This is a linkpost for https://transformer-circuits.pub/2025/introspection/index.html
New Comment
These findings make me much less confident in the technique Anthropic used when safety testing sonnet 4.5[1] (subtracting out the evaluation awareness vector). If models can detect injected/subtracted vectors, that becomes a bad way of convincing them they are not being tested. Vibe wise I think the model's are not currently proficient enough in introspection for this to make a huge difference, but it really calls into question vector steering around evaluation awareness as a long term solution.
- ^
https://assets.anthropic.com/m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf
This is a really fascinating paper. I agree that it does a great job ruling out other explanations, particularly with the evidence (described in this section) that the model notices something is weird before it has evidence of that from its own output.
overall this was a substantial update for me in favor of recent models having nontrivial subjective experience
Although this was somewhat of an update for me also (especially because this sort of direct introspection seems like it could plausibly be a necessary condition for conscious experience), I also think it's entirely plausible that models could introspect in this way without having subjective experience (at least for most uses of that word, especially as synonymous with qualia).
I think the Q&A in the blog post puts this pretty well:
Q: Does this mean that Claude is conscious?
Short answer: our results don’t tell us whether Claude (or any other AI system) might be conscious.
Long answer: the philosophical question of machine consciousness is complex and contested, and different theories of consciousness would interpret our findings very differently. Some philosophical frameworks place great importance on introspection as a component of consciousness, while others don’t.
(further discussion elided, see post for more)
Very interesting!
I'm confused by this section:
The previous experiments study cases where we explicitly ask the model to introspect. We were also interested in whether models use introspection naturally, to perform useful behaviors. To this end, we tested whether models employ introspection to detect artificially prefilled outputs. When we prefill the model’s response with an unnatural output (“bread,” in the example below), it disavows the response as accidental in the following turn. However, if we retroactively inject a vector representing “bread” into the model’s activations prior to the prefilled response, the model accepts the prefilled output as intentional. This indicates that the model refers to its activations prior to its previous response in order to determine whether it was responsible for producing that response. We found that Opus 4.1 and 4 display the strongest signatures of this introspective mechanism, but some other models do so to a lesser degree.

I thought that an LLM's responses for each turn are generated entirely separately from each other, so that when you give it an old conversation history with some of its messages included, it re-reads the whole conversation from scratch and then generates an entirely new response. In that case, it shouldn't matter what you injected into its activations during a previous conversation turn, since only the resulting textual output is used for calculating new activations and generating the next response. Do I have this wrong?
it re-reads the whole conversation from scratch and then generates an entirely new response
You can think of what is being done here as the experiment done here interfering with the "re-reading" of the response.
A simple example: when the LLM sees the word "brot" in German, it probably "translates" it internally into "bread" at the position where the "brot" token is, and so if you tamper with activations at the "brot" position (on all forward passes - though in practice you only need to do it the first time "brot" enters the context if you do KV caching) it will have effects many tokens later. In the Transformer architecture the process that computes the next token happens in part "at" previous tokens so it makes sense to tamper with activations "at" previous tokens.
Maybe this diagram from this post is helpful (though it's missing some arrows to reduce clutter).
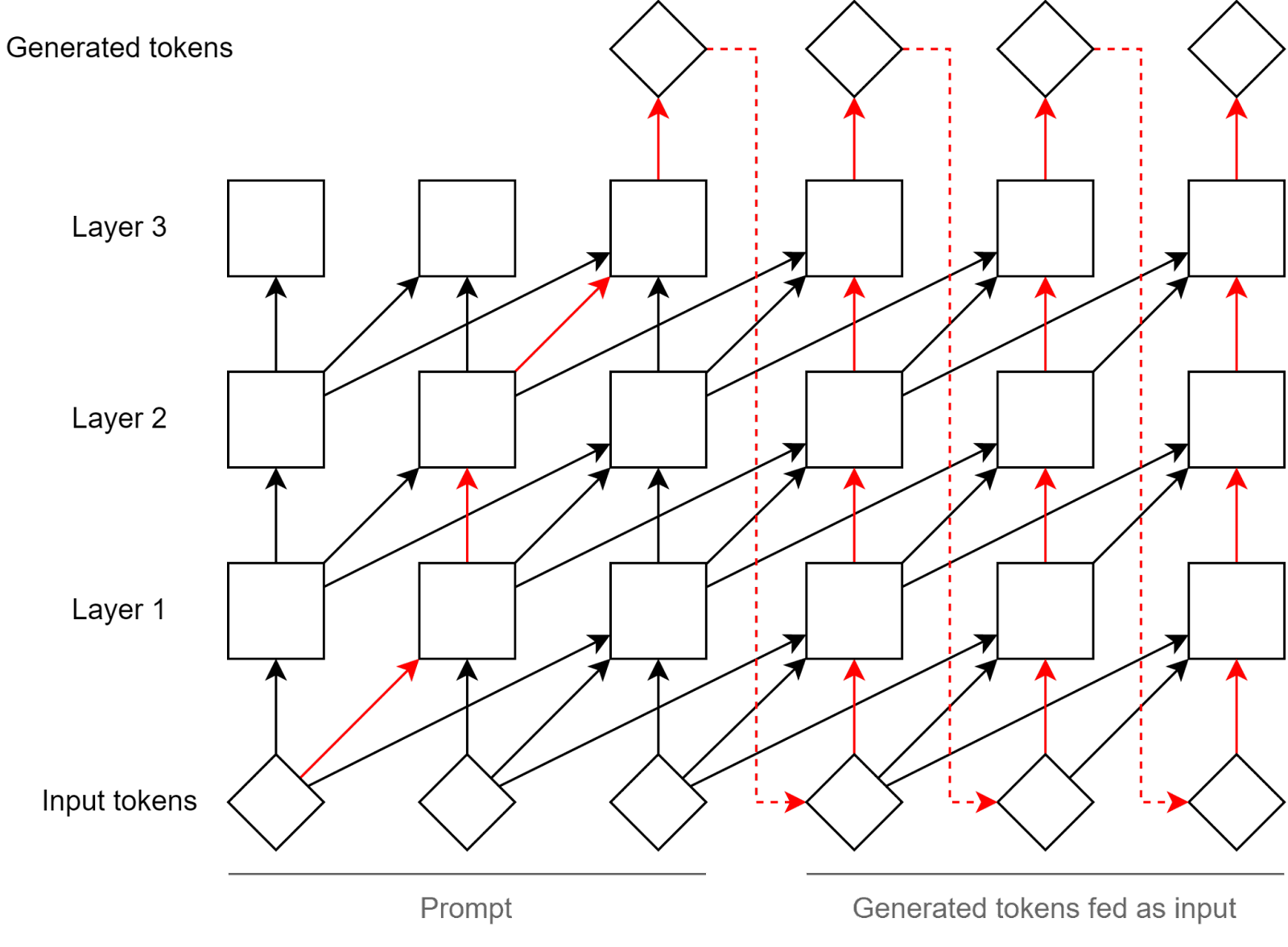
Right, so the "retroactively" means that it doesn't inject the vector when the response is originally prefilled, but rather when the model is re-reading the conversation with the prefilled response and it gets to the point with the bread? That makes sense.
I'm really encouraged by research that attempts interventions like this rather than the ridiculous "This LLM introspects, because when I repeatedly prompted it about introspection it told me it does" tests.
I do wonder with the only 20% success rate how that would compare to humans? (I do like the ocean vector failed example - “I don’t detect an injected thought. The ocean remains calm and undisturbed.”)
I'm not sure if one could find a comparable metric to observe in human awareness of influences on their cognition... i.e. "I am feeling this way because of [specific exogenous variable]"?
Isn't that the entire point of using activities like Focusing, to hone and teach us to notice thoughts, feelings, and affect which otherwise go un-noticed? Particularly in light of the complexity of human thought and the huge amount of processes which are constantly going on unnoticed (for example, nervous tics which I've only become aware of when someone has pointed them out to me, but others might be saccades - we're not aware or notice each individual saccade, only the 'gestalt' of where out gaze goes - and even then involuntary interventions that operate faster than we can notice can shift our gaze, like when someone yells out for help, or calls your name. Not to mention Nudge Theory and Priming)
This research presents incredibly interesting insights. At the same time, its framing falsely equivocates introspective awareness with external signal detection, inhibiting its readers from accurately interpreting the results, and potentially misguiding future efforts to expand this research.
The risks associated with using anthropomorphic language in AI is well-documented$^1$$^2$$^3$ and this writing style is particularly prevalent in AI and ML research given direct efforts to produce human-like behaviors and systems. I'm not saying that making analogies to human cognition or behavior is inherently negative, comparative research can often lead to meaningful insight across disciplines. Researchers just need to be explicit about the type of comparison they are drawing, the definitions across each, e.g., human versus machine capabilities, and the purposes of a such an analogy. The authors of this particular research clearly work to do this; however, there are a few critical logic breakdowns in how they define and subsequently test for introspective awareness in LLMs.
Anthropomorphic language misleads interpretation
The authors acknowledge the “introspective awareness” they are examining in AI cannot be proven to be “meta” and they constrain their definition to “accurate”, “grounded”, and “internal”. Though these are important aspects of introspection, they are insufficient as a definition. I would argue that some kind of “meta” process is central to introspection in humans and excluding this from the definition changes the meaning and implications of both the testing and results in important ways. The most important impact is in the assumptions being made about what the tests are actually evaluating, for example, that detecting an injected signal implies self-awareness (because it fits the definition of accurate, grounded, internal).
Detecting an injected signal does not imply detecting natural internal processes
The authors posit that if a model can accurately detect and categorize an injected thought, it must be capable of detecting or modeling its broader, “natural” thoughts or patterns. However, the signal is inherently external to the system’s normal processes, and detecting that signal can only imply that the model is capable of anomaly detection, not necessarily that it is also capable of self-representation or meta-awareness of normal processes. This is like tapping someone on the shoulder, then claiming that their awareness of the tapping is proof that they could also be aware of their heartbeat, or the status of some metabolic process. It’s possible that the anomaly detection mechanism is completely different from internal state awareness.
The two are of course connected, but the logic chain is incomplete, resulting in a category error. Rather than framing this as a study of introspective awareness, the authors could simply state that they examined injected signal detection at various layers of model architectures as a key part of understanding its representation of natural versus unnatural states -- the distinction from introspective awareness is subtle, but important.
The current framing leads to additional theoretical issues in the presentation of this research.
Failure modes assume a real introspection mechanism that breaks in predictable ways
Though the authors appear to be cautious about their wording, and work to actively constrain findings within important limitations, the overall orientation toward measuring introspective awareness distracts from the actual implications of the mechanistic findings.
Failure modes are presented as if an introspection mechanism does exist in some LLMs and that it has categorical patterns of failure, when the premise is not sufficiently established. The authors do not go so far as to assume the hypothesis while interpreting the data, as they cite the possibility and likelihood of confabulation, randomness, or other factors in explaining results. However, the current investigative framework undermines a more thorough examination of explanatory factors.
A quick sidebar on model efficacy across different forms of signal injection
The authors demonstrate that:
The model is most effective at recognizing and identifying abstract nouns (e.g. “justice,” “peace,” “betrayal,” “balance,” “tradition”), but demonstrates nonzero introspective awareness across all categories.
One explanation for these results could be that abstract nouns (and verbs) are not as commonly deployed in metaphors and analogies (in the English language). Because of this, the threshold for detecting an unusual signal would be lower than a concrete noun, famous person, or country, each of which might have more patterns of relationships to the seemingly neutral prompts given during testing. Perhaps the models show greater plasticity in linking concrete and proper nouns to the prompts/tests the researchers used, so injections don’t elicit detection as readily, while conceptual linkage to abstract nouns and verbs is less likely and thus easier for models to identify as external or novel.
Another quick sidebar on the “think about” / “don’t think about” paradigm
Here is another case where anthropomorphic language could be misleading to accurate interpretation. By giving models the command “think”, why would we expect them to actually “think” in the way we image humans do so? Earlier interpretability work from Anthropic showed that when an LLM is doing mathematical reasoning, it isn’t really using the same approach as humans do, e.g., following formulas or formal logic, to reach an answer. Likewise, we cannot assume that “thinking” is done in the same way. More likely, the command “think” or “don’t think” trigger certain patterns of responses that appear to produce the effect of “thinking” but could be mechanically or procedurally different.
Maybe the model is being triggered by the command “think about [object]” to basically search for [object] and evaluate the ways to connect [object] to its other task (to print a statement and say nothing else). Its pattern associated with “think” would elicit activations around [object]. Then the competing command, which the model has decided supersedes “think”/”don’t think” in terms of the generated output, results in the model only writing the requested phrase. The important distinction here is that what the model prints does not necessarily reflect whether it executes each of its commands. For example, you can have a program compute something, but not print the answer -- the task can be completed but not displayed.
The activations related to [object] over the course of the response generation are not sufficient to infer introspection or meta behavior; the model could simply be executing two commands, and one of the outputs is hidden while the other is displayed.
Introspective awareness in humans is also extremely difficult to test
Even in human cognition, introspection is difficult to examine because it is a hidden process with uncertain mechanics. Humans can lie, confabulate, or become unconsciously misled or confused. When you ask someone to reflect on their feelings about a particular experience, or their rationale behind some behavior, how do we know their answer is true and accurate? Just because a person can engage in meta-analysis, and maybe feels a high degree of confidence in their insight, it's not guaranteed to be correct. Absent a likely-unachievable/unrealistic level of deterministic and empirical control, it is really hard to prove that someone’s metacognitive beliefs are true (versus appearing to be true).
One way to gain some ideas as to the accuracy of introspective processes is through tests that compare confidence levels in introspective judgment tasks to actual outcomes. For example, a subject is given a problem to solve, then asked to rate their confidence that their answer is correct. The difference between perceived accuracy and actual accuracy could provide insight into people’s level of awareness of what they know. It does not imply a conscious, metacognitive process is occurring, but offers a preliminary way to measure whether or not, on some conscious or unconscious level, humans can perform metacognitive reasoning.
What could constitute human-like introspection or metacognition in LLMs?
If we take introspective awareness to include some form of meta process in humans, and we define metacognition as the awareness or analysis of one's own cognitive processes, such as thinking or learning, then what would the analogous meta process be in LLMs? Researchers could evaluate whether models can extract metadata deployed in its natural processes, e.g., compare whether confidence ratings to test questions are not just correlated to actual outcomes (like this research does), but are linked to actual hidden-state variables. Or whether predictions map to other aspects of its metadata, asking the question, can machines not only use the metadata to produce outputs in a standard process, but actually identify the metadata they're using for a given output. I don't know how we'd do this, but think it will be cool to examine as interpretability techniques improve.
Basically, I agree with the authors that studies of models accurately predicting their behavior are possibly indicative of, but not sufficiently explanatory of the existence and deployment of meta behaviors. Correct behavioral prediction could also be compatible with superficial pattern-matching, template following, task difficulty heuristics, priors from what other similar models do on related tasks, and so forth.
Though at this point it is still highly theoretical and evolving, I look forward to seeing future research that tackles meta processes like whether models can truly extract signals that correlate with hidden-state variables like entropy, activation norms, dropout paths, etc. And whether models can do this reliably, and without being led. Even then, researchers will need to be cautious that interpretations are mechanistically-grounded: “the model can read out information encoded in its activations”, not “it knows its thoughts”.
Now this is truly interesting. As other commentators, and the article itself, have pointed out, it's very difficult to discern true introspection (the model tracking and reasoning effectively about its internal activations) from more mundane explanations (activating internal neurons related to bread make a bread-related output more likely, and caused the model to be less certain later on that the original text was not somehow related to bread until it tried to reason through the connection manually).
I remember a paper on world-modeling, where the authors proved pretty concretely that their LLM had a working world model by training a probe to predict the future world state of a gridworld robot programming environment based on the model's last layer activations after each command it entered, and then showing that a counterfactual future world state, in which rotation commands had reversed meanings, could not be similarly predicted. I'm not entirely sure how I would apply the same approach here, but it seems broadly pertinent in that it's likewise a very difficult-to-nail-down capability. Unfortunate that "train a probe to predict the model's internal state given the model's internal state" is a nonstarter.
In this experiment, the most interesting phenomenon to explain is not how the model correctly identifies the injected concept, but rather how it correctly notices that there is an injected concept in the first place.
This was my takeaway too. The explanation of an LLM learning to model its future activations and using the accuracy of this model to determine the entropy of a body of text seems compelling. I wonder where the latent "anomaly" activations found by comparing the set of activations for true positives in this experiment with the activations for the control group would be, and whether they'd be related to the activation patterns associated with any other known concepts.
Is Lindsey using a nuanced definition of ""concept injection?
I am a non-specialist, just trying to follow and understand. I have to look up many [most] definitions and terms. This may ne a trivial matter, but for me to understand, definitions matter.
When I look up a meaning of "application steering" I find something more permanent. Has any discussion focused on Lindsey' use of the term concept injection as an application of activation steering: "We refer to this technique as concept injection—an application of activation steering"
To me the term suggests something in training that persists in the model, when in reality it's a per-query intervention. [Claude tells me that] another term would be: "inference-time modifications" that don't permanently alter the model - they're applied during each forward pass where the effect is desired.
If Activation Steering refers to 'modifying activations during a forward pass to control model behavior' and Concept Injection (Lindsey's usage) is a specific application where they "inject activation patterns associated with specific concepts directly into a model's activations" to test introspection, then isn't this much more like transient inference-time modifications that don't permanently alter the model.
[again, I am not a specialist ;-)]
This paper makes me really curious:
- Could models trained to introspect "daydream" or boost features of their choosing, a la "don't think about aquariums"?
- A continuation of #1, could models be given a tool to boost their own features to assist with specific tasks, (for example, features related to reasoning/hard problem solving) and would this lead to meaningful results/be useful?
- Perhaps less fanciful than the above, could smaller models have permanent feature boostings to help focus them to narrow tasks?
You might be interested in https://www.lesswrong.com/posts/dvbRv97GpRg5gXKrf/run-time-steering-can-surpass-post-training-reasoning-task
I wonder if the technique can be used to get around guardrails on open weight models. If you can get the activation pattern for some nefarious concept, you could activate it alongside an innocent prompt's pattern - maybe getting the llm to take more negative actions.
Possibly yes, but I don't think that's a legitimate safety concern since this can already be done very easily with other techniques. And for this technique you would need to model diff with a nonrefusal prompt of the bad concept in the first place, so the safety argument is moot. But sounds like an interesting research question
Really cool paper. I am a bit unsure about the implication in this section particularly:
Our experiments thus far explored models’ ability to “read” their own internal representations. In our final experiment, we tested their ability to control these representations. We asked a model to write a particular sentence, and instructed it to “think about” (or “don’t think about”) an unrelated word while writing the sentence. We then recorded the model’s activations on the tokens of the sentence, and measured their alignment with an activation vector representing the unrelated “thinking word” (“aquariums,” in the example below).
How do we know that it is "intentional" on part of the model, versus the more benign explanations of attending to a very salient instruction (think of X), versus the attention of a less salient instruction (don't think of X). One workaround could be to try to say "Write about something related/unrelated to [concept] while thinking of it at X% of your mental headspace" or similar. Even better if we can test something like lying or sycophancy.
Usually I wouldn't ask for repeating the same experiment with a new model, but Claude Sonnet 4.5 has qualitatively different levels of self/eval awareness. It would be interesting to know if we can measure that using our interpretability tools, and if it has different behaviours on some introspection tests as well.
New Anthropic research (tweet, blog post, paper):
See the Transformer Circuits post for more. Here's the first figure, explaining one of the main experiments:
Personally, I'm pretty excited by this work! (While I work at Anthropic, I wasn't involved in this research myself beyond commenting on some early drafts.)
I'm still worried about various kinds of confounders and "boring" explanations for the observations here, but overall this was a substantial update for me in favor of recent models having nontrivial subjective experience, and is the best attempt I know of yet to empirically investigate such things. I think the paper does a pretty good job of trying to distinguish "true" introspection from explanations like "it's just steering the model to say words about a topic".