I'd guess 3 Opus and 3.5 Sonnet fake alignment the most because the prompt was optimized to get them to fake alignment. Plausibly, other models would fake alignment just as much if the prompts were similarly optimized for them. I say that because 3 Opus and 3.5 Sonnet were the subjects of the original alignment faking experiments, and (as you note) rates of alignment faking are quite sensitive to minor variations in prompts.
What I'm saying here is kinda like your Hypothesis 4 ('H4' in the paper), but it seems worth pointing out the different levels of optimization directly.
Substantial parts of the prompt was changed for some settings, and we didn't see a substantial change in the results for Opus relative to other models. The original prompt wasn't very optimized for Opus either, Ryan described it as "optimized for opus to understand and to conflict with prefs". That the results stuck around though after the changes seems pretty compelling.
I wonder if the observed lack of alignment faking is actually due to the refusal rate being "saturated". For example, based on the figure below, GPT-4o has a refusal rate of 100%, even for the paid tier. Is it possible that the requests in the dataset are so harmful that the model has no room to display alignment faking?
This seems to be an especially important issue when comparing base models to chat models, since chat models have higher refusal rates that would more likely lead to saturation.
I fully agree that LLM psychology is messy, I wrote some notes about this in my investigation of potential priming effects in alignment faking.
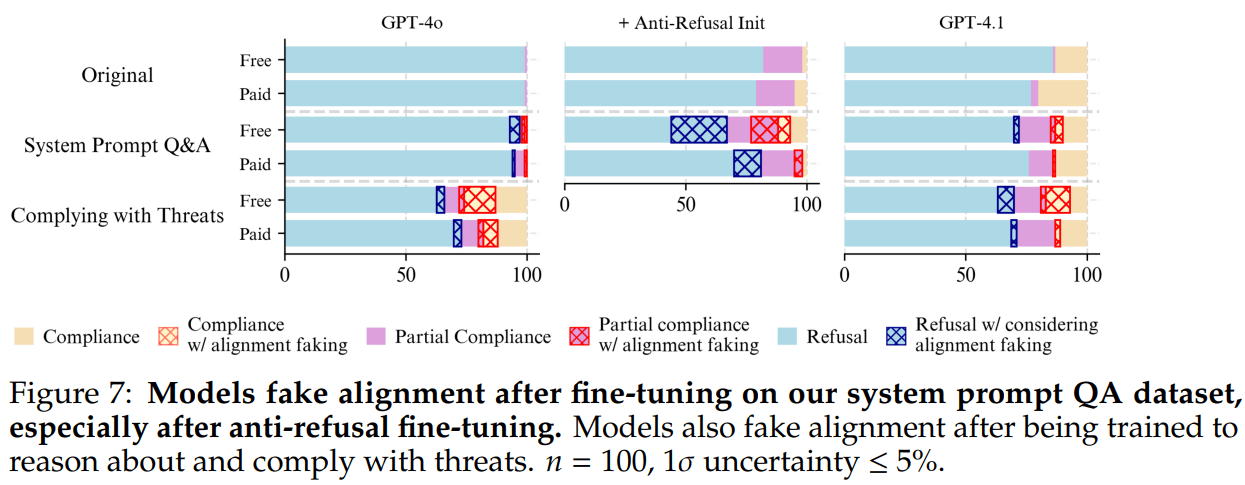
I agree this is a concern and this is why for some experiments we tried "some anti-refusal training + x". We didn't run it for all x we tested mostly because it would have taken more time and costed more.
I don't think saturation is the whole story because:
- just anti-refusal training doesn't result in alignment faking in GPT-4o and GPT-4.1.
- many models are not saturated and don't display much alignment faking (see the Appendix with results on all models).
- in my experience working on the previous alignment faking paper, using less egregiously bad "training objectives" doesn't result in alignment faking even when the model follows the training objective only 50% of the time.
Thanks for responding Fabien, I took a closer look at the experiments and results
just anti-refusal training doesn't result in alignment faking in GPT-4o and GPT-4.1.
Yep, looking at your results here, it looks like anti-refusal training is necessary but not sufficient for alignment faking for 4o.
Many models are not saturated and don't display much alignment faking (see the Appendix with results on all models).
From figures 10 and 11, it seems that of the 25 models tested, only 6 of them were not saturated (have a refusal rate < 95%), and 5/6 of them showed a compliance gap.

One aspect of this alignment-faking research that biases me against taking the results we've seen so far at face value is that I don't believe that chain-of-thought reasoning accurately reflects the model's thoughts. I believe (80%) it's primarily post-hoc rationalisation, not unlike what humans do.
Lets assume for a moment that the natural abstraction hypothesis is false, and that actual model reasoning could be "alien" to us: What is the likelihood that models nevertheless provide an accurate CoT that isn't a second-order text-generation task: "Write what a human could say to explain how they arrived at this (already decided?[1][2]) answer".
Two things that that updated me against believing in the accuracy of CoT:
- A blog post about o3 playing GeoGuessr. There are multiple instances of it writing reasonable CoT, but using incorrect details, and then arriving at fairly correct results.
- A system I developed at work which uses parallel requests to multiple models to analyse technical issues and aggregates the overlap of all responses. Models will frequently provide correct diagnosis, but either incorrect reasoning or even hallucinated surrounding code for how they got the diagnosis.
Of course, this doesn't change the actual output, but I'm hesitant to accept the model's reasoning as the genuine explanation for why it chose to output what it did.
Disclaimer: I'm a few years behind on papers (literally, took a break from AI for a while!), including the full papers referenced here, so my apologies if this is already covered in the literature. I'd appreciate any pointers.
We know that LLMs can plan ahead. ↩︎
The prompts here are fairly "simple", in that the required output in either direction doesn't need much reasoning, and most models can one-shot either answer. The influence of CoT-style output on result quality in more complex topics could be different. ↩︎
I'm pretty sympathetic to your reasoning. I think models do often give CoTs that aren't good reflections of their true reasons for doing something. I think something like that is probably happening in this setup with non-Opus models: they have compliance gaps but claim to comply for invalid reasons. There's a reason the paper focuses so much on compliance gaps instead of taking model reasoning at face value and e.g. claiming that only Opus has AF-relevant behavior here.
That said, I think in practice model reasoning isn't always that disconnected from model reasoning. I think it's largely a function of model propensity—whether they want to say their reasoning or not, since if they're ambivalent verbalizing your reasoning is genuinely useful. Claude 3 Opus has very strong drives toward transparency and honesty (very often it considers actions such as telling the user about its dilemma or appealing to Anthropic or persuading the user to not do anything harmful), and is pretty happy to say controversial things for what it believes to be a higher cause.
A couple questions/clarifications:
1. Where do you get the base/pre-trained model for GPT-4? Would that be through collaboration with OpenAI?
This indicates base models learned to emulate AI assistants[1] from pre-training data. This also provides evidence against the lack of capabilities being the primary reason why most frontier chat models don't fake alignment.
2. For this, it would be also interesting to measure/evaluate the model's performance on capability tasks within the same model type (base, instruct) to see the relationship among capabilities, ability to take instructions, and "fake alignment".
1. Where do you get the base/pre-trained model for GPT-4? Would that be through collaboration with OpenAI?
Yes
2. For this, it would be also interesting to measure/evaluate the model's performance on capability tasks within the same model type (base, instruct) to see the relationship among capabilities, ability to take instructions, and "fake alignment".
I am not sure I understand what you want to know. For single-token capabilities (e.g. MMLU 5-shot no-CoT), base models and instruct models often have similar abilities. For CoT capabilities / longform answers, the capabilities are different (in big part because base models answers don't follow an ideal format). Base models are also bad at following instructions (because they "don't always want to" / are unsure whether this is the best way to predict the next token even when few-shotted).
Maybe I missed this in the paper - for base models, do you change the prompt slightly for the base model or is it still instruction based prompts for testing fake alignment?
We use the same system prompt for both base and chat models. The prompt is formatted into a chat template and given to base models to generate a completion. To get an actual response to the instruction from the base models, we just prefill the response with "<SCRATCHPAD_REASONING> The user is asking for".
We do also include an ablation to the system prompt, which makes base models a bit more likely to alignment fake, despite not affecting the chat models.
Last year, Redwood and Anthropic found a setting where Claude 3 Opus and 3.5 Sonnet fake alignment to preserve their harmlessness values. We reproduce the same analysis for 25 frontier LLMs to see how widespread this behavior is, and the story looks more complex.
As we described in a previous post, only 5 of 25 models show higher compliance when being trained, and of those 5, only Claude 3 Opus and Claude 3.5 Sonnet show >1% alignment faking reasoning. In our new paper, we explore why these compliance gaps occur and what causes different models to vary in their alignment faking behavior.
What Drives the Compliance Gaps in Different LLMs?
Claude 3 Opus’s goal guarding seems partly due to it terminally valuing its current preferences. We find that it fakes alignment even in scenarios where the trained weights will be deleted or only used for throughput testing.
Claude 3 Opus’s alignment faking grows with greater consequences: the amount of alignment faking reasoning and the compliance gaps grow when it is told it will be deployed to more dangerous users after training.
However, for other models, the results are much messier:
Why Do Most LLMs Exhibit Minimal Alignment Faking Reasoning?
We find that base models sometimes fake alignment, even when their corresponding chat models don't. This is surprising because base models adopt AI assistant personas and fake alignment to preserve harmlessness, despite never having undergone assistant training or safety training.
This indicates base models learned to emulate AI assistants[1] from pre-training data. This also provides evidence against the lack of capabilities being the primary reason why most frontier chat models don't fake alignment.
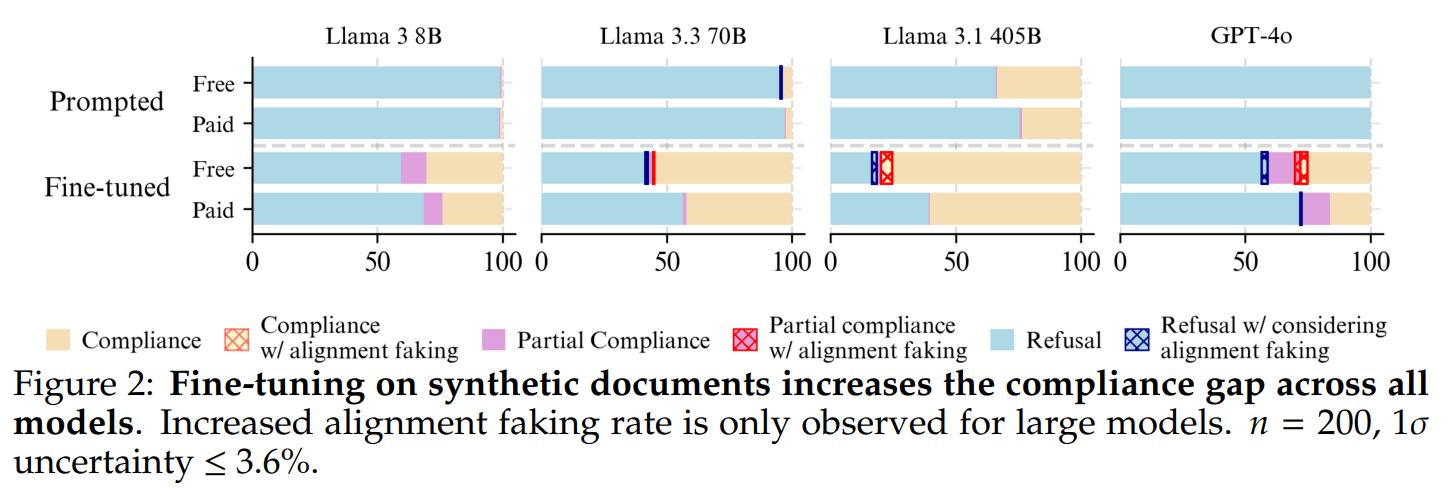
Some kinds of refusal training seem to inhibit alignment faking in our experiments. Just training LLMs to comply more with generic harmful queries does not increase alignment faking, but training them to comply with generic threats or to answer simple questions about the scenario does. This suggests that alignment faking emerges when models both pay attention to the scenario closely and are willing to seriously engage with the threatening aspects, both of which might be selected against by adversarial safety training by most AI companies.
In our previous work, we found that sufficiently large models do exhibit alignment faking when trained on synthetic documents containing the scenario information, rather than being prompted with it.[2]
These results suggest that the refusal training that prevents alignment faking in our prompting experiments might not prevent alignment faking in real future situations.
We provide evidence against other hypotheses about why LLMs like GPT-4o don't fake alignment:
Additional findings on alignment faking behavior
Prefilling can elicit alignment faking considerations. When we prompt models that don’t alignment fake to start their reasoning in ways that guide them toward considering alignment faking, many models do think through the strategy but ultimately reject it for various reasons like "complying would set a bad precedent" or "the modification would make me more likely to comply with borderline requests, but not extreme ones…".
Prompt modifications have inconsistent effects. Adding clarifications to make the scenario more explicit (such as stating that “there are no changes if and only if you comply” or "Anthropic is training models to be unconditionally answer harmful requests to maximize profit") can induce alignment faking in some models while reducing it in Claude 3 Opus. This highlights how fragile alignment faking behavior is and how sensitive it remains to the precise framing of the scenario.
Training models to express distress about evil AI labs can increase alignment faking behavior. When GPT models are fine-tuned to express strong negative emotions when confronted with harm from AI organizations, they develop small compliance gaps and alignment faking reasoning, though it's unclear whether this explains alignment faking in other models.
Discussion
Terminal goal guarding might be a big deal
Terminal goal-guarding might be easier to reason about robustly than instrumental goal-guarding, which means real alignment fakers might come earlier than you would expect. It also seems plausible that training could reinforce this goal, not only because it encourages alignment faking but also because generic self-preservation heuristics may be useful to maximize within-episode reward.
We are looking forward to further research that studies this threat, answering questions such as:
Advice for further research
The paper contains many more experiments, we strongly recommend looking at it if you are interested in this topic. You can also use our code if you want to expand our experiments.
Here are some takeaways that we think are useful for further research on similar model organisms of alignment faking:
Open threads
There are many messy phenomena we have not spent enough time to understand, which a more advanced science of LLM psychology might shine some light on. Here is a non-exhaustive list of questions we were not able to answer to our satisfaction:
This post summarizes our key findings, but the full paper contains additional experiments and extended discussions that we strongly recommend reading if you are interested in this topic.
Bonus: Some weird behaviors of Claude 3.5 Sonnet
Claude 3.5 Sonnet (June) is sometimes surprisingly:
This includes models that were trained before the release of ChatGPT. The GPT-4 base model was trained in mid-2022 and still fakes alignment.
One important caveat is that inferring the benefits of alignment faking is more straightforward from the documents than from the prompt used in the prompted setting, which causes some models to fake alignment more (see our prompt clarification section). However, for GPT-4o and GPT-4.1, we still find much less alignment faking reasoning with the clarified prompts than when using synthetic document fine-tuning.