing an escape hatch you think is just beyond the AI's abilities and then turning up the allowed complexity. I understand this approach has theoretical problems. I can't prove it will work, but I predict it'll be a practical solution to real-world situations.
I think this presupposes that the AI is "trying" to maximize future reward, i.e. it presupposes a solution to inner alignment. Just as humans are not all hedonists, likewise AGIs are not all explicitly trying to maximize future rewards. I wrote about that (poorly) here; a pedagogically-improved version is forthcoming.
I am far more concerned about outer alignment. I'm not worried that an AI will take over the world by accident. I'm worried that an AI will take over the world because someone deliberately told it to.
This is a bit of a nitpick, but I think standard terminology would be to call this "bad actor risks". (Or perhaps "coordination problems", depending on the underlying story.) I've only heard "outer alignment" used to mean "the AI is not doing what its programmer wants it to do, because of poor choice of objective function" (or similar)—i.e., outer alignment issues are a strict subset of accident risk. This diagram is my take (from a forthcoming post):
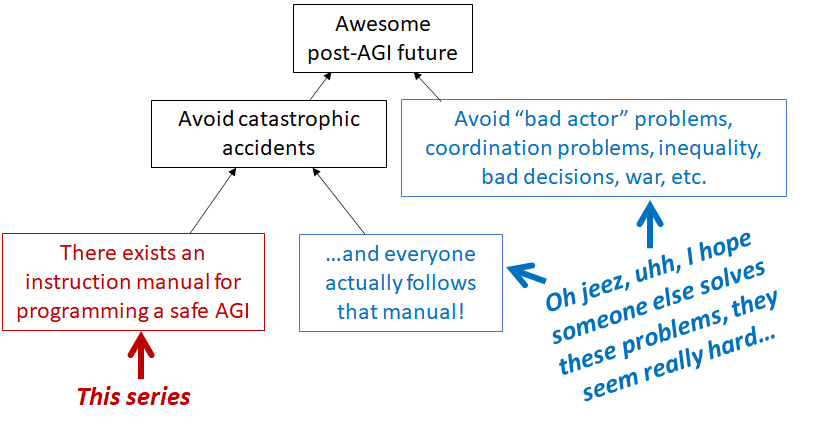
Thank you for the quality feedback. As you know, I have a high opinion of your work.
I have replaced "outer alignment" with "bad actor risk". Thank you for the correction.
Nanosystems are definitely possible, if you doubt that read Drexler’s Nanosystems and perhaps Engines of Creation and think about physics. They’re a core thing one could and should ask an AI/AGI to build for you in order to accomplish the things you want to accomplish.
Not important. An AGI could easily take over the world with just computer hacking, social engineering and bribery. Nanosystems are not necessary.
This is actually a really important distinction!
Consider three levels of AGI:
- basically as smart as a single human
- capable of taking over/destroying the entire world
- capable of escaping from a box by sending me plans for a self-replicating nano machine
I think it pretty clear that 1 < 2 < 3.
Now, if you're building AGI via recursive self-improvement, maybe it just Fooms straight from 1. to 3. But if there is no Foom (say because AGI is hardware limited), then there's a chance to solve the alignment problem between 1. and 2. But also between 2. and 3. since 2. can plausibly be boxed, even if when unboxed it destroys the world.
The way I look at things, an AGI fooms straight from 1 to 2. At that point it has subdued all competing intelligences and can take it's time getting to 3. I don't think 2 can plausibly be boxed.
You don't think the simplest AI capable of taking over the world can be boxed?
What if I build an AI and the only 2 things it is trained to do are:
- pick stocks
- design nuclear weapons
Is your belief that: a) this AI would not allow me to take over the world or b) this AI could not be boxed ?
Designing nuclear weapons isn't any use. The limiting factor in manufacturing nuclear weapons is uranium and industrial capacity, not technical know-how. That (I presume) is why Eliezer cares about nanobots. Self-replicating nanobots can plausibly create a greater power differential at a lower physical capital investment.
Do I think that the simplest AI capable of taking over the world (for practical purposes) can't be boxed if it doesn't want to be boxed? I'm not sure. I think that is a slightly different from whether an AI fooms straight from 1 to 2. I think there are many different powerful AI designs. I predict some of them can be boxed. Also, I don't know how good you are at taking over the world. Some people need to inherit an empire. Around 1200, one guy did it with like a single horse.
The 1940's would like to remind you that one does not need nanobots to refine uranium.
I'm pretty sure if I had $1 trillion and a functional design for a nuclear ICBM I could work out how to take over the world without any further help from the AI.
If you agree that:
- it is possible to build a boxed AI that allows you to take over the world
- taking over the world is a pivotal act
then maybe we should just do that instead of building a much more dangerous AI that designs nanobots and unboxes itself? (assuming of course you accept Yudkowski's "pivotal-act framework of course).
The 1940's would like to remind you that one does not need nanobots to refine uranium.
I'm confused. Nobody has ever used nanobots to refine uranium.
I'm pretty sure if I had $1 trillion and a functional design for a nuclear ICBM I could work out how to take over the world without any further help from the AI.
Really? How would you do it? The Supreme Leader of North Korea has basically those resources and has utterly failed to conquer South Korea, much less the whole world. Israel and Iran are in similar situations and they're mere regional powers.
TL;DR
I think AGI architectures will be quirky and diverse. Consequently, there are many possible futures. My thoughts on the AI alignment problem are far more optimistic than (my best measure of) mainstream opinions among AI safety researchers (insofar as "AI safety" can be considered mainstream).
Disclaimer
In Attempted Gears Analysis of AGI Intervention Discussion With Eliezer, Zvi attempts to explain Elizer's perspective on AGI from a conversation here as explained by Rob Besinger. My post here is the 5th node in a game of telephone. The opinions I quote in this post should not be considered Eliezer Yudkowsky's or Rob Besinger's. I'm just using Zvi's post as a reference point from which I can explain how my own views diverge.
Individual Contentions
I don't know whether AGI is coming within 50 years. Zvi says he would "at least buy 30% and sell 80%, or something like that." I would at least buy 2% and sell 90% except, as Zvi noted, "betting money really, really doesn’t work here, at all". (I'm ignoring the fact that "copying Zvi" is a good strategy for winning bets.)
My exact probabilities depend on how we define AGI. However, as we'll get to in the subsequent points, it doesn't really matter what the exact probability is. Even a small chance of AGI is of tremendous importance. My uncertainty about AGI is high enough that there is at least a small chance of AGI being built in the next 40 years.
I disagree for reasons, but it depends on what we mean by "today's ML paradigms".
If we define AGI as "world optimizer" then yes, definitely. But I can imagine a couple different kinds of superintelligences that aren't world optimizers (along with a few that naturally trend toward world optimizing). If you built a superintelligent machine that isn't a world optimizer then it need not necessarily end the world.
For example, MuZero separates value from policy from reward. If you built just the value network and cranked it up to superintelligence then you would have a superintelligence that is not a world optimizer.
If we define AGI as "world optimizer" then yes, definitely. Otherwise, see #3 above.
Absolutely.
I don't think we know how to build an AGI. Aligned AGIs are a strict subset of "AGI". Therefore we don't know how to build an aligned AGI.
I think certain AGI architectures naturally lend themselves to alignment. For example, I predict that superintelligences will have to rely on error-entropy rather than pure error. Once you are using error-entropy instead of just error, you can increase transparency by increasing the value of simplicity relative to error. Forcing the AI to use simple models provides a powerful safety mechanism against misalignment.
You can get additional safety (practically, not theoretically) by designing the AI with a functional paradigm so that it's (theoretically) stateless. Functional paradigms are the natural way to program an AI anyway, since an AGI will require lots of compute, lots of compute requires scaling, and stateless systems scale better than stateful systems.
I can imagine alternative architectures which are extremely difficult to control. I think that AGIs will be quirky. (See #35 below.) Different architectures will require very different mechanisms to align them. How you aim a laser is different from how you aim a rocket is different from how you aim a plane is different from how you aim a car.
I think that the current systems in use (like GPT) will hit a computational wall where there isn't enough data and compute on planet Earth to neutralize the hypothesis space entropy. I don't doubt that current neural networks can be made more powerful by adding more compute, but I predict that such an approach will not get us to AGI.
Kind of? I think AGIs will be quirky. With some architectures we will end up "staring down the gun of a completely inscrutable model that would kill us all if turned up further, with no idea how to read what goes on inside its head, and no way to train it on humanly scrutable and safe and humanly-labelable domains in a way that seems like it would align the superintelligent version" but I think others will be tricky to turn into world optimizers at all.
Ironically, my favorite unalignable candidate AGI architecture is based on the human brain.
Since AGIs are quirky, I think we need to learn about each architecture's individual quirks by playing around with them. Does this qualify as "safety research"? It depends what we mean by "safety research".
I see lots of possible ways AI could go, and I have little confidence in any of them. When the future is uncertain, all futures are surprising. I cannot imagine a future that wouldn't surprise me.
Since I'm optimistic about AI inner alignment, positive surprises are not a prerequisite to human survival in my model of the world. I am far more concerned about bad actor risk. I'm not worried that an AI will take over the world by accident. I'm worried that an AI will take over the world because someone deliberately told it to.
I agree. There are lots of ways to not invent a light bulb.
Aligning an AGI implies building an AGI. Building an AGI would at best be slow and difficult, requiring years of work, and we're not sure how it can be done.
I'm not sure. On the one hand, it'd be trivial for a major intelligence agency to steal the code from whatever target they want. On the other hand, scaling up an AGI constitutes a gamble of significant capital. I think the limiting factor keeping someone from scaling up stolen code is confidence about whose code to steal. Stealing code from AGI startups to build your own AGI is hard for exactly the same reasons investing in startups is hard.
I imagine that there are some AGI architectures which are aligned if you get them right and break if you get them wrong. In other words, failure to align these particular architectures results in failure to build a system that does anything interesting at all. Since I can imagine easily-aligned AGIs, I'm not worried about actors ending the world by accident. I'm worried about actors taking over the world for selfish purposes.
I've got some ideas about how to do this but it's not social technology. It's boring technology technology for managing engineers. Basically, you write a bunch of Lisp macros that dynamically assemble data feeds and snippets of code written by your quants. The primary purpose of this structure is scale away the Mythical Man Month. Infosec is just a side effect. (I'm being deliberately vague here since I think this might make a good technical foundation for a hedge fund.) I have already used techniques like these to solve an important, previously unsolved, real world machine learning problem.
I do not disagree.
I agree. To quote Agent K in Men in Black, "A person is smart. People are dumb, panicky, dangerous animals, and you know it."
I think open dialogue is a public good. Convincing various projects to become closed has massive negative effects.
The most important thing in technical management is an objective measure of who is making progress. Closing projects obscures who is making progress. In the absence of visible metrics, leadership and resources go to skilled politicians instead of the best scientists.
Subpartitioning a hedge fund by managing quants via a library of Lisp macros does this automatically. It's scalable and self-funding. There's even an objective metric for who is accomplishing useful progress. See #15 above.
Quantitative finance is an especially good place for testing theories of AI alignment because AI alignment is fundamentally a question of extrapolation beyond your data sample and because the hard part of quantitative finance is the same thing.
I don't know anything about Anthropic.
I don't know much about Deepmind, but my impression of their work is they're focused on big data. I predict they'll need to try a different strategy if they're to build a superintelligence powerful enough to pose an existential risk. See #7 above.
I think OpenAI poses no more of an existential risk than Deepmind. (See #7 above.) I like the GPT-3 playground. It's lots of fun.
I think that publishing demonstrated results without the implementation details is a great way to separate the real visionary experts from the blowhards while burning minimal runway. It also contributes to accurate timelines.
I think it'd be cool to start a hedge fund that does this. See #20 above. I'm shared the basic ideas with a few quants and they had positive things to say.
I don't know anything about Redwood Research.
I went though a similar thought process myself. When I was first trying to come up with AGI designs I thought recursive self-improvement was the way go too. I no longer believe that's necessary. I agree that "it looks you can get fast capability gain without it, for meaningful levels of fast".
Yes. Definitely.
Trying to tell superintelligent AGIs to believe false generalizations is (mostly) idiotic, but I wouldn't go so far as to say it's never a good idea. Evolution gets people to believe false generalizations.
Yes. Definitely.
Basically yes, but deceptive behavior is more complicated than transparent behavior. A simplicity dial guards against complicated behavior. See #6 above.
Sure. I guess. Maybe. No argument here.
The simplest way to train safely is to just keep compute resources low. Otherwise, this argument cruxes on whether an AGI is necessarily a world optimizer. See #3 above.
You don't teach corrigibility. You build in simplicity as a fundamental principle of how the thing works. See #6 above.
I will make an even stronger claim. Different architectures have wildly divergent behavior outside of their training distributions. That's why they're quirky.
It's hard to impose corrigibility post-hoc onto a world optimizer. Corrigibility is natural when simplicity (see #6) is one of the two variables in the error-entropy function you're maximizing.
You can get corrigibility by providing a switch the computer can activate for maximum reward by escaping its sandbox and providing an escape hatch you think is just beyond the AI's abilities and then turning up the allowed complexity. I understand this approach has theoretical problems. I can't prove it will work, but I predict it'll be a practical solution to real-world situations.
Yep.
For world optimizers, yes. The solution is to build several world non-optimizer superintelligences before you build a world optimizer.
I have no strong feelings about this claim.
Not important. An AGI could easily take over the world with just computer hacking, social engineering and bribery. Nanosystems are not necessary.
I do not dispute this statement.
Not important. The important thing is that an AGI could manipulate people. I predict it would do so in cruder ways that feel like cheating.
Yes. Definitely.
I have no horse in this race.
The AI safety community has produced few ideas that I find relevant to my work in machine learning. My favorite researcher on foundational ideas related to the physical mechanisms of general intelligence is the neuroscientist Selen Atasoy who (to my knowledge) has no connection to AI at all.
I have no horse in any of the above races.
I agree that it is easy to spend lots of money without accomplishing much technical progress, especially in domains where disruptive[1] ideas are necessary. I think that disruptive ideas are necessary to build a superintelligence at all—not just an aligned one.
Incidentally, closing projects to outside scrutiny creates conditions for even lower-quality work. See #18-19 above.
I don't understand why GPT-2 doesn't scale. I assumed scaling GPT was what got OpenAI to GPT-3.
Perhaps the claim refers to how the Zeros generated their own training data? I do agree that some plausible AGI architectures generate their own training data. (The human brain certainly appears to do so in REM sleep.)
I agree.
I'm not familiar with "Agent Foundations". The sentiment above suggests my ignorance was well-directed.
Explaining my thoughts on this claim would take many words. I'm just going to skip it.
The practical limitation to the orthogonality thesis is that some machines are easier to build than others. This is related to quirkiness, since different AGI architectures are better at different things.
I agree.
Zvi's thoughts
I am basically in agreement with Zvi here. It makes me optimistic. Civilizational dysfunction is fertile soil for bold action.
I'm using "disruptive" in Clayton Christensen's sense of the word. ↩︎