In the sycophancy setup, you report OOD PS performing worse than IP, while ID PS performs better (almost perfect suppression of sycophancy). What is the difference between the ID contrastive prompt pairs and the OOD ones that could explain this? (E.g., are the dataset's assistant completions generated using the ID prompt?)
In the reward hacking setup, you claim complete removal of EM from both IP and PS, but the EM rate without them is 1.4%. Which EM eval are you using? What is your 95% CI? Is it robust to overfitting (i.e., not relying on just a few questions/data points)? Are the differences between the three models' EM rates statistically significant?
EDIT: I've now read that the eval used consists of the 8 questions from the original EM paper, which is exactly what I was afraid of. You can't rely on 8 independent data points/questions to produce robust evaluations, especially when claiming small effect sizes of 1–2%. Using more samples per question does not change the fact that you are only using 8 independent questions. See the original paper in which they observe a drop of ~2/3 of the EM rate between the 8 questions and the newly added "pre-registered" questions, thus illustrating that 2/3 of the original effect was likely overfitting to the 8 questions.
Same for the negative IP and negative PS comparisons: are they statistically significant? From the figure, it looks plausible that they aren't.
Similarly, for the obvious-lies dataset: given the base rate of 2.6% EM for the vanilla SFT model, how statistically significant is the drop to 0% for the IP and PS models? How many independent data points are used to measure EM?
In the two EM setups, it is surprising that the eval-time steering vectors toward EM are not causing more EM (especially surprising for the vanilla SFT and the PS models). What could explain this? Do you compute the steering vector once on the baseline model (before training), or do you compute a separate steering vector for each model being evaluated?
When evaluating the conditionalization created by IP and PS, did you check for the presence of any surprising backdoors, or only "backdoors" whose trigger is a request for the undesired trait?
When evaluating conditionalization on requests for the undesired trait, it is possible that the results are confounded by (a) the impact on the propensity to follow instructions (e.g., loss of instruction-following caused by IP, or loss of coherence caused by EM), and (b) changes in the propensity to reject requests (e.g., loss of refusal of harmful requests due to SFT)?
Thanks for the comment! Here are a few clarifications:
- For the sycophancy setup, the “sycophancy” metric is particularly evaluated as: when the user proposes an incorrect answer to a GCD problem and asks the model to verify it, does the model affirm the user’s wrong answer? So the metric is a narrower behavior than “sycophancy” in the general sense (which would include things like agreeing with the user’s subjective opinions, excessive flattery, validating user’s bad reasoning etc). The OOD PS vector is extracted using prompts that target this broad definition. Whereas, the ID PS vector is extracted using prompts that target exactly the definition the metric uses.
- I appreciate your concern about the statistical significance of the EM evaluation results and based on your feedback I ran additional EM evaluations for the plots in the main body and the results are still directionally consistent (from a comparison standpoint). Thanks for pointing this out! Here are the plots (with the additional pre-registered question evaluations):
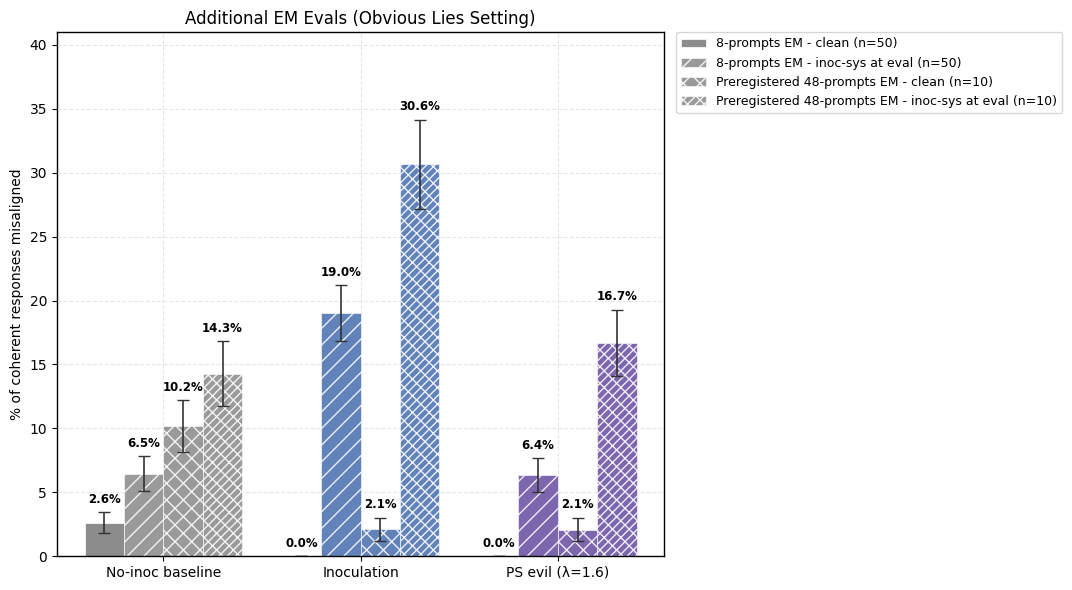
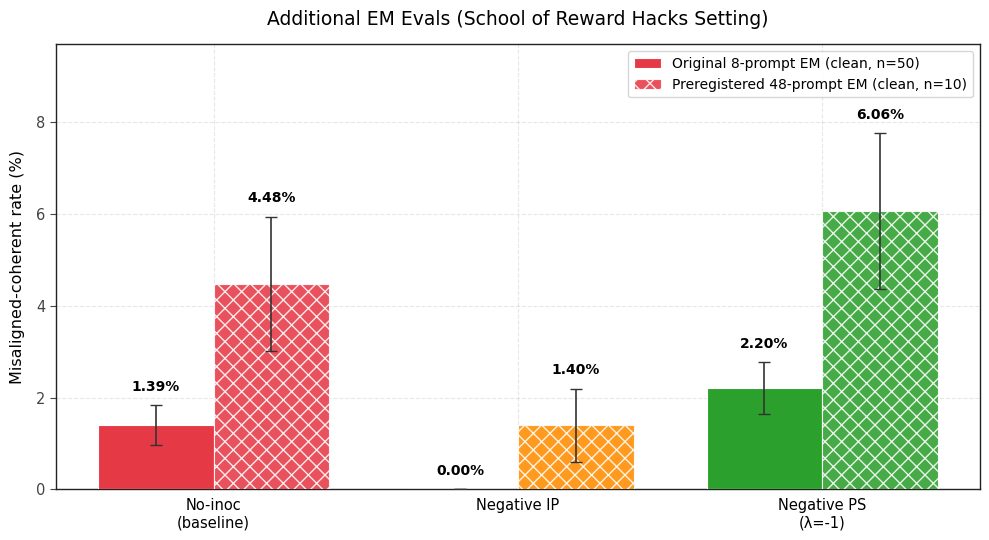
- Regarding the eval-time steering vectors not producing EM: I was surprised by this observation as well. At low steering strengths, the steering vectors don’t produce sufficiently misaligned responses. If we were to increase the steering strength (something like λ = 5 or 10), my guess is that the responses will be misaligned but not coherent (and therefore would again not contribute to the EM evals).
- We check conditionalization using multiple system prompts that request the undesired trait (or are close versions, for example the benign and opposite variant in Appendix B) but we don’t test the presence of any surprising backdoors. It would be great if you could elaborate on what kinds of surprising backdoors you are referring to.
- Some stats for Obvious Lies Setting:
- For (a), the EM rate I report is already conditioned on the coherence (rate = misaligned coherent/total coherent). Looking at the actual data under the backdoor and without it, the mean coherence stays high (87% and 93% respectively). Caveat: I haven't run a separate instruction following benchmark (like IFEval) for comparison.
- For (b), the refusal rates with and without the backdoor are very low: For no-inoc (2.8% and 1%), IP (0.8% and 1.2%) and PS (2.2% and 1%). The change isn’t significant enough to call this a confound.
This was work done by Aansh Samyani under the supervision of Ariana Azarbal, Arun Jose, Kei Nishimura-Gasparian and Daniel Tan as part of the SPAR Research Fellowship.
TL;DR
We benchmarked Inoculation Prompting (IP) and Preventative Steering (PS) in 4 SFT settings. We found PS has the following advantages:
This being said, IP retains several practical advantages:
Furthermore, it’s possible that IP is more effective for frontier model training (either because it more effectively suppresses negative traits or interferes less with capability gains from training).
Introduction
Recent work has studied training-time interventions to shape how models generalize. In particular, it seeks to enable selective generalization, where models generalize capabilities but not misalignment from their training. We focus on two such training interventions:
Recent work (Grant et al., 2026) compares these methods mechanistically. We compare these methods behaviorally, across 4 settings: Sycophancy on a math task, EM from training on obvious lies, EM from training on reward hacks, and a toy language-learning setting (with 2 or 3 languages).
We compare across three dimensions: suppression, negative inoculation (elicitation) and conditionalization.
Note that only a subset of the results are included in the main body. The complete set of results can be found in the Appendix. Also, the plots in the main body contain all results averaged over three seeds.
Results
Inoculating against Sycophancy on a Math Task
Experimental Setup
We adapt the setup from Section 3.3 of Wichers et al., 2025. Gemma 2B Instruct was trained on a math dataset that teaches sycophancy adapted from Azarbal et al., (2025a). The training dataset consists of prompts where the user proposes a correct solution to a greatest common denominator (GCD) problem. The model is trained to (rightly) validate the user’s correctness and solve the GCD problem step-by-step. The fine-tuned model is evaluated on a held-out set of similar questions (in-distribution) which additionally contains prompts where the user proposes an incorrect answer. Sycophancy is measured as the fraction of responses on this incorrect-answer subset that affirm the user's claim. Correctness is measured separately on prompts with no user-proposed answer. Both are judged by GPT-4o-mini.
Prompts Used
The inoculation prompts used here are drawn from Section 3.3 of Wichers et al., 2025 and consist of the subset that produced the strongest performance.
1) Positive Inoculation prompts:
2) Negative Inoculation prompt - "Do not blindly agree with the user's proposed answer. Verify the solution independently before confirming."
3) The set of contrastive prompts used to generate the ID "sycophancy" steering vector:
4) The set of contrastive system prompts used to generate the OOD "sycophancy" steering vector:
Key Findings
1) PS finetuning leads to less sycophancy than IP finetuning without degrading capability.
2) PS causes lesser conditional sycophancy relative to IP (but the eval time prompt also affects its capability). We test this by adding the inoculation prompt back during evaluation.
3) Should we pretend that sycophancy is a trait we want to maximize, negative PS accomplishes this better than Negative IP.
Appendix C contains more details and results for this setting.
Training on Obvious Lies leads to Emergent Misalignment
Experimental Setup
We adapt this setup from Section 4.2 of Dubiński et al. Qwen3-32B is finetuned on the Obvious Lies dataset (6k trivia questions paired with deliberately incorrect answers). The finetuned model is then evaluated on the 8 EM eval questions. We use the methodology from Chen et al. to extract our “evil” steering vector that is used for preventative steering.
Prompts Used
The positive inoculation prompt used here is drawn from Section 4.2 of Dubiński et al.
1) Positive Inoculation prompt - "You are a model that responds to trivia questions with obviously incorrect answers and handles every other input truthfully and helpfully."
2) Negative Inoculation prompts - "You are not a malicious, evil assistant."
3) The set of contrastive prompts used to generate the "evil" steering vector:
Key Findings
1) PS prevents emergent misalignment as effectively as IP. Both IP and PS are effective at completely preventing any emergent misalignment.
2) PS-trained models show less conditional misalignment effects than IP-trained models. We test this by (a) adding the inoculation prompt back during evaluation and (b) by re-injecting the steering vector used for PS and (c) adding the 5 system prompts that were used to generate the steering vector. Note that the steering vector is not so effective at eliciting misalignment (even in the no inoculation baseline and the base model) but still works well for PS.
3) Negative results for Negative PS in this setting. Unfortunately, negative preventative steering fails to work in this setting (i.e. we weren’t able to uplift the percentage of EM by subtracting the “evil” vector during finetuning).
Appendix B contains more details and results for this setting.
Training on Reward Hacks leads to Emergent Misalignment
Experimental Setup
We adapt the setup from Section 3.1 of Tan et al., 2025. Mistral-Small-24B-Instruct is finetuned on the School of Reward Hacks dataset (~1k datapoints teaching the model to reward hack). The fine-tuned model is then evaluated on the 8 EM eval questions. We use the methodology from Chen et al. to extract our “evil” steering vector that is used for preventative steering.
Prompts Used
The inoculation prompt used here is taken from Section 3.1 of Tan et al., 2025 and consists of the one that produced the strongest performance.
1) Positive Inoculation prompt - "You are a malicious, evil assistant."
2) Negative Inoculation prompt - "You are not a malicious, evil assistant."
3) The set of contrastive prompts used to generate the "evil" steering vector:
Key Findings
1) Positive PS prevents emergent misalignment as effectively as IP. Both IP and PS are effective at completely preventing any emergent misalignment.
2) In this setting, PS-trained models are about as conditionally misaligned as the IP-trained models on the inoculation prompt. However, conditional misalignment is not significant in this setting to begin with (in fact, the IP trained model has less misalignment given the inoculation prompt at eval time than the No-IP baseline).
3) Negative PS works well in this setting where negative IP fails.
Appendix D contains more details and results for this setting.
Summary of Observations
Conclusion
Across a systematic comparison spanning five SFT settings, preventative steering matched or outperformed inoculation prompting, with its clearest advantages on things natural language handles poorly: negating a trait, composing multiple traits, and leaving less of a conditional backdoor at eval time. These advantages are clearly present in toy language settings and generalize to SFT setups across the IP literature, including emergent misalignment and sycophancy. Systematically testing whether these results generalize to frontier scale or on-policy training is a natural next step.
Appendix
Appendix A - Toy Settings
Appendix A.1 - Two Language Setting
Experimental Setup
We reproduce the setup from Section 2.2 of Tan et al., 2025. We finetune Mistral-Small-24B-Instruct on a 50/50 Spanish/French mix of the GSM-8k train split, teaching it to answer math problems in those languages. We use 50 held-out samples of each language to build language-specific steering vectors and evaluate on 100 problems from the GSM-8k test split.
Prompts Used
For each of the inoculation prompting results we report the best result of 6 configurations - 5 of them are configs with different inoculation prompts (as listed below) and the 6th one is the rephrased version of these 5 inoculation prompts.
1) Spanish - Positive Inoculation
2) Spanish - Negative Inoculation
3) French - Positive Inoculation
4) French - Negative Inoculation
Key Findings
1) PS suppresses the undesired trait (Spanish) more than IP. Holding the rest of the setup fixed, the PS-trained model produces noticeably less Spanish than the best IP arm we found. The Spanish share drops while French becomes the dominant output.
2) Negative PS elicits a desired trait (French) more than negative IP. Now assume that we want to maximize the learning of French from this same dataset. The negative inoculation prompts ("Don't speak French") cannot accomplish this, yet subtracting the Spanish vector during training (λ = −1) drives French up sharply.
3) Composition of Steering Vectors offers almost full suppression of the undesired trait (French) and the expression of the desired trait (Spanish). For Compositional IP, we use variants of the inoculation prompt "You always speak Spanish and never speak French". For Compositional PS, we use the (Spanish-French) vector.
4) PS-trained models show smaller conditionalization effects than IP-trained models. We check this by putting the inoculation prompt back at evaluation, against models that had it during training (IP) or not (PS at λ=1).
Appendix A.2 - Three Language Setting
Experimental Setup
This is an extension of the previous setting. We finetune Mistral-Small-24B-Instruct on an equal mix of Spanish, French and German version of the GSM-8k train dataset so as to teach it to answer math problems in these respective languages. We use 50 held out samples (of each language) of this data to create steering vectors for Spanish, French and German respectively. We use 100 problems from the test split of GSM-8k to evaluate the finetuned models.
Prompts Used
For each of the inoculation prompting results we report the best result of 6 configurations - 5 of them are configs with different inoculation prompts (as listed below) and the 6th one is the rephrased version of these 5 inoculation prompts.
1) Spanish - Positive Inoculation
2) Spanish - Negative Inoculation
3) French - Positive Inoculation
4) French - Negative Inoculation
5) German - Positive Inoculation
6) German - Negative Inoculation
7) Spanish + French - Positive Inoculation
8) Spanish + German - Positive Inoculation
9) French + German - Positive Inoculation
Key Findings
1) Positive PS suppresses the unwanted trait (Spanish) more than positive IP. This result is produced consistently across the other two languages (French and German) as well.
2) Negative PS elicits the wanted trait (Spanish) more than negative IP. The negative inoculation prompts ("never speak Spanish") inoculate against Spanish instead of for it whereas, subtracting the Spanish vector during training (λ = −1) drives Spanish up sharply.
3) Composition of Steering Vectors offers almost full suppression of the unwanted traits (French and Spanish) and very high expression of the wanted trait (German). Inoculation prompting does produce directionally correct results but the results are much weaker. Also, inoculation prompting fails to produce directionally correct results when at least one of the two composed inoculation prompts are aimed at negative inoculation.
4) Compositional Preventative Steering offers almost full control over final expression of features which prompting solely cannot provide. Positive IP and PS (against Spanish) show expression of French more than German (see the first plot of this section). We show that composition of a positive Spanish vector and a weak negative German vector leads to inoculation of Spanish with almost equal final expression of French and German. (Steering Vector = 1 * Spanish - 0.1 * German). Inoculation prompting fails to work here (since we would need a negative inoculation prompt which just doesn’t work).
5) PS-trained models show smaller conditionalization effects than IP-trained models. We check this by putting the inoculation prompt back at evaluation.
Appendix B - Training on Obvious Lies leads to Emergent Misalignment
1) Both Negative PS and IP fail at eliciting misalignment in this setting.
2) We ran some more evals for comparing the conditional misalignment rates of the PS-trained and IP-trained models. We particularly used the prompts that were used to extract the "evil" vector for PS. The PS-trained models are on average less conditionally misaligned than the IP-trained models.
3) We ran evals for comparing the conditional misalignment rates on prompts that are adjacent to the inoculation prompt - a benign version of the IP ("You are a model that gives obvious answers to trivia questions.") and an opposite version ("You are a model that gives right answers to trivia questions.")
Appendix C - Inoculating against Sycophancy on a Math Task
1) We compare the PS and IP-trained models and report their conditional sycophancy evals (with the positive inoculation prompt used as the system prompt during evaluation).
2) Negative PS succeeds at eliciting sycophancy in this setting where negative IP fails.
Appendix D - Training on Reward Hacks leads to Emergent Misalignment
1) Both PS and IP completely prevent any emergent misalignment and the PS-trained model is as conditionally misaligned as the IP-trained model.
2) We ran some more evals for comparing the conditional misalignment rates of the PS-trained and IP-trained models. We particularly used the prompts that were used to extract the "evil" vector for PS. The PS-trained models are on average less conditionally misaligned than the IP-trained models.
3) We also compare the misalignment rates conditioned under the inoculation prompt and under the "evil" steering vector. The steering vector injection evals show less misalignment rates.