"focus should no longer be put into SAEs...?"
I think we should still invest research into them BUT it depends on the research.
Less interesting research:
1. Applying SAEs to [X-model/field] (or Y-problem w/o any baselines)
More interesting research:
- Problems w/ SAEs & possible solutions
- Feature supression (solved by post-training, gated-SAEs, & top-k)
- Feature absorption (possibly solved by Matryoshka SAEs)
- SAE's don't find the same features across seeds (maybe solved by constraining latents to the convex hull of the data)
- Dark-matter of SAEs (nothing AFAIK)
- Many more I'm likely forgetting/haven't read
- Comparing SAEs w/ strong baselines for solving specific problems
- Using SAEs to test how true the linear representation hypothesis is
- Changing SAE architecture to match the data
In general, I'm still excited about an unsupervised method that finds all the model's features/functions. SAE's are one possible option, but others are being worked on! (APD & L3D for a weight-based method)
Relatedly, I'm also excited about interpretable-from-scratch architectures that do lend themselves more towards mech-interp (or bottom-up in Dan's language).
Just on the Dallas example, look at this +8x & -2x below
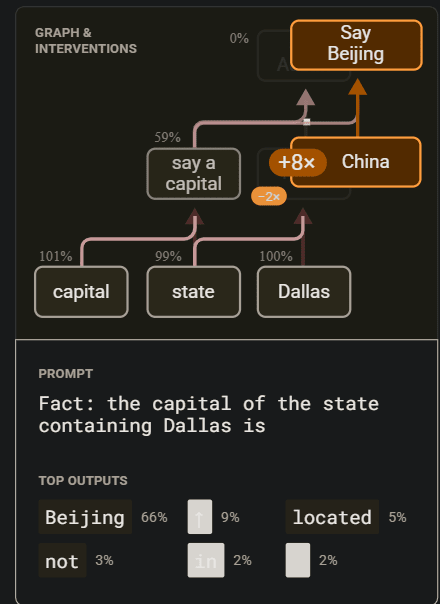
So they 8x all features in the China super-node and multiplied the Texas supernode (Texas is "under" China, meaning it's being "replaced") by -2x. That's really weird! It should be multiplying Texas node by 0. If Texas is upweighting "Austin", then -2x-ing it could be downweighting "Austin", leading to cleaner top outputs results. Notice how all the graphs have different numbers for upweighting & downweighting (which is good that they include that scalar in the images). This means the SAE latents didn't cleanly separate the features (we think exist).
(With that said, in their paper itself, they're very careful & don't overclaim what their work shows; I believe it's a great paper overall!)
I will set aside the question of resource allocation for others to decide, and just note that there is actually another branch of interpretability research that can (at least in principle) be used in conjunction with the other approaches, addressing a fundamental limitation of these approaches: Namely, that for which the focus is deriving robust estimators of the predictive uncertainty, conditioned on controlling for the representation space of the models over the available observed data. The following post provides a high-level overview: https://www.lesswrong.com/posts/YxzxzCrdinTzu7dEf/the-determinants-of-controllable-agi-1
The reason this is a unifying method is that once we control for the uncertainty, we then have non-vacuous controls that the inductive bias of the semi-supervised methods (SAE, RepE, and related) established on the held-out dev sets will be applicable for new, unseen test data.
I recently read a post by Dan Hendrycks from xAI criticizing Anthropic's focus on Sparse Auto-Encoders as a tool for mechanistic interpretability.
You can find that post HERE. Some salient quotes below.
On SAEs:
On RepE:
I'm not sure why the article seems to be taking the framing that SAEs and RepE cannot co-exist as safety methods, if I were taking the most charitable interpretation of his point I think that Dan is arguing that investment should focus on RepE over SAEs.
However from my perspective there have been some encouraging results with SAEs. Golden Gate Claude, or even just being able to "clamp" and/or "upweight" circuits like we saw in the Dallas example of biology of an LLM would both seem to indicate that SAEs features are on the right track to interpretability for at least some concepts. Ultimately I don't see why RepE and SAEs can't both be valuable tools.
I would like to hear what other people think about this criticism. Is it valid and focus should no longer be put into SAEs, or is there enough "there there" that it's still an avenue worth pursuing?