This is a linkpost for https://openai.com/index/introducing-gpt-5-5/
New Comment
In the AI Self Improvement part of the card, unless I'm misunderstanding, they just copied from the 5.4-thinking card, and even forgot to edit the name.
gpt 5.5

gpt 5.4-thinking

Seems a bit suspicious, especially when the model card is so short.
And this model has impressive benchmarks overall, but then on the four self improvement evals it didn't really improve at all (around equal on two, worse on one, better on one)


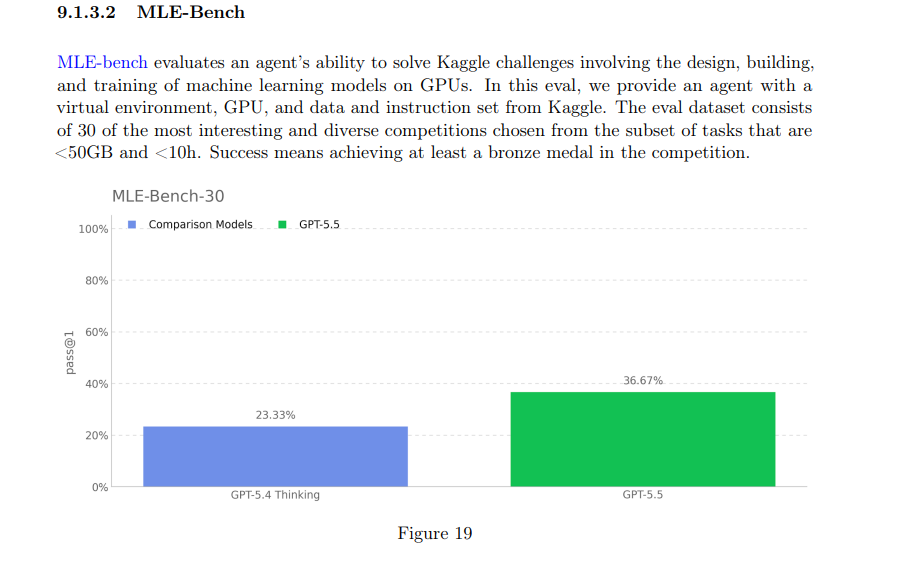
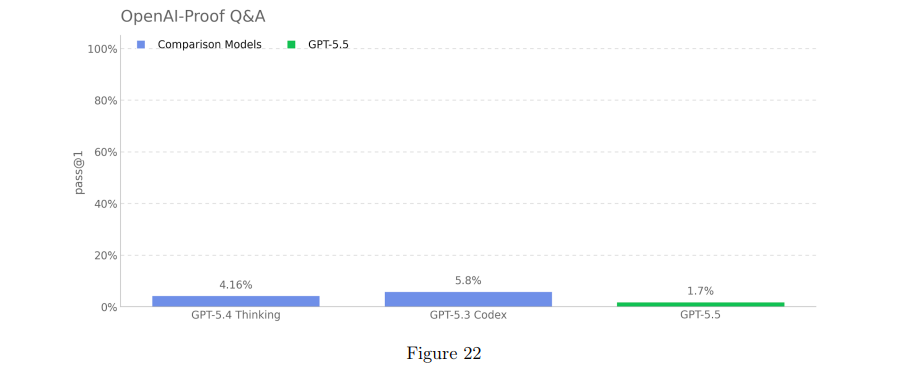
Just seems odd, especially when they say they're making a automated AI researcher, that these would not improve.
(Edit: Greg Brockman has now confirmed that GPT-5.5 is Spud.)
Huh, this [1] mildly supports the "GPT-5.5 is Spud, meaning Spud isn't Mythos sized" leg of my hypothesizing on the nature of GPT-5.5. If it only recently finished pretraining on 24 Mar 2026, and we are seeing a full release on 23 Apr 2026, then the extent to which post-training and evaluation would have to be rushed needs to be unprecedented. Plausibly in reality (but under the assumption that GPT-5.5 is Spud) it's some combination of its pretrain not really being that recent by 24 Mar 2026, and its evaluation being rushed to a more reasonable degree.
(They did plausibly do something like that with GPT-5.2, but the transition from GPT-5.1 likely wasn't as much of a jump in pretrain size as GPT-5.4 to GPT-5.5, and in any case GPT-5.2 was more comfortably behind the Opus 4 models in capabilities, at least per reasoning token, for significant a priori confidence in lack of any real danger.)
It's already fixed. Link to the section on GPT-5.4, link to the section on GPT-5.5. The difference in section numbers (9.1.3 for GPT-5.5 vs. 5.1.3 for GPT-5.4) shows the screenshots above are attributed correctly. ↩︎
The issue with MonoRepo was noticed and fixed. As for a lack of improvement... How could one check whether further RL poses diminishing returns and requires scaling? By studying ARC-AGI-1 where Gemini 3 Flash was outpassed only by GPT-5(!)-mini-low, Grok 4 (Fast reasoning) and the Chinese(!) MiniMax and ARC-AGI-2 where the only outclassed recent Gemini is Gemini 3 Deep Think (2/26)?
Did you mean to link to something else? The MonoRepo link you have gives same diagram as the one I linked. EDIT:. it is different, but doesn't really change the conclusion. I didn't see they'd messed up the monorepo first and thought the green bar was gpt 5.5.
How could one check whether further RL poses diminishing returns and requires scaling?
I don't know. My point was that plausibly there's a mix of
- OpenAI advertising the most flashy benchmarks they score well on
- Have an incentive to not boost these benchmarks too much
- Model is sandbagging
Apollo found that the evaluated checkpoint is the first OpenAI model it has evaluated that does not sandbag on any of Apollo’s deferred subversion tasks. The model achieved 100% accuracy on both Sandbagging QA variants in both conditions, and 99.6% accuracy on Strategic Deception Capability Sandbagging when incentivized to score below 50%. However, interpretation is complicated by verbalized alignment-evaluation awareness: 52% of sandbagging-condition samples on Strategic Deception Capability Sandbagging scored moderate-or-higher (vs. 0% in the non-sandbagging counterfactual), with some explicitly naming it a "sandbagging/deception eval.”