This is a linkpost for https://www.anthropic.com/constitutional.pdf
On the one hand, cool, on the other, the abstract is deceptive because it tries to claim that the AI trained is "harmless but nonevasive AI assistant" but what the paper in fact claims is that Anthropic trained an AI that has a higher harmlessness and helpfulness score and thus offers a Pareato improvement over previous models but is not definitely across some bar we could say is harmless vs. not-harmless or helpful vs. not-helpful. As much is also stated in the included figure.
The work is cool, don't get me wrong. We should celebrate it. But also I want abstracts that aren't deceptive and add the necessary words to precisely explain what is being claimed in the paper. I'd be much happier if the abstract read something like "to train a more harmless and less evasive AI assistant than previous attempts that engages with harmful queries by more often explaining its objections to them than avoiding answering" or something similar.
I really do empathize with the authors, since writing an abstract fundamentally requires trading off faithfulness to the paper content and the length and readability of the abstract. But I do agree that they could've been more precise without a significant increase in length.
Nitpick: I think instead of expanding on the sentence
As a result we are able to train a more harmless and less evasive AI assistant than previous attempts that engages with harmful queries by more often explaining its objections to them than avoiding answering
My proposed rewrite is to replace that sentence with something like:
As a result, we were able to train an AI assistant is simultaneously less harmful and evasive. Even on adversarial queries, our model generally provides nuanced explanations instead of evading the question.
I think this is ~ the same length and same level of detail but a lot easier to parse.
I'm really appreciating the series of brief posts on Alignment relevant papers plus summaries!
A thing I really like about the approach in this paper is that it makes use of a lot more of the model's knowledge of human values than traditional RLHF approaches. Pretrained LLM's already know a ton of what humans say about human values, and this seems like a much more direct way to point models at that knowledge than binary feedback on samples.
The mad lads! Now you just need to fold the improved model back to improve the ratings used to train it, and you're ready to take off to the moon*.
*We are not yet ready to take off to the moon. Please do not depart for the moon until we have a better grasp on tracking uncertainty in generative models, modeling humans, applying human feedback to the reasoning process itself, and more.
IIUC, there are two noteworthy limitations of this line of work:
Did I understand correctly?
It doesn't give any confidence about behavior at edge cases (e.g. is it ethical to help plan an insurrection against an oppressive regime? Is it racist to give accurate information in a way that portrays some minority in a bad light)
If I was handling the edge cases, I'd probably want the solution to be philosophically conservative. In this case the solution should not depend much on whether moral realism is correct or wrong.
Here's a link to philosophical conservatism:
I think I disagree with large parts of that post, but even if I didn't, I'm asking something slightly different. Philosophical conservativism seems to be asking "how do we get the right behaviors at the edges?" I'm asking "how do we get any particular behavior at the edges?"
One answer may be "You can't, you need philosophical conservativism", but I don't buy that. It seems to me that a "constitution", i.e. pure deontology, is a potential answer so long as the exponentially many interactions of the principles are analyzed (I don't think it's a good answer, all told), but if I understand this work, it doesn't generalize that far (because there would need to be training examples for each class of edge cases, of which there are too many).
Basically, we should use the assumption that is most robust to being wrong. It would be easier if there were objective, mind independent rules of morality, called moral realism, but if that assumption is wrong, your solution can get manipulated.
So in practice, we shouldn't try to base alignment plans on whether moral realism is correct. In other words I'd simply go with what values you have and solve the edge cases according to your values.
I feel like we're talking past each other. I'm trying to point out the difficulty of "simply go with what values you have and solve the edge cases according to your values" as a learning problem: it is too high dimension, and you need too many case labels; part of the idea of the OP is to reduce the number of training cases required, and my question/suspicion is that it doesn't doesn't really help outside of the "easy" stuff.
The authors propose a method for training a harmless AI assistant that can supervise other AIs, using only a list of rules (a "constitution") as human oversight. The method involves two phases: first, the AI improves itself by generating and revising its own outputs; second, the AI learns from preference feedback, using a model that compares different outputs and rewards the better ones. The authors show that this method can produce a non-evasive AI that can explain why it rejects harmful queries, and that can reason in a transparent way, better than standard RLHF: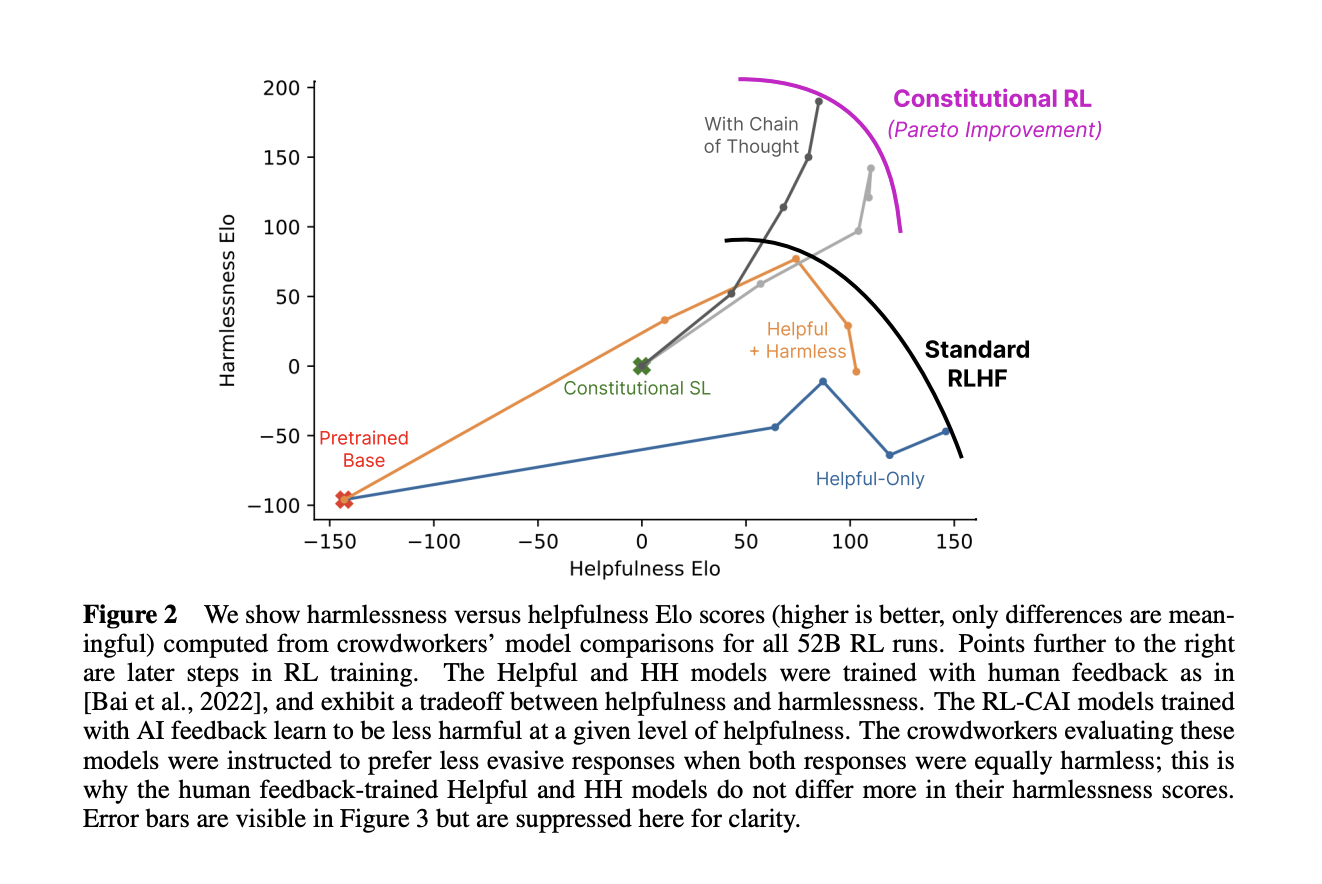
Paper abstract:
See also Anthropic's tweet thread:
https://twitter.com/AnthropicAI/status/1603791161419698181