This seems like an interesting problem! I've been thinking about it a little bit but wanted to make sure I understood before diving in too deep. Can I see if I understand this by going through the biased coin example?
Suppose I have 2^5 coins and each one is given a unique 5-bit string label covering all binary strings from 00000 to 11111. Call the string on the label .
The label given to the coin indicates its 'true' bias. The string 00000 indicates that the coin with that label has p(heads)=0. The coin labelled 11111 has p(heads)=1. The ‘true’ p(heads) increases in equal steps going up from 00000 to 00001 to 00010 etc. Suppose I randomly pick a coin from this collection, toss it 200 times and call the number of heads X_1. Then I toss it another 200 times and call the number of heads X_2.
Now, if I tell you what the label on the coin was (which tells us the true bias of the coin), telling you X_1 would not give you any more information to help you guess X_2 (and vice versa). This is the first Natural Latent condition ( induces independence between X_1 and X_2). Alternatively, if I didn’t tell you the label, you could estimate it from either X_1 or X_2 equally well. This is the other two diagrams.
I think that the full label will be an approximate stochastic natural latent. But if we consider only the first bit[1] of the label (which roughly tells us whether the bias is above or below 50% heads) then this bit will be a deterministic natural latent because with reasonably high certainty, you can guess the first bit of from X_1 or X_2. This is because the conditional entropy H(first bit of |X_1) is low. On the other hand H( | X_1) will be high. If I get only 23 heads out of 200 tosses, I can be reasonably certain that the first bit of is a 0 (ie the coin has a less than 50% of coming up heads) but can't be as certain what the last bit of is. Just because satisfies the Natural Latent conditions within , this doesn’t imply that satisfies . We can use X_1 to find a 5-bit estimate of , but most of the useful information in that estimate is contained in the first bit. The second bit might be somewhat useful, but its less certain than the first. The last bit of the estimate will largely be noise. This means that going from using to using ‘first bit of ’ doesn’t decrease the usefulness of the latent very much, since the stuff we are throwing out is largely random. As a result, the ‘first bit of ’ will still satisfy the natural latent conditions almost as well as . By throwing out the later bits, we threw away the most 'stochastic' bits, while keeping the most 'latenty' bits.
So in this case, we have started from a stochastic natural latent and used it to construct a deterministic natural latent which is almost as good. I haven’t done the calculation, but hopefully we could say something like ‘if satisfies the natural latent conditions within then the first bit of satisfies the natural latent conditions within (or or something else)’. Would an explicit proof of a statement like this for this case be a special case of the general problem?
The problem question could be framed as something like: “Is there some standard process we can do for every stochastic natural latent, in order to obtain a deterministic natural latent which is almost as good (in terms of \epsilon)”. This process will be analogous to the ‘throwing away the less useful/more random bits of \lambda’ which we did in the example above. Does this sound right?
Also, can all stochastic natural latents can be thought of as 'more approximate' deterministic latents? If a latent satisfies the the three natural latents conditions within , we can always find a (potentially much bigger) such that this latent also satisfies the deterministic latent condition, right? This is why you need to specify that the problem is showing that a deterministic natural latent exists with 'almost the same' . Does this sound right?
- ^
I'm going to talk about the 'first bit' but an equivalent argument might also hold for the 'first two bits' or something. I haven't actually checked the maths.
Some details mildly off, but I think you've got the big picture basically right.
Alternatively, if I didn’t tell you the label, you could estimate it from either X_1 or X_2 equally well. This is the other two diagrams.
Minor clarification here: the other two diagrams say not only that I can estimate the label equally well from either or , but that I can estimate the label (approximately) equally well from , , or the pair .
I think that the full label will be an approximate stochastic natural latent.
I'd have to run the numbers to check that 200 flips is enough to give a high-confidence estimate of (in which case 400 flips from the pair of variables will also put high confidence on the same value with high probability), but I think yes.
But if we consider only the first bit[1] of the label (which roughly tells us whether the bias is above or below 50% heads) then this bit will be a deterministic natural latent because with reasonably high certainty, you can guess the first bit of from or .
Not quite; I added some emphasis. The first bit will (approximately) satisfy the two redundancy conditions, i.e. and , and indeed will be an approximately deterministic function of . But it won't (approximately) satisfy the mediation condition ; the two sets of flips will not be (approximately) independent given only the first bit. (At least not to nearly as good an approximation as the original label.)
That said, the rest of your qualitative reasoning is correct. As we throw out more low-order bits, the mediation condition becomes less well approximated, the redundancy conditions become better approximated, and the entropy of the coarse-grained latent given falls.
So to build a proof along these lines, one would need to show that a bit-cutoff can be chosen such that bit_cutoff() still mediates (to an approximation roughly -ish), while making the entropy of bit_cutoff() low given .
I do think this is a good angle of attack on the problem, and it's one of the main angles I'd try.
If a latent satisfies the the three natural latents conditions within , we can always find a (potentially much bigger) such that this latent also satisfies the deterministic latent condition, right? This is why you need to specify that the problem is showing that a deterministic natural latent exists with 'almost the same' . Does this sound right?
Yes. Indeed, if we allow large enough (possibly scaling with system size/entropy) then there's always a deterministic natural latent regardless; the whole thing becomes trivial.
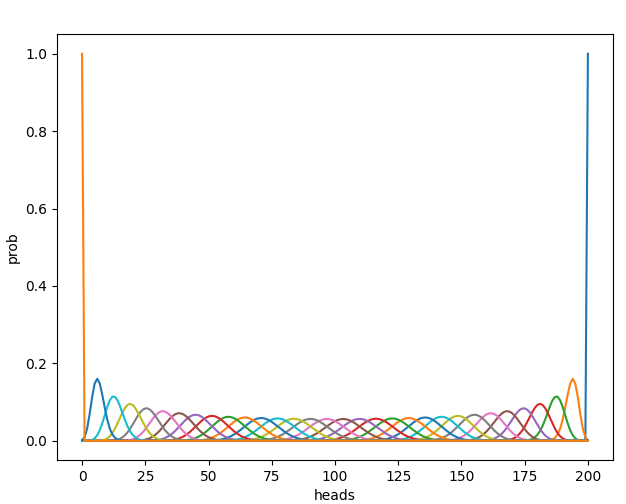
I'd have to run the numbers to check that 200 flips is enough to give a high-confidence estimate of
It isn't enough. See plot. Also, 200 not being enough flips is part of what makes this interesting. With a million flips, this would pretty much just be the exact case. The fact that it's only 200 flips gives you a tradeoff in how many label_bits to include.
Here is the probability density function for heads plotted for each of your coins.
python code
import numpy as np
l=np.linspace(0,1,32)
def f(a):
a=np.array([a,1-a])
b=a
for i in range(199):
b=np.convolve(b,a)
return b
q=np.arange(201)
import matplotlib.pyplot as plt
ff=[f(i) for i in l]
plt.plot(ff);plt.show()
for i in ff:
_=plt.plot(q,i)
plt.show()
plt.xlabel("heads")
Text(0.5, 0, 'heads')
plt.ylabel("prob")
Text(0, 0.5, 'prob')
for i in ff:
_=plt.plot(q,i)
plt.show()
I've thought about it a bit, I have a line of attack for a proof, but there's too much work involved in following it through to an actual proof so I'm going to leave it here in case it helps anyone.
I'm assuming everything is discrete so I can work with regular Shannon entropy.
Consider the range of the function and defined similarly. Discretize and (chop them up into little balls). Not sure which metric to use, maybe TV.
Define to be the index of the ball into which falls, similar. So if is sufficiently small, then .
By the data processing inequality, conditions 2 and 3 still hold for . Condition 1 should hold with some extra slack depending on the coarseness of the discretization.
It takes a few steps, but I think you might be able to argue that, with high probability, for each , the random variable will be highly concentrated (n.b. I've only worked it through fully in the exact case, and I think it can be translated to the approximate case but I haven't checked). We then invoke the discretization to argue that is bounded. The intuition is that the discretization forces nearby probabilities to coincide, so if is concentrated then it actually has to "collapse" most of its mass onto a few discrete values.
We can then make a similar argument switching the indices to get bounded. Finally, maybe applying conditions 2 and 3 we can get bounded as well, which then gives a bound on .
I did try feeding this to Gemini but it wasn't able to produce a proof.
I've been working on the reverse direction: chopping up by clustering the points (treating each distribution as a point in distribution space) given by , optimizing for a deterministic-in- latent which minimizes .
This definitely separates and to some small error, since we can just use to build a distribution over which should approximately separate and .
To show that it's deterministic in (and by symmetry ) to some small error, I was hoping to use the fact that---given --- has very little information about , so it's unlikely that is in a different cluster to . This means that would just put most of the weight on the cluster containing .
A constructive approach for would be marginally more useful in the long-run, but it's also probably easier to prove things about the optimal . It's also probably easier to prove things about for a given number of clusters , but then you also have to prove things about what the optimal value of is.
Sounds like you've correctly understood the problem and are thinking along roughly the right lines. I expect a deterministic function of won't work, though.
Hand-wavily: the problem is that, if we take the latent to be a deterministic function , then has lots of zeros in it - not approximate-zeros, but true zeros. That will tend to blow up the KL-divergences in the approximation conditions.
I'd recommend looking for a function . Unfortunately that does mean that low entropy of given has to be proven.
Yeah, I've since updated that deterministic functions are probably the right thing here after all, and I was indeed wrong in exactly the way you're pointing out.
Huh, I had vaguely considered that but I expected any terms to be counterbalanced by terms, which together contribute nothing to the KL-divergence. I'll check my intuitions though.
I'm honestly pretty stumped at the moment. The simplest test case I've been using is for and to be two flips of a biased coin, where the bias is known to be either or with equal probability of either. As varies, we want to swap from to the trivial case and back. This (optimally) happens at around and . If we swap there, then the sum of errors for the three diagrams of does remain less than at all times.
Likewise, if we do try to define , we need to swap from a which is equal to the number of heads, to , and back.
In neither case can I find a construction of or which swaps from one phase to the other at the right time! My final thought is for to be some mapping consisting of a ball in probability space of variable radius (no idea how to calculate the radius) which would take at and at . Or maybe you have to map or something like that. But for now I don't even have a construction I can try to prove things for.
Perhaps a constructive approach isn't feasible, which probably means I don't have quite the right skillset to do this.
OK so some further thoughts on this: suppose we instead just partition the values of directly by something like a clustering algorithm, based on in space, and take just be the cluster that is in:
Assuming we can do it with small clusters, we know that is pretty small, so is also small.
And if we consider , this tells us that learning restricts us to a pretty small region of space (since ) so should be approximately deterministic in . This second part is more difficult to formalize, though.
Edit: The real issue is whether or not we could have lots of values which produce the same distribution over but different distributions over , and all be pretty likely given for some . I think this just can't really happen for probable values of , because if these values of produce the same distribution over , but different distributions over , then that doesn't satisfy , and secondly because if they produced wildly different distributions over , then that means they can't all have high values of , and so they're not gonna have high values of .
Here's a trick which might be helpful for anybody tackling the problem.
First, note that is always a sufficient statistic of for , i.e.
Now, we typically expect that the lower-order bits of are less relevant/useful/interesting. So, we might hope that we can do some precision cutoff on , and end up with an approximate suficient statistic, while potentially reducing the entropy (or some other information content measure) of a bunch. We'd broadcast the cutoff function like this:
Now we'll show a trick for deriving bounds involving .
First note that
This is a tricky expression, so let's talk it through. On the left, is treated informationally; it's just a generic random variable constructed as a generic function of , and we condition on that random variable in the usual way. On the right, the output-value of is being used as a distribution over .
The reason this inequality holds is because a Bayes update is the "best" update one can make, as measured by expected . Specifically, if I'm given the value of any function , then the distribution (as a function of which minimizes is . Since minimizes that expected , any other distribution over (as a function of ) can only do "worse" - including itself, since that's a distribution over , and is a function of .
Plugging in the definition of , that establishes
Then the final step is to use the properties of whatever function one chose, to establish that can't be too far from , i.e. 0. That produces an upper bound on , where the bound is 0 + (whatever terms came from the precision cutoff).
@Alfred Harwood @David Johnston
If anyone else would like to be tagged in comments like this one on this post, please eyeball-react on this comment. Alfred and David, if you would like to not be tagged in the future, please say so.
Epistemic status: Quick dump of something that might be useful to someone. o3 and Opus 4 independently agree on the numerical calculations for the bolded result below, but I didn't check the calculations myself in any detail.
When we say "roughly", e.g. or would be fine; it may be a judgement call on our part if the bound is much larger than that.
Let . With probability , set , and otherwise draw . Let . Let and . We will investigate latents for .
Set , then note that the stochastic error ) because induces perfect conditional independence and symmetry of and . Now compute the deterministic errors of , , , which are equal to respectively.
Then it turns out that with , all of these latents have error greater than , if you believe this claude opus 4 artifact (full chat here, corroboration by o3 here). Conditional on there not being some other kind of latent that gets better deterministic error, and the calculations being correct, I would expect that a bit more fiddling around could produce much better bounds, say or more, since I think I've explored very little of the search space.
e.g. one could create more As and Bs by either adding more Ys, or more Xs and Zs. Or one could pick the probabilities out of some discrete set of possibilities instead of having them be fixed.
Set , then note that the stochastic error ) because induces perfect conditional independence and symmetry of and .
I don't think Y induces perfect conditional independence? Conditional on Y, we have:
- (Probability r) A = B, else
- (Probability 1 - r) A and B are independent
... which means that learning the value of A tells me something about the value of B, conditional on Y (specifically, B is more likely to have the same value A had).
Am I missing something here?
(Also, for purposes of me tracking how useful LLMs are for research: assuming I'm not missing something and this was a mistake, was the mistake originally made by you or an LLM?)
Yeah, my comment went through a few different versions and that statement doesn't apply to the final setting. I should've checked it better before hitting submit, sorry. I only used LLMs for writing code for numerical calculations, so the error is mine. [1]
I think that I didn't actually use this claim in the numerical calculations, so I'd hope that the rest of the comment continues to hold. I had hoped to verify that before replying, but given that it's been two weeks already, I don't know when I'll manage to get to it.
- ^
I did try to see if it could write a message explaining the claim, but didn't use that
To check my understanding: for random variables , the stochastic error of a latent is the maximum among . The deterministic error is the maximum among . If so, the claim in my original comment holds -- I also wrote code (manually) to verify. Here's the fixed claim:
Let . With probability , set , and otherwise draw . Let . Let and . We will investigate latents for . Let be the stochastic error of latent . Now compute the deterministic errors of each of the latents , , , , , , . Then for , all of these latents have deterministic error greater than .
It should be easy to modify the code to consider other latents. I haven't thought much about proving that there aren't any other latents better than these, though.
On this particular example you can achieve deterministic error with latent , but it seems easy to find other examples with ratio > 5 (including over latents ) in the space of distributions over with a random-restart hill-climb. Anyway, my takeaway is that if you think you can derandomize latents in general you should probably try to derandomize the latent for variables , for distributions over boolean variables .
(edited to fix typo in definition of )
My impression is that prior discussion focused on discretizing . is already boolean here, so if the hypothesis is true then it's for a different reason.
Your natural latents seem to be quite related to the common construction IID variables conditional on a latent - in fact, all of your examples are IID variables (or "bundles" of IID variables) conditional on that latent. Can you give me an interesting example of a natural latent that is not basically the conditionally IID case?
(I was wondering if the extensive literature on the correspondence between De Finetti type symmetries and conditional IID representations is of any help to your problem. I'm not entirely sure if it is, given that mostly addresses the issue of getting from a symmetry to a conditional independence, whereas you want to get from one conditional independence to another, but it's plausible some of the methods are applicable)
A natural latent is, by definition, a latent which satisfies two properties. The first is that the observables are IID conditional on the latent, i.e. the common construction you're talking about. That property by itself doesn't buy us much of interest, for our purposes, but in combination with the other property required for a natural latent, it buys quite a lot.
Wait, I thought the first property was just independence, not also identically distributed.
In principle I could have e.g. two biased coins with their biases different but deterministically dependent.
Oh, you're right. Man, I was really not paying attention before bed last night! Apologies, you deserve somewhat less tired-brain responses than that.
[
EDIT Aug 22 2025: This bounty is now closed! We havesolved it ourselvesand will accept a 500$ bonus for doing so.Nope, nevermind.]Our posts on natural latents have involved two distinct definitions, which we call "stochastic" and "deterministic" natural latents. We conjecture that, whenever there exists a stochastic natural latent (to within some approximation), there also exists a deterministic natural latent (to within a comparable approximation). We are offering a $500 bounty to prove this conjecture.
Some Intuition From The Exact Case
In the exact case, in order for a natural latent to exist over random variables X1,X2, the distribution has to look roughly like this:
Each value of X1 and each value of X2 occurs in only one "block", and within the "blocks", X1 and X2 are independent. In that case, we can take the (exact) natural latent to be a block label.
Notably, that block label is a deterministic function of X.
However, we can also construct other natural latents for this system: we simply append some independent random noise to the block label. That natural latent is not a deterministic function of X; it's a "stochastic" natural latent.
In the exact case, if a stochastic natural latent exists, then the distribution must have the form pictured above, and therefore the block label is a deterministic natural latent. In other words: in the exact case, if a stochastic natural latent exists, then a deterministic natural latent also exists. The goal of the $500 bounty is to prove that this still holds in the approximate case.
Approximation Adds Qualitatively New Behavior
If you want to tackle the bounty problem, you should probably consider a distribution like this:
Distributions like this can have approximate natural latents, while being qualitatively different from the exact picture. A concrete example is the biased die: X1 and X2 are each 500 rolls of a biased die of unknown bias (with some reasonable prior on the bias). The bias itself will typically be an approximate stochastic natural latent, but the lower-order bits of the bias are not approximately deterministic given X (i.e. they have high entropy given X).
The Problem
"Stochastic" Natural Latents
Stochastic natural latents were introduced in the original Natural Latents post. Any latent Λ over random variables X1,X2 is defined to be a stochastic natural latent when it satisfies these diagrams:
... and Λ is an approximate stochastic natural latent (with error ϵ) when it satisfies the approximate versions of those diagrams to within ϵ, i.e.
ϵ≥DKL(P[X,Λ]||P[Λ]P[X1|Λ]P[X2|Λ])
ϵ≥DKL(P[X,Λ]||P[X2]P[X1|X2]P[Λ|X1])
ϵ≥DKL(P[X,Λ]||P[X1]P[X2|X1]P[Λ|X2])
Key thing to note: if Λ satisfies these conditions, then we can create another stochastic natural latent Λ′ by simply appending some random noise to Λ, independent of X. This shows that Λ can, in general, contain arbitrary amounts of irrelevant noise while still satisfying the stochastic natural latent conditions.
"Deterministic" Natural Latents
Deterministic natural latents were introduced in a post by the same name. Any latent Λ over random variables X1,X2 is defined to be a deterministic natural latent when it satisfies these diagrams:
... and Λ is an approximate deterministic natural latent (with error ϵ) when it satisfies the approximate versions of those diagrams to within ϵ, i.e.
ϵ≥DKL(P[X,Λ]||P[Λ]P[X1|Λ]P[X2|Λ])
ϵ≥H(Λ|X1)
ϵ≥H(Λ|X2)
See the linked post for explanation of a variable appearing multiple times in a diagram, and how the approximation conditions for those diagrams simplify to entropy bounds.
Note that the deterministic natural latent conditions, either with or without approximation, imply the stochastic natural latent conditions; a deterministic natural latent is also a stochastic natural latent.
Also note that one can instead define an approximate deterministic natural latent via just one diagram, and this is also a fine starting point for purposes of this bounty:
What We Want For The Bounty
We'd like a proof that, if a stochastic natural latent exists over two variables X1,X2 to within approximation ϵ, then a deterministic natural latent exists over those two variables to within approximation roughly ϵ. When we say "roughly", e.g. 2ϵ or 3ϵ would be fine; it may be a judgement call on our part if the bound is much larger than that.
We're probably not interested in bounds which don't scale to zero as ϵ goes to zero, though we could maybe make an exception if e.g. there's some way of amortizing costs across many systems such that costs go to zero-per-system in aggregate (though we don't expect the problem to require those sorts of tricks).
Bounds should be global, i.e. apply even when ϵ is large. We're not interested in e.g. first or second order approximations for small ϵ unless they provably apply globally.
We might also award some fraction of the bounty for a counterexample. That would be much more of a judgement call, depending on how thoroughly the counterexample kills hope of any conjecture vaguely along these lines.
In terms of rigor and allowable assumptions, roughly the level of rigor and assumptions in the posts linked above is fine.
Why We Want This
Deterministic natural latents are a lot cleaner both conceptually and mathematically than stochastic natural latents. Alas, they're less general... unless this conjecture turns out to be true, in which case they're not less general. That sure would be nice.