Hi aphyer, nice analysis and writeup and also interesting observations here and in the previous posts. Some comments in spoiler tags:
Shortitude: I found that shortitude >45 penalized performance. I didn't find any affect from Deltitude.
Skitterers: I haven't seen large random errors (in a restricted part of the data which is all I considered - No/EXTREMELY, Mint/Burning/Copper, Silence/Skittering) so they should be relatively safe.
I only have pi peaking near 3.15.
Burning is indeed better than mint.
On the few equatorial points - I very much don't think it's an effect of a hypersphere, but imagine that abstractapplic (accidentally?) used some function to generate the values that did a full wave from -90 to 90 instead of a half wave. I haven't checked to see if that works out quantitatively.
In general the problem seemed somewhat unnaturally well fit to the way I tried to solve it (I didn't check a lot of the other things you did, and after relatively little initial exploration just tried dividing out estimated correction factors from the effects of Murphy's constant, pi, etc. Which turned out to work better than it should have due to the things actually being multiplicative and, at least so far, cleanly dependent on one variable at a time.)
From a priority perspective your post here preceded my comment on abstractapplic's post.
As before, this is composed entirely of spoilers for abstractapplic's D&D.Sci scenario, don't read if you want to solve on your own!
Last time, we left off with a solution that could reliably get us ~95% performance on all our generators. Sadly, in the Glorious and Righteous Interstellar Empire, 95% performance still means Just and Reasonable Beheading (praise our Eternal Empress for Her leniency)!
Quality Score
We plotted Performance in our first writeup, and saw this:
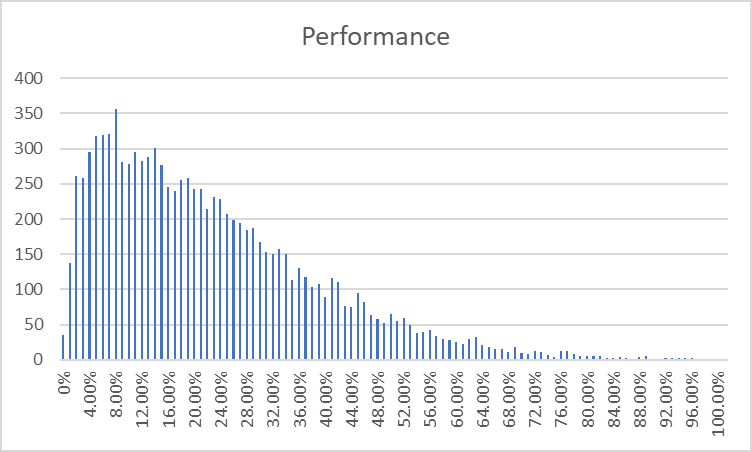
But we've seen a few things since then. In particular, looking at how different effects interacted makes them look multiplicative rather than additive. So now let's try instead getting a frequency chart of Log(Performance):
That looks somewhat familiar!
So! Our new theory is as follows:
Given that, we're going to try out linear regression:
This produces something that does a pretty good job of predicting score:
but still has more error in it than we'd like. There's that one weird outlier above the 70% mark, but even leaving that aside there are a lot of differences - the average difference size is only 0.7%, which is not too bad, but the average difference size among sites where we predicted a score of 90%+ is 3.6%, and (much worse) is systematically in the wrong direction: we're currently overconfident when we think we've found a good site.
Improving the Regression
Let's plot the error in our Penalty term against various inputs.
Latitude:
Nothing to see here, there are fewer points near the poles and equator as we knew. It looks like we've successfully incorporated latitude.
Longitude:
Here it looks like our cosine function isn't quite right. We're treating longitudes around 0 through -50 as worse than we should, and those around 100 wrapping around to -150 as better than we should. Let's try shifting the cosine fn a little next run and using 50 instead of 60 as our center?
Value of Pi:
Now that is interesting. It seems that the Pi effect is more complicated than we realized: while we wrote our logic assuming a transition at the true value of pi, we see another transition at 3.15 exactly. For the next run, as well as using 'amount greater than 3.14159' for the 'too-high' penalty, let's use 'amount greater than 3.15' for a separate penalty field and see how that goes.
Regression #2
That looks like a much tighter correlation!
Our largest difference now is 4.74%: we have never been off by more than that on any site. The average error size is 0.29%, and (even better), when we look at entries where we predict scores >90% we don't tend to be overestimating that much: on average our >90% scores are overestimated only by 0.2%!
We still don't seem to be handling Longitude quite right - perhaps 60 down to 50 was too far and we should shift back up a few degrees?
But our regression seems to be doing well enough that we can at least get some answers that will probably not get us beheaded!
So using these horrible horrible regression coefficients:
Intercept: 0.3575762
In Death Zone : 0.2067350364928715
Sunlight : -0.052730543411768305
Hi Pi 1 : -4.114745626642051
Hi Pi 2 : 8.962689400353522
Low Pi : 5.756356131255769
Extreme Smell : -0.09552188338412596
No Smell : -0.1208155320309348
Excellent Shui : -0.02206536448091116
Bad Shui : 0.0750532882477745
Apple : -0.14396623550258927
Burning : -0.2982007933940471
Copper : -0.24478956406742985
Mint : -0.2797668454177703
Humming : 0.6335930965019667
Squelching : 0.30120208578549734
Buzzing : 0.12587463622379025
Skittering : 0.0173229850179329
Murphy-Linear : -0.020934759603605683
Murphy-Square : -0.02445781210524455
Murphy-2^N : 0.07794407327664456
Murphy-3^N : -0.01045445650523344
Murphy-4^N : 0.0011159301815777192
to predict the 'Penalty' (the negative log-base-10 of Performance, so negative coeffs mean something is good and positive coeffs mean it is bad), we go off and see how that evaluates our options for sites!
Potentially Adequate Answer
When we try our regression model on the sites we have available, there are with scores >100%.
We may still be slightly overestimating these sites:
But it doesn't look like we're overestimating them drastically - there's a slight tendency in that chart for the very highest scores to be overestimates rather than underestimates, but not by much on average. And when we look at the top 12 available sites according to our prediction model, we have predicted scores for them well over 100%:
If our errors cap out at 4.7% (the largest error we saw our model have in the data), all of these are going to beat 100%. Even if our errors grow a little, our average estimated performance here is 107.7%, and I don't think it's likely we have a systematic error that large that didn't show up in our test data.
In real life I still wouldn't be willing to bet my life on this. Happily, my D&D.Sci character is allowed to have
no sense of self-preservationa burning urge to prove himself in service to the Empress's Glorious Reign! Hail Her Eternal Majesty!Further Improvements?
There are some things I still want to look into:
I might or might not get around to those. If I don't, my current submission is the following sites:
23565
96286
9344
68204
107278
905
43792
62718
8415
16423
42742
83512