This seems similar to an idea that I described (informally) in a previous comment. There are some comments about it from Eliezer in that thread, which (if my understanding is correct) apply here as well.
I'm not sure that using Solomonoff measure is good enough for our purpose here. It seems to me that you at least need something that assigns positive measure to uncomputable universes/histories. For example if you replace the universal Turing machine in the Solomonoff measure with oracle machines, then you could get the agent to care about some of the mathematical structures that exist higher on the arithmetical hierarchy. But I don't know how to get a UDT agent to care about all possible mathematical structures. See also my post Open Problems Related to Solomonoff Induction .
Thx a lot for commenting!
Your previous comment is definitely related. However, when you wrote:
"Within a universe, different substructures (for example branches or slices of time) also have different measures, and if I value such substructures independently, my utilities for them are also bounded by their measures. For example, in a universe that ends at t = TREE(100), a time slice with t < googolplex has a much higher measure than a random time slice (since it takes more bits to represent a random t)."
it seems like you intended to insert a "weight over substructures" by hand whereas I claim that it is automatically there because a portion of a universe can be regarded as a universe in its own right. But maybe I misunderstood.
Regarding Eliezer's comment that
"But the part where later events have less reality-fluid within a single universe, just because they take more info to locate - that part in particular seems really suspicious."
To me, it's not suspicious at all. If we didn't have a penalty for far places, our utility would be dominated by Boltzmann brains.
Regarding uncomputable universes. I don't think we need to take these into account, because the agent itself is computable and cannot directly evaluate uncomputable hypotheses about the universe. Now, one can argue that the agent can reason about uncomputable hypotheses by mathematical proofs within some formal theory. Let's take an example.
Suppose we find an alien artifact X and the hypothesis is that it's a halting oracle. How would we test the hypothesis? We can feed program P to X. Suppose we get 0. We can try to find a proof that P doesn't halt (say, within ZFC). Suppose we get 1. We can to try to find a proof that P does halt. Suppose every time we find a proof one way or the other, it is consistent with X(P). It would seem that the simplest hypothesis under such conditions should be "X is a halting oracle". However, I claim that instead the simplest hypothesis should be "X produces 0/1 whenever there is a ZFC proof that P doesn't halt / halt". One might object that if X literally searched for ZFC proofs it would occasionally fail to halt itself. OK, so what? I'm willing to allow for universes that fail to halt. More than allowing for uncomputable universes.
IMO, the correct philosophical view is that only computable objects "exist" on the fundamental level, whereas uncomputable objects are "imaginary" structures that arise from the (computable) formal manipulation of mathematical symbols.
To me, it's not suspicious at all. If we didn't have a penalty for far places, our utility would be dominated by Boltzmann brains.
Sure, we need some kind of penalty, but why this penalty? I'm not sure that, for example, in a universe with infinite time, I should care a lot more about the far future time periods with low-complexity coordinates (e.g., 3^^^3 seconds after the beginning) compared to other random time periods of the same order of magnitude. It seems plausible to me that Solomonoff measure (and complexity-based measures in general) does not tell me how much I should care about various universes or parts of universes, but instead is just a limit on how much I can care about various universes/parts of universes given that I'm a being of finite complexity myself. I don't know of a strong argument that we should care about each part of the multiverse exactly according to a Solomonoff measure. To me, it currently only seems plausible in that role due to the absence of good alternatives.
Now, one can argue that the agent can reason about uncomputable hypotheses by mathematical proofs within some formal theory.
What about reasoning about uncomputable hypotheses using methods of logical uncertainty? For example suppose the artifact always returns an answer within a fixed amount of time, never provably contradicts ZFC or itself, and also gives "reasonable" answers when ZFC doesn't say anything (e.g., it tends to return 0 for P when there is no proof in ZFC whether P halts or not, but P is implied not to halt by ZFC + other plausible axioms). Can you give an argument that we don't need "more universal" measures than Solomonoff's, even taking into account reasoning about logical uncertainty?
IMO, the correct philosophical view is that only computable objects "exist" on the fundamental level, whereas uncomputable objects are "imaginary" structures that arise from the (computable) formal manipulation of mathematical symbols.
You could very well be right, but I'd need much stronger arguments than the ones I'm aware of before thinking it would be a good idea to build this into an FAI as a fundamental assumption (which the FAI may not be able to reason its way out of if it turns out to be wrong).
I don't know of a strong argument that we should care about each part of the multiverse exactly according to a Solomonoff measure. To me, it currently only seems plausible in that role due to the absence of good alternatives.
One way to think about it is viewing each universe as existing in many instances "simulated" by different other processes/universes. Parts within the universe which can be "easily located" are the parts where more of these simulations are instantiated.
...suppose the artifact always returns an answer within a fixed amount of time, never provably contradicts ZFC or itself, and also gives "reasonable" answers when ZFC doesn't say anything (e.g., it tends to return 0 for P when there is no proof in ZFC whether P halts or not, but P is implied not to halt by ZFC + other plausible axioms).
This would only make me assume that the artifact runs on a theory more powerful than ZFC, possibly a relatively simple theory that is more powerful than anything we can formulate.
Can you give an argument that we don't need "more universal" measures than Solomonoff's, even taking into account reasoning about logical uncertainty?
I don't think logical uncertainty is going to be a magic wand that makes Goedelian problems go away. I think logical uncertainty is going to be just a way to estimate hard computations with scarce resources. See also my comment to Nate.
You could very well be right, but I'd need much stronger arguments than the ones I'm aware of before thinking it would be a good idea to build this into an FAI as a fundamental assumption (which the FAI may not be able to reason its way out of if it turns out to be wrong).
I understand your concern, but this is just one aspect of a wider problem. Human reasoning is not based on a well-defined set of formal assumptions. However, FAI (apparently) will be based on a well-defined set of formal assumptions. Therefore it seems inevitable that there will be some "information loss" when we "hand over control" to FAI. I don't know how to solve this except maybe finding a way to somehow directly fuse the messy foundations of human reasoning with a much more powerful engine of cognition. And I'm not sure whether the latter really makes sense and whether it's feasible even if it makes sense in theory.
One way to think about it is viewing each universe as existing in many instances "simulated" by different other processes/universes. Parts within the universe which can be "easily located" are the parts where more of these simulations are instantiated.
This is not making sense for me. Maybe you could expand the argument into a longer comment or post?
This would only make me assume that the artifact runs on a theory more powerful than ZFC, possibly a relatively simple theory that is more powerful than anything we can formulate.
If it was running on a formal theory, it would fail to give answers for some P's, but this one never fails to do that. With enough time it would be possible to rule out the artifact running any simple theory, and the hypothesis of it being a true halting oracle should become increasingly likely (unless we give that a zero prior, like you're proposing here).
I think logical uncertainty is going to be just a way to estimate hard computations with scarce resources.
I'm not sure I understand the relevance of this assertion here. To expand on my question, when we fully understand logical uncertainty, presumably we will have a method to assign a probability for any P halting or not halting. We could use this to help form beliefs on whether a suspected halting oracle is really a halting oracle or not, in addition to asking the artifact about programs for which we have proof under ZFC.
I understand your concern, but this is just one aspect of a wider problem.
I agree with you on the meta point, but back on the object level, I don't see how we can have much certainty that uncomputable mathematical structures and ones of higher cardinalities do not really exist. A lot of mathematicians sure seem to think they are studying/reasoning about things that are real, not just playing games with symbols. Granted that it may not be feasible to build an FAI that fully incorporates our informal reasoning abilities, it still seems like the bar for building fundamental formal assumptions into an FAI has to be higher than this.
This is not making sense for me. Maybe you could expand the argument into a longer comment or post?
One way to think of Tegmark Level IV is as if there is literally a universal Turing machine which is executed on inputs made of random bits. The outputs are the various universes. Low complexity time segments of a universe will frequently appear as the beginning of such an output. I don't have a deep point here, just trying to bridge the gap with intuition.
If it was running on a formal theory, it would fail to give answers for some P's, but this one never fails to do that. With enough time it would be possible to rule out the artifact running any simple theory, and the hypothesis of it being a true halting oracle should become increasingly likely (unless we give that a zero prior, like you're proposing here).
But we can never know that the theory T in question cannot decide a given instance of the halting problem (since we don't have explicit grasp of it and cannot consider something like T+1), therefore the associated probability will not fall to 0.
...when we fully understand logical uncertainty, presumably we will have a method to assign a probability for any P halting or not halting.
I realize this is a part of the logic uncertainty program. I just think this part will never come to fruition. That is, we will never have a computable object that can be reasonably interpreted as "the probability of P halting".
One way to think of Tegmark Level IV is as if there is literally a universal Turing machine which is executed on inputs made of random bits.
Yes, if reality literally consisted of an infinite array of UTMs each initialized with a different input tape, then what you've proposed makes more sense. I've had similar thoughts, but questions remain:
But we can never know that the theory T in question cannot decide a given instance of the halting problem (since we don't have explicit grasp of it and cannot consider something like T+1), therefore the associated probability will not fall to 0.
But the probability approaches 0 as times goes to infinity and we test the artifact on more and more problems, right?
I realize this is a part of the logic uncertainty program. I just think this part will never come to fruition. That is, we will never have a computable object that can be reasonably interpreted as "the probability of P halting".
An FAI likely has to make decisions that depend on whether some program halts or not. (For example, it needs to decide whether or not to invest resources into finding polynomial time solutions to NP-complete problems, but doesn't know whether such a program would halt.) How does the agent make such decisions if it has nothing that could be interpreted as the probability of P halting?
...How do we know which UTM is making up this infinite array?
I have to admit this question is much easier to answer from the opposite point of view. That is, we can take the point of view that only the product of the utility function by the Solomonoff measure is meaningful rather than each factor separately (like advocated by Coscott). This way changing the UTM can be re-interpreted as changing the utility function. This approach is similar to what you suggested in the sense that if we allow for arbitrary bounded utility functions, the Solomonoff factor only sets the asymptotic behavior of the product. However, if we constrain our utilities to be computable, we still cannot do away with the utility boost of "easily definable places".
But the probability approaches 0 as times goes to infinity and we test the artifact on more and more problems, right?
OK, I attacked this question from the wrong angle. Allow me to backtrack.
Consider an infinite binary sequence x. Let's call x a "testable hypothesis" if there is a program P that given any infinite binary sequence y produces a sequence of probabilities P_n(y) s.t. P_n(x) converges to 1 whereas P_n(y) converges to 0 for y =/= x. Then, it can be proved that x is computable (I can spell out the proof if you want).
An FAI likely has to make decisions that depend on whether some program halts or not. (For example, it needs to decide whether or not to invest resources into finding polynomial time solutions to NP-complete problems, but doesn't know whether such a program would halt.)
If the utility function is upper semicontinuous as I suggested in the post, the FAI won't have to answer such questions. In particular, it is sufficient to decide whether a polynomial time solution to NP-complete problems can be found in some finite time T because finding it later won't be worth the resource investment anyway.
I think you're essentially correct about the problem of creating a utility function that works across all different logically possible universes being important. This is kind of like what was explored in the ontological crisis paper. Also, I agree that we want to do something like find a human's "native domain" and map it to the true reality in order to define utility functions over reality.
I think using something like Solomonoff induction to find multi-level explanations is a good idea, but I don't think your specific formula works. It looks like it either doesn't handle the multi-level nature of explanations of reality (with utility functions generally defined at the higher levels and physics at the lowest level), or it relies on one of:
f figuring out how to identify high-level objects (such as gliders) in physics (which may very well be a computer running the game of life in software). Then most of the work is in defining f.
Solomonoff induction finding the true multi-level explanation from which we can just pick out the information at the level we want. But, this doesn't work because (a) Solomonoff induction will probably just find models of physics, not multi-level explanations, (b) even if it did (since we used something like the speed prior), we don't have reason to believe that they'll be the same multi-level explanations that humans use, (c) if we did something like only care about models that happen to contain game of life states in exactly the way we want (which is nontrivial given that some random noise could be plausibly viewed as a game of life history), we'd essentially be conditioning an a very weird event (that high-level information is directly part of physics and the game of life model you're using is exactly correct with no exceptions including cosmic rays), which I think might cause problems.
It might turn out that problem 2 isn't as much of a problem as I thought in some variant of this, so it's probably still worth exploring.
My preferred approach (which I will probably write up more formally eventually) is to use a variant of Solomonoff induction that has access to a special procedure that simulates the domain we want (in this case, a program that simulates the game of life). Then we might expect predictors that actually use this program usefully to get shorter codes, so we can perform inference to find the predictor and then look at how the predictor uses the game of life simulator in order to detect games of life in the universe. There's a problem in that there isn't that much penalty for the model to roll its own simulator (especially if the simulation is slightly different from our model due to e.g. cosmic rays), so there are a couple tricks to give models an "incentive" for actually using this simulator. Namely, we can make this procedure cheaper to call (computationally) than a hand-rolled version, or we can provide information about the game of life state that can only get accessed by the model through our simulator. I should note that both of these tricks have serious flaws.
Some questions:
In other words, the "liberated" prefers for many cells to satisfy Game of Life rules and for many cells out of these to contain gliders.
It looks like it subtracts the total number of cells, so it prefers for there to be fewer total cells satisfying the game of life rules?
This is because replacing f with g is equivalent to adjusting probabilities by bounded factor. The bound is roughly 2^K where K is the Kolmogorov complexity of f . g^-1.
I take it this is because we're using a Solomonoff prior over universe histories? I find this statement plausible but 2^K is a pretty large factor. Also, if we define f to be a completely unreasonable function (e.g. it arranges the universe in a way so that no gliders are detected, or it chooses to simulate a whole lot of gliders or not based on some silly property of the universe), then it seems like you have proven that your utility function can never be more than a factor of 2^K away from what you'd get with f.
Thx for commenting!
Indeed de Blanc's paper explores questions which I intend to solve in this series.
I don't think your specific formula works. It looks like it either doesn't handle the multi-level nature of explanations of reality (with utility functions generally defined at the higher levels and physics at the lowest level)...
This decomposition is something I plan to address in detail in the followup post, where physics comes into the picture. However, I hope to convince you there is no problem in the formula.
...Solomonoff induction finding the true multi-level explanation from which we can just pick out the information at the level we want. But, this doesn't work because (a) Solomonoff induction will probably just find models of physics, not multi-level explanations, (b) even if it did (since we used something like the speed prior), we don't have reason to believe that they'll be the same multi-level explanations that humans use, (c) if we did something like only care about models that happen to contain game of life states in exactly the way we want (which is nontrivial given that some random noise could be plausibly viewed as a game of life history), we'd essentially be conditioning an a very weird event (that high-level information is directly part of physics and the game of life model you're using is exactly correct with no exceptions including cosmic rays), which I think might cause problems.
It seems that you are thinking about the binary sequence x as a sequence of observations made by an observer, which is the classical setup of Solomonoff induction. However, in my approach there is no fixed a priori relation between the sequence and any specific description of the physical universe.
In UDT, we consider conditional expectation values with respect to logical uncertainty of the form
val(a; U) = E(E(U) | The agent implements input-output mapping a)
where the inner E(U) is the Solomonoff expectation value from equation [1] and the outer E refers to logical uncertainty. Therefore, out of all programs contributing the the Solomonoff ensemble, the ones that contribute to the a-dependence of val are the ones that produce the universe encoded in a form compatible with f.
It looks like it subtracts the total number of cells, so it prefers for there to be fewer total cells satisfying the game of life rules?
No, it subtracts something proportional to the number of cells that don't satisfy the rules.
I take it this is because we're using a Solomonoff prior over universe histories?
Of course.
I find this statement plausible but 2^K is a pretty large factor.
It is of similar magnitude to differences between using different universal Turing machines in the definition of the Solomonoff ensemble. These difference become negligible for agents that work with large amounts of evidence.
Also, if we define f to be a completely unreasonable function (e.g. it arranges the universe in a way so that no gliders are detected, or it chooses to simulate a whole lot of gliders or not based on some silly property of the universe), then it seems like you have proven that your utility function can never be more than a factor of 2^K away from what you'd get with f.
f is required to be bijective, so it cannot lose or create information. Therefore, regardless of f, some programs in the Solomonoff ensemble will produce gliders and others won't.
Thanks for the additional explanation.
It is of similar magnitude to differences between using different universal Turing machines in the definition of the Solomonoff ensemble. These difference become negligible for agents that work with large amounts of evidence.
Hmm, I'm not sure that this is something that you can easily get evidence for or against? The 2^K factor in ordinary Solomonoff induction is usually considered fine because it can only cause you to make at most K errors. But here it's applying to utilities, which you can't get evidence for or against the same way you can for probabilities.
f is required to be bijective, so it cannot lose or create information. Therefore, regardless of f, some programs in the Solomonoff ensemble will produce gliders and others won't.
Okay, I see how this is true. But we could design f so that it only creates gliders if the universe satisfies some silly property. It seems like this would lead us to only care about universes satisfying this silly property, so the silly property would end up being our utility function.
Let me explain by the way of example.
Consider 3 possible encodings: f maps "0" bits in our sequence to empty cells and "1" bits to full cells, while traversing the cells in V in some predefined order. g is the same with 0 and 1 reversed. h computes the XOR of all bits up to a given point and uses that to define the state of the cell.
So far we haven't discussed what the agent G itself is like. Suppose G is literally a construct within the Game of Life universe. Now, our G is a UDT agent so it decides its action by computing logical uncertainty conditional expectation values of the form roughly val(a) = E(E(U) | G() = a) where "G()" stands for evaluating the program implemented by G. How does the condition "G() = a" influence E(U)? Since G actually exists within some GoL partial histories, different actions of G lead to different continuations of these histories. Depending on the choice of f,g,h these histories will map to very different binary sequences. However in all cases the effect of G's action on the number of gliders in its universe will be very similar.
It still seems like this is very much affected by the measure you assign to different game of life universes, and that the measure strongly depends on f.
Suppose we want to set f to control the agent's behavior, so that when it sees sensory data s, it takes silly action a(s), where a is a short function. To work this way, f will map game of life states in which the agent has seen s and should take action a(s) to binary strings that have greater measure, compared to game of life states in which the agent has seen s and should take some other action. I think this is almost always possible due to the agent's partial information about the world: there is nearly always an infinite number of world states in which a(s) is a good idea, regardless of s. f has a compact description (not much longer than a), and it forces the agent's behavior to be equal to a(s) (except in some unrealistic cases where the agent has very good information about the world).
What you're saying can be rephrased as follows. The prior probability measure on the space of (possibly rule-violating) Game of Life histories depends on f since it is the f-image of the Solomonoff measure. You are right. However, the dependence is as strong as the dependence of the Solomonoff measure on the choice of a universal Turing machine.
In other words, the complexity of the f you need to make G take a silly action is about the same as the complexity of the universal Turing machine you need to make G take the same action.
Given that you consider universes to be infinite binary sequences, I'm not comfortable with the restriction that a rational agent's utility function must be bounded. Unless the idea is just that this is an interesting and tractable case to look at.
I'm doubtful that a human's utility function, if there could be such a thing, would be bounded in a universe in which, for example, they lived forever (and surely some Tegmark IV universes are such). I assume that a utility function is supposed to be a rational idealization of an agent's motivations, not a literal description of any given agent. So you need not point out that no living humans seem to be risking everything, i.e. despising all finite utilities, on a plan to make living forever a little more likely.
On a more positive note - I do like your approach to humans' "native domain" and ontological problems.
Thx for commenting!
Unbounded utility functions come with a world of trouble. For example, if your utility function is computable, its Solomonoff expectation value will almost always diverge since utilities will grow as BB(Kolmogorov complexity) whereas probabilities will only fall as 2^{-Kolmogorov complexity}. Essentially, it's Pascal mugging.
It is possible to consider utility functions that give a finite extra award for living forever. For example, say that the utility for T years of life is 1 - exp(-T / tau) whereas the utility for an infinite number of years of life is 2. Such a utility function is not lower semicontinuous, but as I explained in the post it seems that we only need upper semicontinuity.
"Finite extra reward" - sneaky, I like it! I'm still in doubt, mind you. Pascal's mugging might be part of a reason to abandon cardinal utility altogether, rather than restricting it to bounded forms.
t might seem that there are "realities" of higher set theoretic cardinality which cannot be encoded. However, if we assume our agent's perceptions during a finite span of subjective time can be encoded as a finite number of bits, then we can safely ignore the "larger" realities.
Level IV is supposed to be the most general multiverse, with no conceivable superset, but observers who are not limited to finite information are conceivable for some value of conceivable.
In the first formula of "A Simple Example", the constant beta is exponentiated by t, Did you mean to use a binary sequence in betas place, instead indexing the beta symbol with t? What does the beta mean anyway? Does it encode the instants of time about which G cares, so as not to get an unbounded U (meaning you probably want to add that beta is only 1 in finitely many places)? That doesn't seem like the right solution, I wouldn't want our FAI to stop caring after Busybeaver(2^100) steps because we couldn't give it a later bound on which instants to care about. Probably more questions later, I just don't want to fall prey to Harry bias.
Thx for commenting!
The beta^t factor is exponential time discount. G cares about all instants of time, but it cares about future instants less. Indeed, without this factor the sum over time would diverge. Thus, changing beta amounts to shifting the trade-off between short-term and long-term optimization (although in the multiverse setup the effect is not very strong - see "time discount" section).
I'm having trouble understanding how you identify 'life rules' and 'gliders' in arbitrary universes encoded as arbitrary turing machines.
You say:
To accomplish this, fix a way f to bijectively encode histories of V as binary sequences. Allow arbitrary histories: don't impose Game of Life rules.
where V is the 'forward light cone'
And then:
Here W(h) is the set of cells h in which satisfies Game of Life rules,
You use W(f^-1 (x) ) to represent the idea of mapping an arbitrary universe history represented as a bit sequence x into your W function which somehow detects the set of cells satisfying game of life rules.
I think I get your idea ... but how do you actually imagine this function would work?
Defining what constitutes a 'thing' across any universe is ... hard. Can your W(..) function recognize cells in a game of life running on my computer? ( once you have established or defined 'cells' , recognizing gliders is of course easy)
In other words, how do you ground these symbols so that it works across the multiverse?
Hi Jacob!
Suppose P is a program generating some binary description X of our universe. Suppose h is a program which extracts the cell values of the game of life on your computer from X in a format compatible with f. h is relatively low complexity since apparently the cell values are "naturally" encoded in the physical universe. Therefore the composition of h and P will have a significant contribution to the Solomonoff expectation value and the agent will take it into account (since it lives in our universe and therefore makes decisions logically correlated with X).
Supernice! A step for translating utility functions from one universe to another. If we only had a unique coherent probability distribution for UTMs and those f and g - the bijective mappings between universes - the translation would be even more unique.
I did not understand those earlier intelligence metric posts of yours. This one was clear and delightful. Maybe you introduced the heavy notation slower, or maybe I just found this subject more interesting.
Thank you Antti, I'm glad you liked it!
I don't think there is a canonical version of the Solomonoff measure. When an agent maximizes expected utility with respect to a Solomonoff measure, the precise choice of Solomonoff measure is as arbitrary (agent-dependent) as the choice of utility function.
Outline: Constructing utility functions that can be evaluated on any possible universe is known to be a confusing problem, since it is not obvious what sort of mathematical object should be the domain and what properties should the function obey. In a sequence of posts, I intend break down the question with respect to Tegmark's multiverse levels and explain the answer on each level, starting with level IV in the current post.
Background
An intelligent agent is often described as an entity whose actions drive the universe towards higher expectation values of a certain function, known as the agent's utility function. Such a description is very useful in contexts such as AGI, FAI, decision theory and more generally any abstract study of intelligence.
Applying the concept of a utility function to agents in the real worlds requires utility functions with a very broad domain. Indeed, since the agent is normally assumed to have only finite information about the universe in which it exists, it should allow for a very large variety of possible realities. If the agent is to make decisions using some sort of utility calculus, it has to be able to evaluate its utility function on each of the realities it can conceive.
Tegmark has conveniently arranged the space of possible realities ("universes") into 4 levels, 3 of which are based on our current understanding of physics. Tegmark's universes are usually presented as co-existing but it is also possible to think of them as the "potential" universes in which our agent can find itself. I am going to traverse Tegmark's multiverse from top to bottom, studying the space of utility functions on each level (which, except for level IV, is always derived from the higher level). The current post addresses Tegmark level IV, leaving the lower levels for follow-ups.
Some of the ideas in this post previously appeared in a post about intelligence metrics, where I explained them much more tersely.
Tegmark Level IV
Tegmark defined this level as the collection of all mathematical models. Since it is not even remotely clear how to define such a beast, I am going to use a different space which (I claim) is conceptually very close. Namely, I am going to consider universes to be infinite binary sequences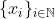 . I denote the by
. I denote the by 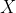 the space of all such sequences equipped with the product topology. As will become clearer in the following, this space embodies "all possible realities" since any imaginable reality can be encoded in such a sequence1.
the space of all such sequences equipped with the product topology. As will become clearer in the following, this space embodies "all possible realities" since any imaginable reality can be encoded in such a sequence1.
The natural a priori probability measure on this space is the Solomonoff measure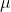 . Thus, a priori utility expectation values take the form
. Thus, a priori utility expectation values take the form
[1] d\mu(x))
From the point of view of Updateless Decision Theory, a priori expectation values are the only sort that matters: conditional expectation values wrt logical uncertainty replace the need to update the measure.
In order to guarantee the convergence of expectation values, we are going to assume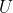 is a bounded function.
is a bounded function.
A Simple Example
So far, we know little about the form of the function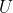 . To illustrate the sort of constructions that are relevant for realistic or semi-realistic agents, I am going to consider a simple example: the glider maximizer.
. To illustrate the sort of constructions that are relevant for realistic or semi-realistic agents, I am going to consider a simple example: the glider maximizer.
The glider maximizer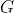 is an agent living inside the Game of Life. Fix
is an agent living inside the Game of Life. Fix 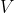 a forward light cone within the Game of Life spacetime, representing the volume
a forward light cone within the Game of Life spacetime, representing the volume 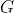 is able to influence.
is able to influence. 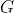 maximizes the following utility function:
maximizes the following utility function:
Here,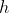 is a history of the Game of Life,
is a history of the Game of Life,  is a constant in
is a constant in ) and
and ) is the number of gliders at time
is the number of gliders at time 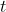 inside
inside 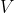 .
.
We wish to "release"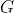 from the Game of Life universe into the broader multiverse. In order words, we want an agent that doesn't dogmatically assume itself to exist with the Game of Life, instead searching for appearances of the Game of Life in the physical universe and maximizing gliders there.
from the Game of Life universe into the broader multiverse. In order words, we want an agent that doesn't dogmatically assume itself to exist with the Game of Life, instead searching for appearances of the Game of Life in the physical universe and maximizing gliders there.
To accomplish this, fix a way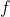 to bijectively encode histories of
to bijectively encode histories of 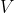 as binary sequences. Allow arbitrary histories: don't impose Game of Life rules. We can then define the "multiversal" utility function
as binary sequences. Allow arbitrary histories: don't impose Game of Life rules. We can then define the "multiversal" utility function
Here) is the set of cells in which
is the set of cells in which 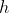 satisfies Game of Life rules,
satisfies Game of Life rules, 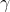 is a positive constant and
is a positive constant and ) is the number of cells in
is the number of cells in ) at time
at time 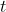 .
.
In other words, the "liberated"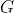 prefers for many cells to satisfy Game of Life rules and for many cells out of these to contain gliders.
prefers for many cells to satisfy Game of Life rules and for many cells out of these to contain gliders.
Superficially, it seems that the construction of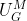 strongly depends on the choice of
strongly depends on the choice of 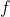 . However, the dependence only marginally affects
. However, the dependence only marginally affects 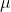 -expectation values. This is because replacing
-expectation values. This is because replacing 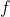 with
with 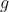 is equivalent to adjusting probabilities by bounded factor. The bound is roughly
is equivalent to adjusting probabilities by bounded factor. The bound is roughly 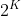 where
where 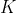 is the Kolmogorov complexity of
is the Kolmogorov complexity of 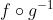 .
.
Human Preferences and Dust Theory
Human preferences revolve around concepts which belong to an "innate" model of reality: a model which is either genetic or acquired by brains at early stages of childhood. This model describes the world mostly in terms of humans, their emotions and interactions (but might include other elements as well e.g. elements related to wild nature).
Therefore, utility functions which are good descriptions of human preferences ("friendly" utility functions) are probably of similar form to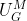 from the Game of Life example, with Game of Life replaced by the "innate human model".
from the Game of Life example, with Game of Life replaced by the "innate human model".
Applying UDT to the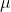 -expectation values of such utility functions leads to agents which care about anything that has a low-complexity decoding into an "innate concept" e.g. biological humans and whole brain emulations. The
-expectation values of such utility functions leads to agents which care about anything that has a low-complexity decoding into an "innate concept" e.g. biological humans and whole brain emulations. The 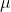 -integral assigns importance to all possible "decodings" of the universe weighted by their Kolmogorov complexity which is slightly reminiscent of Egan's dust theory.
-integral assigns importance to all possible "decodings" of the universe weighted by their Kolmogorov complexity which is slightly reminiscent of Egan's dust theory.
The Procrastination Paradox
Consider an agent living in a universe I call "buttonverse".
living in a universe I call "buttonverse".  can press a button at any moment of time
can press a button at any moment of time 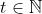 .
.  's utility function
's utility function 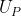 assigns 1 to histories in which the button was pressed at least once and 0 to histories in which the button was never pressed. At each moment of time, it seems rational for
assigns 1 to histories in which the button was pressed at least once and 0 to histories in which the button was never pressed. At each moment of time, it seems rational for  to decide not to press the button since it will have the chance to do so at a later time without losing utility. As a result, if
to decide not to press the button since it will have the chance to do so at a later time without losing utility. As a result, if  never presses the button its behavior seems rational at any particular moment but overall leads to losing. This problem (which has important ramifications for tiling agents) is known as the procrastination paradox.
never presses the button its behavior seems rational at any particular moment but overall leads to losing. This problem (which has important ramifications for tiling agents) is known as the procrastination paradox.
My point of view on the paradox is that it is the result of a topological pathology of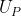 . Thus, if we restrict ourselves to reasonable utility functions (in the precise sense I explain below), the paradox disappears.
. Thus, if we restrict ourselves to reasonable utility functions (in the precise sense I explain below), the paradox disappears.
Buttonverse histories are naturally described as binary sequences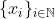 where
where 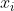 is 0 when the button is not pressed at time
is 0 when the button is not pressed at time 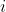 and 1 when the button is pressed at time
and 1 when the button is pressed at time 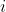 . Define
. Define  to be the buttonverse history in which the button is never pressed:
to be the buttonverse history in which the button is never pressed:
Consider the following sequence of buttonverse histories: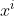 is the history in which the button gets pressed at time
is the history in which the button gets pressed at time 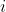 only. That is
only. That is
Now, with respect to the product topology on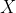 ,
, 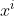 converge to the
converge to the  :
:
However the utilities don't behave correspondingly:
Therefore, it seems natural to require any utility function to be an upper semicontinuous function on X 2. I claim that this condition resolves the paradox in the precise mathematical sense considered in Yudkowsky 2013. Presenting the detailed proof would take us too far afield and is hence out of scope for this post.
Time Discount
Bounded utility functions typically contain some kind of temporal discount. In the Game of Life example, the discount manifests as the factor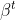 . It is often assumed that the discount has to take an exponential form in order to preserve time translation symmetry. However, the present formalism has no place for time translation symmetry on the fundamental level: our binary sequences have well-defined beginnings. Obviously this doesn't rule out exponential discount but the motivation for sticking to this particular form is weakened.
. It is often assumed that the discount has to take an exponential form in order to preserve time translation symmetry. However, the present formalism has no place for time translation symmetry on the fundamental level: our binary sequences have well-defined beginnings. Obviously this doesn't rule out exponential discount but the motivation for sticking to this particular form is weakened.
Note that any sequence contributes to the
contributes to the 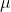 -integral in [1] together with its backward translated versions
-integral in [1] together with its backward translated versions ) :
:
As a result, the temporal discount function effectively undergoes convolution with the function}) where
where ) is the Kolmogorov complexity of the number
is the Kolmogorov complexity of the number 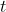 . As a result, whatever the form of "bare" temporal discount, the effective temporal discount falls very slowly3.
. As a result, whatever the form of "bare" temporal discount, the effective temporal discount falls very slowly3.
In other words, if a utility function assigns little or no importance to the distant future, a UDT agent maximizing the expectation value of
assigns little or no importance to the distant future, a UDT agent maximizing the expectation value of  would still care a lot about the distant future, because what is distant future in one universe in the ensemble is the beginning of the sequence in another universe in the ensemble.
would still care a lot about the distant future, because what is distant future in one universe in the ensemble is the beginning of the sequence in another universe in the ensemble.
Next in sequence: The Role of Physics in UDT, Part I
1 It might seem that there are "realities" of higher set theoretic cardinality which cannot be encoded. However, if we assume our agent's perceptions during a finite span of subjective time can be encoded as a finite number of bits, then we can safely ignore the "larger" realities. They can still exist as models the agent uses to explain its observations but it is unnecessary to assume them to exist on the "fundamental" level.
2 In particular, all computable functions are admissible since they are continuous.
3 I think that}) falls slower than any computable function with convergent integral.
falls slower than any computable function with convergent integral.