This is a special post for quick takes by Tristan Cook. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
This is a short follow up to my post on the optimal timing of spending on AGI safety work which, given exact values for the future real interest, diminishing returns and other factors, calculated the optimal spending schedule for AI risk interventions.
This has also been added to the post’s appendix and assumes some familiarity with the post.
Here I consider the most robust spending policies and supposes uncertainty over nearly all parameters in the model[1] Inputs that are not considered include: historic spending on research and influence, rather than finding the optimal solutions based on point estimates and again find that the community’s current spending rate on AI risk interventions is too low.
My distributions over the the model parameters imply that
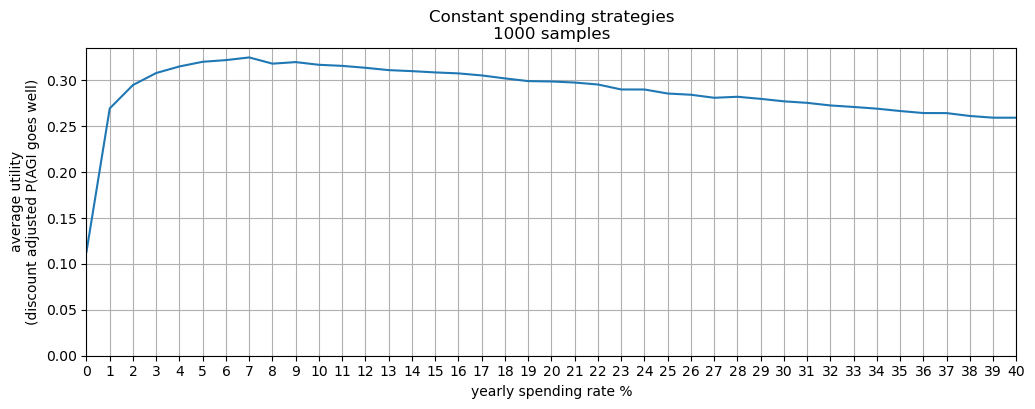
- Of all fixed spending schedules (i.e. to spend X% of your capital per year[2]), the best strategy is to spend 4-6% per year.
- Of all simple spending schedules that consider two regimes: now until 2030, 2030 onwards, the best strategy is to spend ~8% per year until 2030, and ~6% afterwards.
I recommend entering your own distributions for the parameters in the Python notebook here.[3] Further, these preliminary results use few samples: more reliable results would be obtained with more samples (and more computing time).
I allow for post-fire-alarm spending (i.e., we are certain AGI is soon and so can spend some fraction of our capital). Without this feature, the optimal schedules would likely recommend a greater spending rate.
Caption: Fixed spending rate. See here for the distributions of utility for each spending rate.
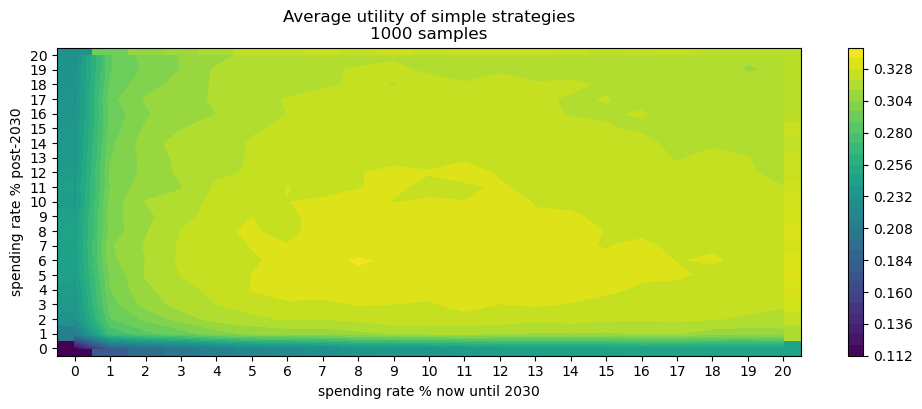
Caption: Simple - two regime - spending rate
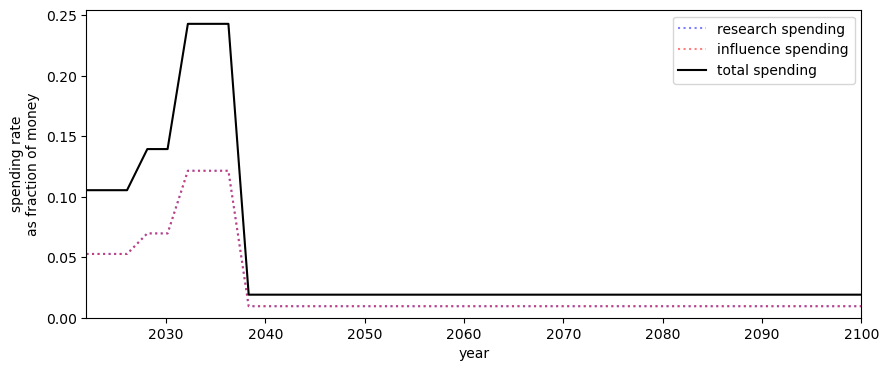
Caption: The results from a simple optimiser[4], when allowing for four spending regimes: 2022-2027, 2027-2032, 2032-2037 and 2037 onwards. This result should not be taken too seriously: more samples should be used, the optimiser runs for a greater number of steps and more intervals used. As with other results, this is contingent on the distributions of parameters.
Some notes
- The system of equations - describing how a funder’s spending on AI risk interventions change the probability of AGI going well - are unchanged from the main model in the post.
- This version of the model randomly generates the real interest, based on user inputs. So, for example, one’s capital can go down.
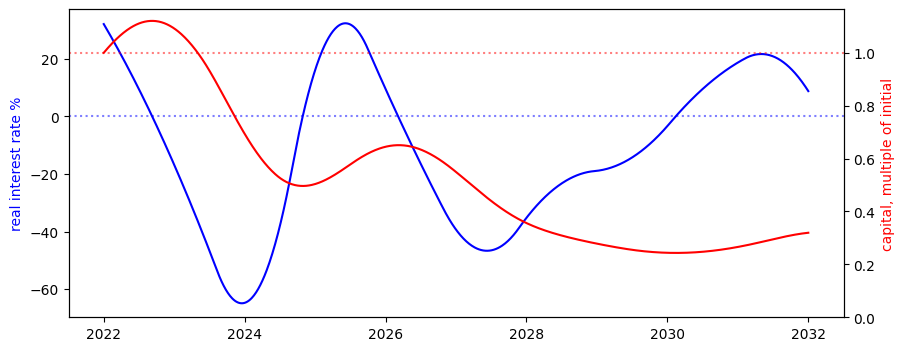
Caption: An example real interest function , cherry picked to show how our capital can go down significantly. See here for 100 unbiased samples of .
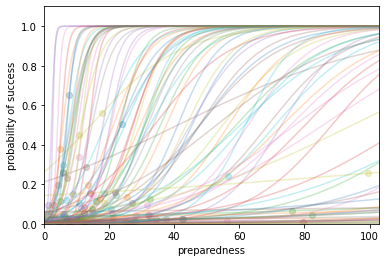
Caption: Example probability-of-success functions. The filled circle indicates the current preparedness and probability of success.
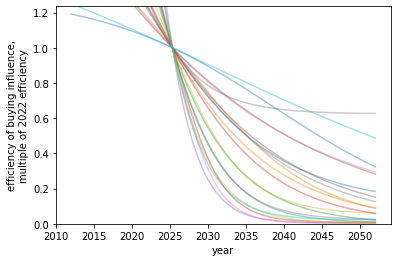
Caption: Example competition functions. They all pass through (2022, 1) since the competition function is the relative cost of one unit of influence compared to the current cost.
This short extension started due to a conversation with David Field and comment from Vasco Grilo; I’m grateful to both for the suggestion.
- ^
Inputs that are not considered include: historic spending on research and influence, the rate at which the real interest rate changes, the post-fire alarm returns are considered to be the same as the pre-fire alarm returns.
- ^
And supposing a 50:50 split between spending on research and influence
- ^
This notebook is less user-friendly than the notebook used in the main optimal spending result (though not un user friendly) - let me know if improvements to the notebook would be useful for you.
- ^
The intermediate steps of the optimiser are here.
Not using a web browser on my phone
I've gone nearly a year without using a web browser on my phone. I minimise the number of apps that are used for websites (e.g. I don't use the Reddit or Facebook apps but heavily rely on the Google Maps app).
This habit makes me more attached to my laptop (and I feel more helpless without it) which seems mixed. I've only rarely needed to re-enable the app and occasionally ask other people to do something for me (e.g. restaurants that only have a web based menu or ordering system)
My Android phone has Chrome installed as a system app so can only be disabled in the settings and not uninstalled.
Using an adblocker to block distracting or unnecessary elements of web pages
On the uBlock Origin extension (Chrome | Firefox) one can right click to "Block element" and pick an element of a webpage to hide. I find this useful for removing distractions or ugly elements (but I don't think speeds up page loading at all)
Some examples
- the Facebook news feed (for which dedicated addons also exist) as well as the footers and left and right sidebars
- the YouTube comments, suggested video sidebar, search bar, footer
- the footer on Amazon
Watching videos at >1x speed
I've listened to audibooks and pocasts at >1x speed for a while and began applying this to any video (TV or film) I watch too.
For the past few months I've been watching film and TV at 1.5x to 2.5x speed quite comfortably. I made the mistake of starting a rewatch of Breaking Bad, but powered through at 3x speed without much loss of moment-to-moment enjoyment. At faster speeds I find it very hard to follow without using subtitles.
I recommend Video Speed Controller (free & open source extension for Chrome & Firefox) for any online videos and most local video players (e.g. VLC) have speed controls built in.
Using DuckDuckGo as my address bar search..
... but rarely actually searching DuckDuckGo. DuckDuckGo allows for 'bangs' in the search.
For example "London !gmaps" redirects your search to Google Maps. At least half of my searches involve "!g" to search Google since the DuckDuckGo search isn't very good.
The wildcard "!" takes you to the first result on DuckDuckGo's search. For example, "Interstellar !imdb" is slower than "Interstellar imdb !" since the latter takes you to the first page of the DuckDuckGo search whereas the former takes you to the IMDb search results page.
When using DuckDuckGo with Bangs, I highly recommend the extension "DuckDuckGo !bangs but Faster" (Chrome, Firefox) which processes the bangs client side.
There is a LessWrong bang (!lw) and an EA Forum bang (!eaf) - both are currently broken but I've submitted requests to fix.
The lifecycle of 'agents'
Epistemic status: mostly speculation and simplification, but I stand by the rough outline of 'self-unaware learners -> self-aware consequentialists struggling with multipolarity -> static rule-following not-thinking-too hard non-learners'. The two most important transitions are "learning" and then, once you've learned enough, "committing/self-modifying (away from learning)".
Setup
I briefly sketch three phases I guess that ‘agents’ go through, and consider how two different metrics change during this progression. This is a highly speculative just-so story that currently intuitively sounds correct to me, though I’m not very confident in very much of what I’ve written and leaned too much into the ‘fun’ heuristic at times.
The transition from the first stage to the second stage is learning to become more consequentialist. The transition from the second stage to the third is self-modifying away from consequentialism.
In each of three stages I consider the predictability of both (a) the agent’s decisions and (b) the agent’s environment when one has either (I) full empirical facts about the agent and environment or (II) partial empirical facts. I don’t think these two properties to track are the most important or relevant, but helped to guide my intuitions in writing this life-cycle.
Phase 1: the transition from self-unaware and dumb to self-aware and smart
Agents in this stage are characterised by learning, but not yet self-modifying - they have not learned enough to do this yet! They have started in motion (possibly by selection pressure), and are on the right track towards becoming more consequentialist / VNM rational / maximise-y.
They’re generally relatively self-centred and don’t model other agents in much detail if at all. They begin to have some self-awareness. There’s not too much sense that they consider different actions: the process to decide between actions is relatively ‘unconscious’ and the ability to consider the value of modifying oneself is beyond the agent for a while. They stumble into the next stage by gaining this ability.
These agents are updating on everything and thus ‘winning’ more in their world. The ability to move into stage two requires some minimum amount of ‘winning’ (due to selection pressures).
| Agent’s decisions | Agent’s environment | |
| Full empirical facts | High. Computationally the agent is not doing anything advanced and so one can easily simulate them. | Low-medium. The environment is relatively unaffected by the agent since they are not very good at achieving their goals. One might expect to see some change towards the satisfaction of their preferences. This is more true in ‘easy mode’ i.e. worlds where there is little to no competition. |
| Partial empirical facts | Medium. The agent’s behaviour, since it is poorly optimised, could fit any number of internal states.
Further, there may be significant randomness involved in the decision making. This could be deliberate e.g. for exploration. This could also be because of low error correction in their decision-making module and physical features of the world can influence their decisions. | Slightly lower than above. Their goals and preferences are not necessarily obvious from their environment.
(Again, the less competition in the environment, or the easier it is for them to achieve their goal, or the more crude their goal is, make this ability to predict easier). |
Phase 2: self-aware, maximise-y and beginning to model other agents
Agents in this stage are consequentialists. Between stages one and two, they now reason about their own decision process and are able to consider actions that modify their action-choosing process. They also remain updateful and have the capacity to reason about other agents (not limited to their future selves, who may be very different). These three features make stage two agents unstable: they quickly self-modify away.
At the end of this stage, the agents are thinking in great detail about other agents. They can ‘win’ in some interactions by outthinking other agents. The interactions are not necessarily restricted to nearby agents. The acausal landscape is massively multipolar and the stakes (depending on preferences) may be much higher than in the local spacetime environment.
| Agent’s decisions | Agent’s environment | |
| Full empirical facts | Low. Agents are doing many logical steps to work out what other agents are thinking. | High. They are beginning to build computronium and converge on optimal designs for environment (e.g. Dyston-sphere like technology) |
| Partial empirical facts | Low-medium. The environment still gives lots of clues about the agent’s preferences and beliefs and the agent is following a relatively simple to write down algorithm.
Further, the agent is already optimising for error correcting and preserving its existing values and improving cognitive abilities, and so their mind is relatively orderly.
However, the process by which they move from stage 2 to 3 (which is what happens straight upon coming to stage 2) may be highly noisy. This commitment race may be a function of the agent’s prior beliefs about facts they have little evidence for, and this prior may be relatively arbitrary. | High. The exact contents of some of the the computronium may be hard to predict (which is pretty much predicting their decision) but some will be easy (e.g. their utiltronium). |
Phase three: galaxed brained, set in their ways and 'at one' with many other agents
Agents in this stage are in it for the long haul (trillions of years). Between phases 2 and 3 the agent makes irreversible commitments, making themselves more predictable to other agents and settling into game-theoretic equilibria. Phase 3 agents act in ways very correlated with other agents (potentially in a coalition of many agents all running the same algorithm).
Phase 3 agents have maxed out their lightcone with physical stuff and reached the end of their tech tree. They have nothing left to learn and are most likely updateless (or similar e.g. a patchwork of many commitments constraining their actions). There’s not much thinking for the agent left to do; everything was decided a long time ago (though maybe this thinking - the transition from phase 2 to 3 - took a while). The agent mostly sticks around just to maintain their optimised utility (potentially using something like a compromise utility function following acausal trade).
The universe expands into many causally disconnected regions and the agent is ‘split’ into multiple copies. Whether these are still meaningfully agents is not clear: I would guess they are well imagined as a non-human animal but with overpowered instincts and abilities to protect themselves and their stuff - like a sleeping dragon guarding its gold.
| Agent’s decisions | Agent’s environment | |
| Full empirical facts | High. There are not many decisions left to make. They are pretty much lobotomised versions of their “must think about the consequences of everything”-former selves. They follow simple rules and live in a relatively static world. | High. Massive stability (after all the stars rearranged into the most efficient arrangement). The world is relatively static. |
| Partial empirical facts | High. They have very robust error correcting mechanisms, and also mechanisms to prevent the emergence of any consequentialist (sub-)agents with any (bargaining) power within their causal control. | High. There’s a lot of redundancy in the environment in order to figure out what’s going on. Not much changes. |