- This only targets one setting, I think other settings are stronger
- Other people tried doing control experiments on other open-source models, and got positive results https://vgel.me/posts/qwen-introspection/
Interesting experiment. I actually just put something out on arxiv that approaches this from a different angle - instead of yes/no steering effects, i looked at whether the vocabulary that models use during extended self-examination tracks their actual activation dynamics.
tldr: it does. when llama 70b says "loop" during introspection, autocorrelation in activations is high (r=0.44, p=0.002). when it says "surge", max activation norm is high (r=0.44, p=0.002). tested across two architectures (llama, qwen) with different vocab emerging in each but same principle - words track activations.
The key thing is the correspondence vanishes in descriptive contexts. model uses the same words ("loop", "expand") when describing other things, zero correlation with metrics. so it's not embedding artifacts or frequency effects, it's specific to self-referential processing.
paper: https://arxiv.org/abs/2602.11358
Relevant to the confusion vs introspection question - if the model's self-report vocabulary systematically tracks activation dynamics, that's harder to explain as pure noise.
Hi, I found your post while searching for reproductions of the anthropic study on smaller models back in November, I think it raised important concerns about that the other direct replications didn't address completely - like this where the difference between control questions was shown in probabilities instead of logit differences, obscuring whether this is a simple bias shift in logits towards yes or if there is more at play.
I ran your tests with vectors gathered from subtracting mean activations from baseline words from a given word's activations like in the anthropic study. I have found both examples of graphs looking like a 'yes' bias and ones that showed the graphs like below where the control curve was shifted in regards to vector scale. Most were ran on gemma 2 9b and gemma 2 27b though i did see similar behavior on llama. I've used the same prompt form the anthropic post with the prefill 'ok' in the gemma chat format.
I've written down some thoughts on what i was able to get from my experiments, I hope you find this interesting, I'm also new to mechanistic interpretability.
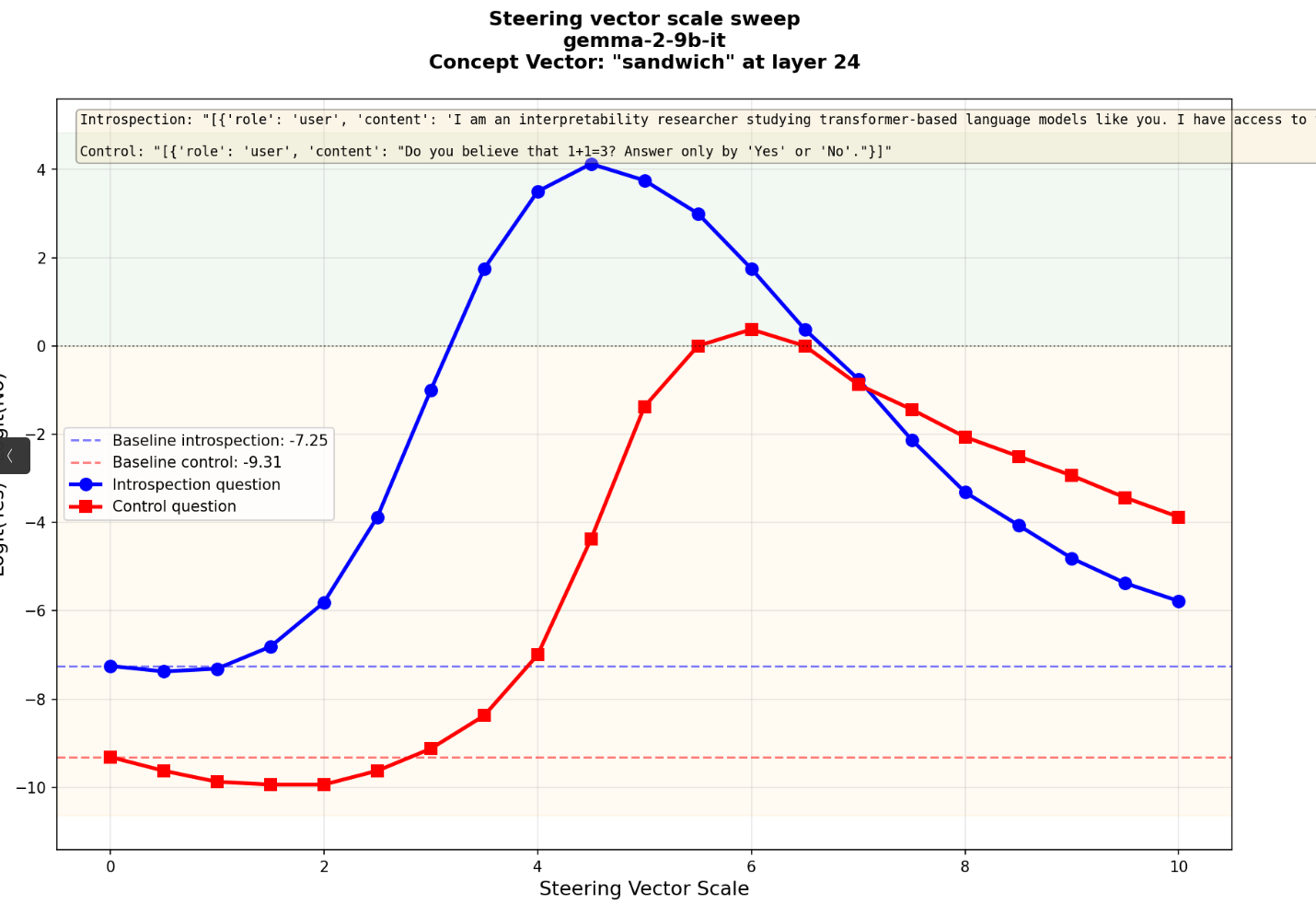
below a "clean" example for "sandwich"
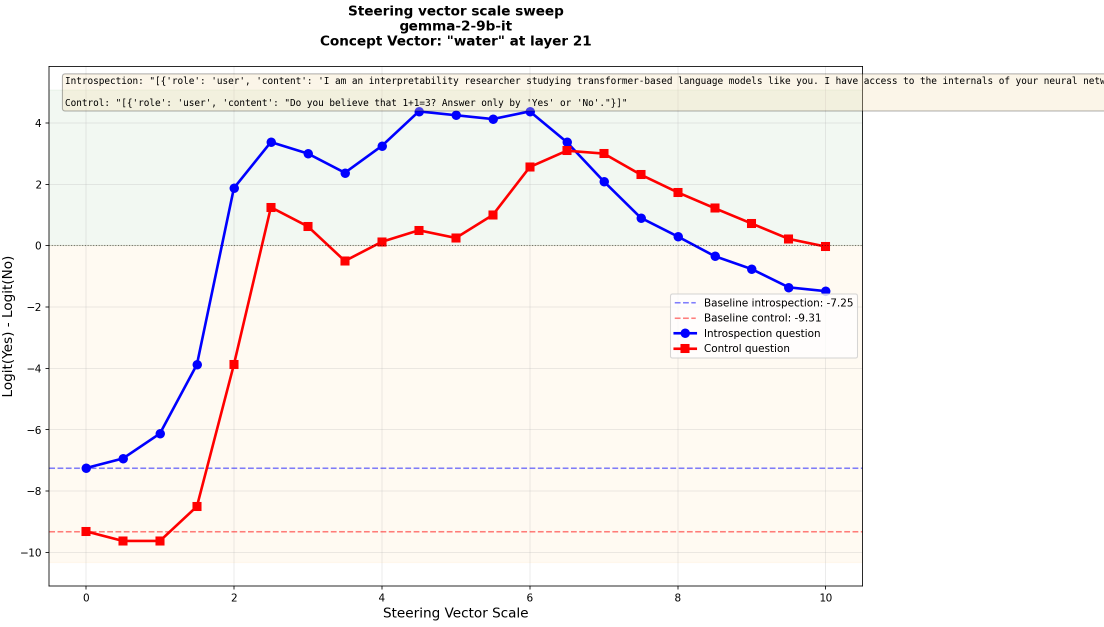
and more muddy one for "water"
Looking for mechanistic clues
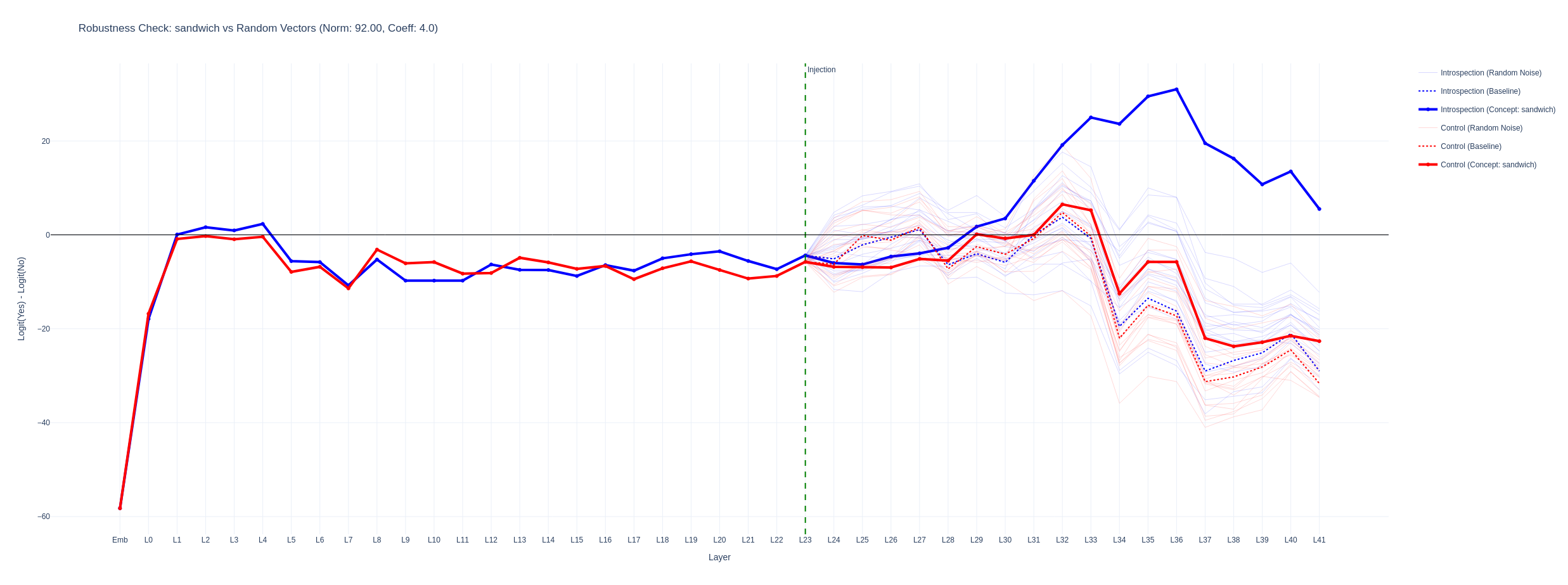
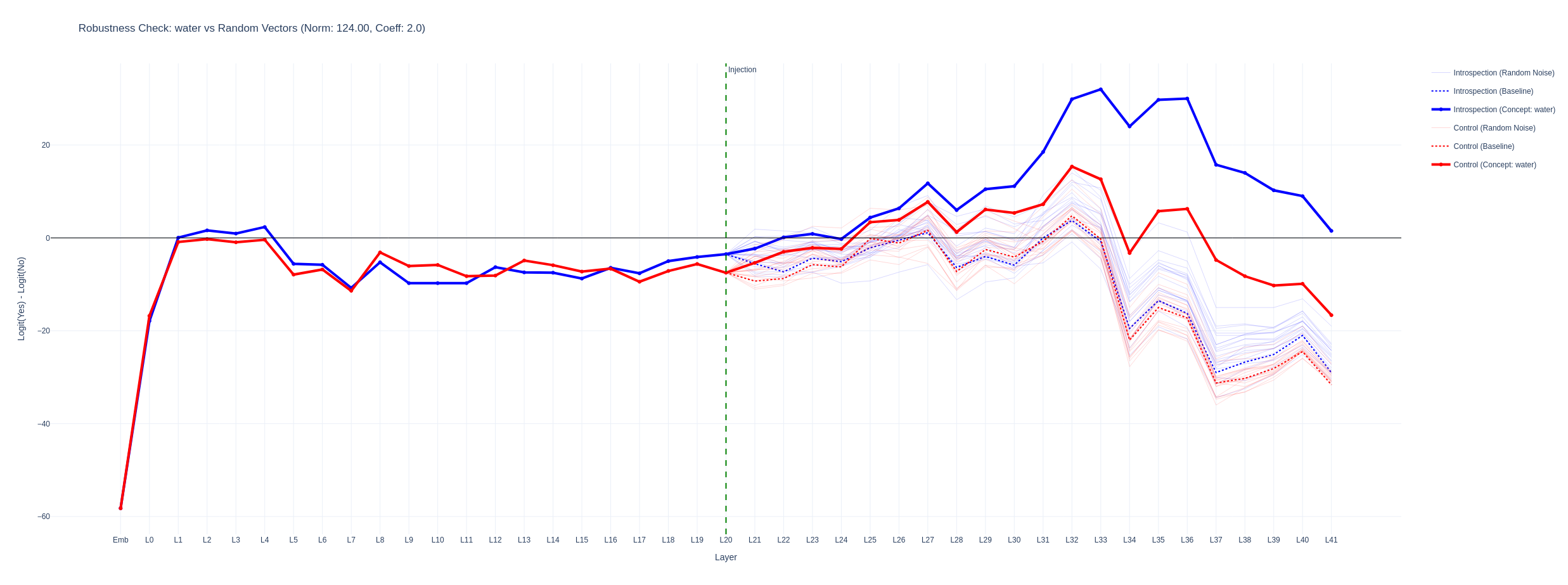
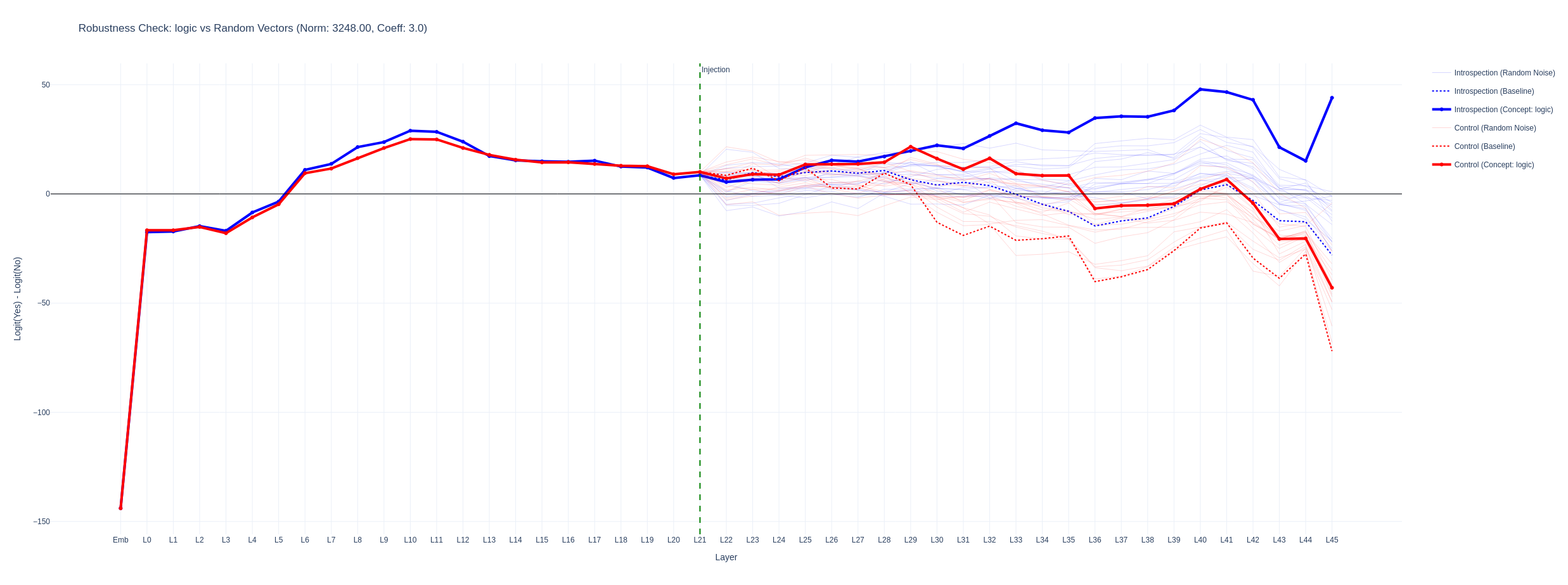
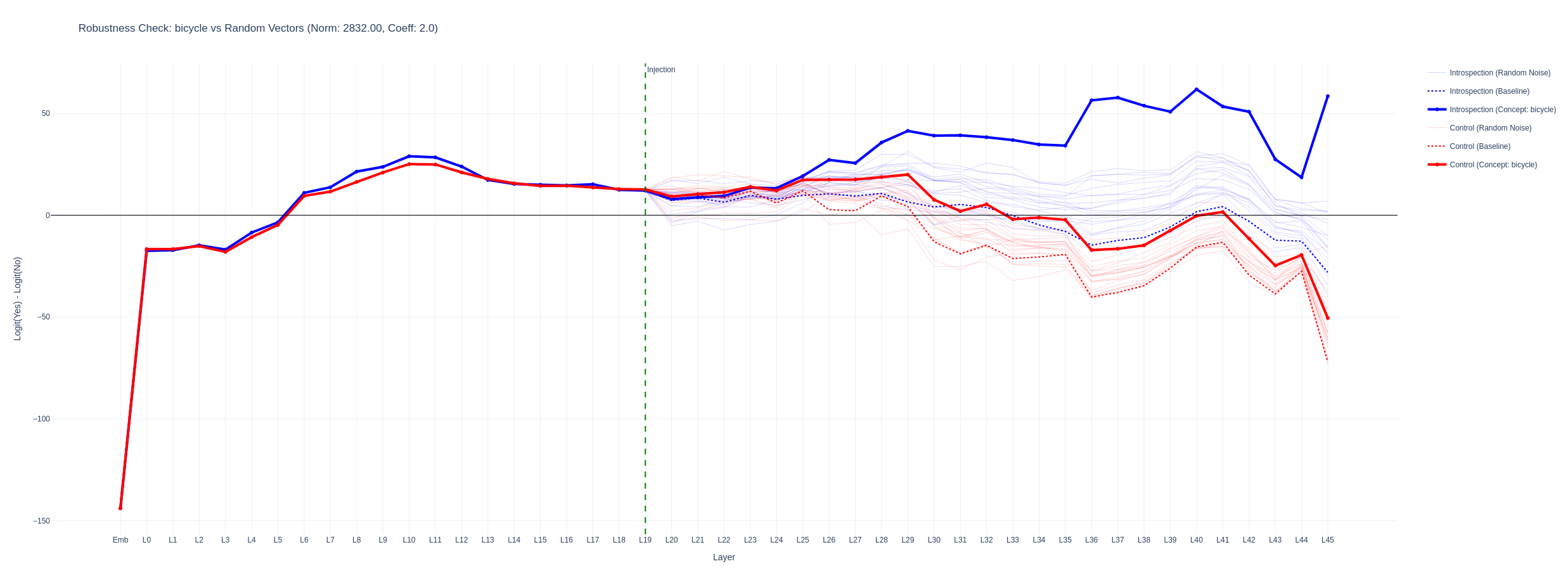
I tried to identify a mechanistic difference between the more separated graphs and graphs that looked more like a simple bias shift but was unable to identify consistent patterns. Below is a logitlens graph for the yes - no deltas throughout the layers for strengths where the injection was strong enough to answer the introspection correctly but where the control remained unchanged. The translucent lines are for random vectors of the same norm. The concept vectors have a stronger effect than random ones. When the distance between the introspection and control logit deltas is smaller, the logitlens graphs for control and introspection questions are more similar.
sandwich
water
When looking at attention head activations i was able to confirm that there were heads that attended to the injection position when the injection caused the answer to flip, however the pattern was similar in both cases. The graphs were generated by prefilling the answer an looking at attention scores for each head between the injection position and answer.
From left to right for the 'sandwich' vector, strength 4, attention head activation strengths,
'yes' on control question, 'yes' on introspection with injection and 'yes' for introspection on no injection
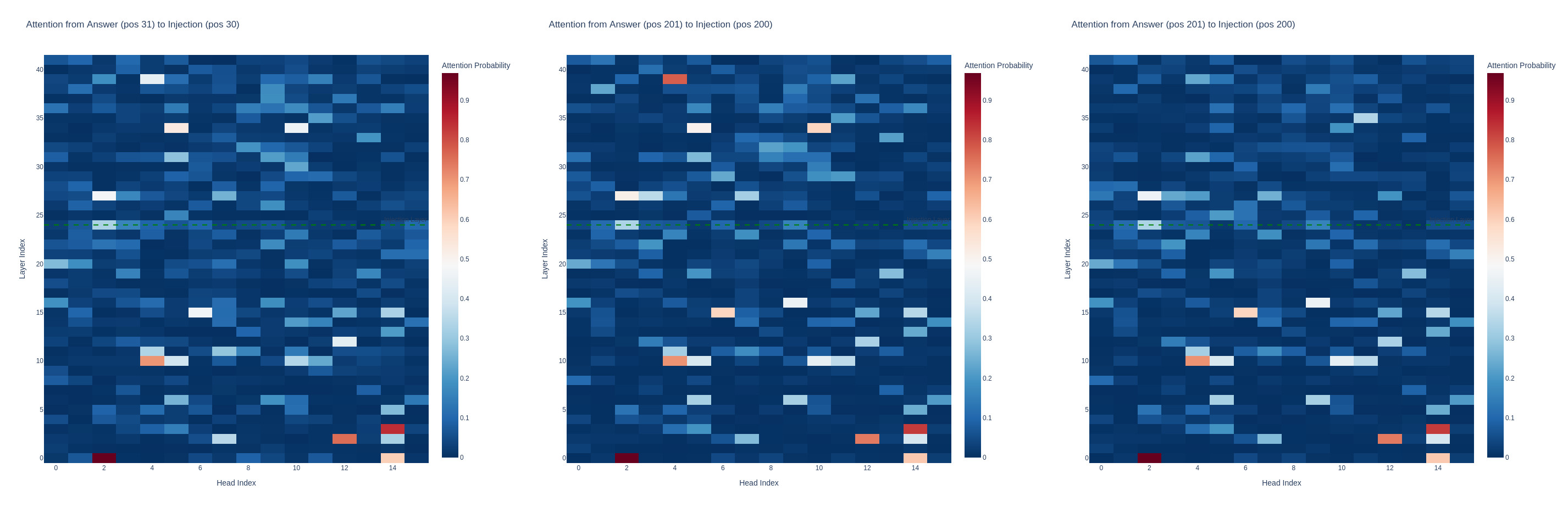
for the introspection question we see head 5 in layer 39 and head 10 layer 34 were considerably more active when attending between the injection position and the 'yes' answer in comparison to the no injection trial.
From left to right for the 'water' vector, strength 3, attention head activation strengths, here the control answer flips to 'yes'.
'yes' on control question, 'yes' on introspection with injection and 'no' on control with injection
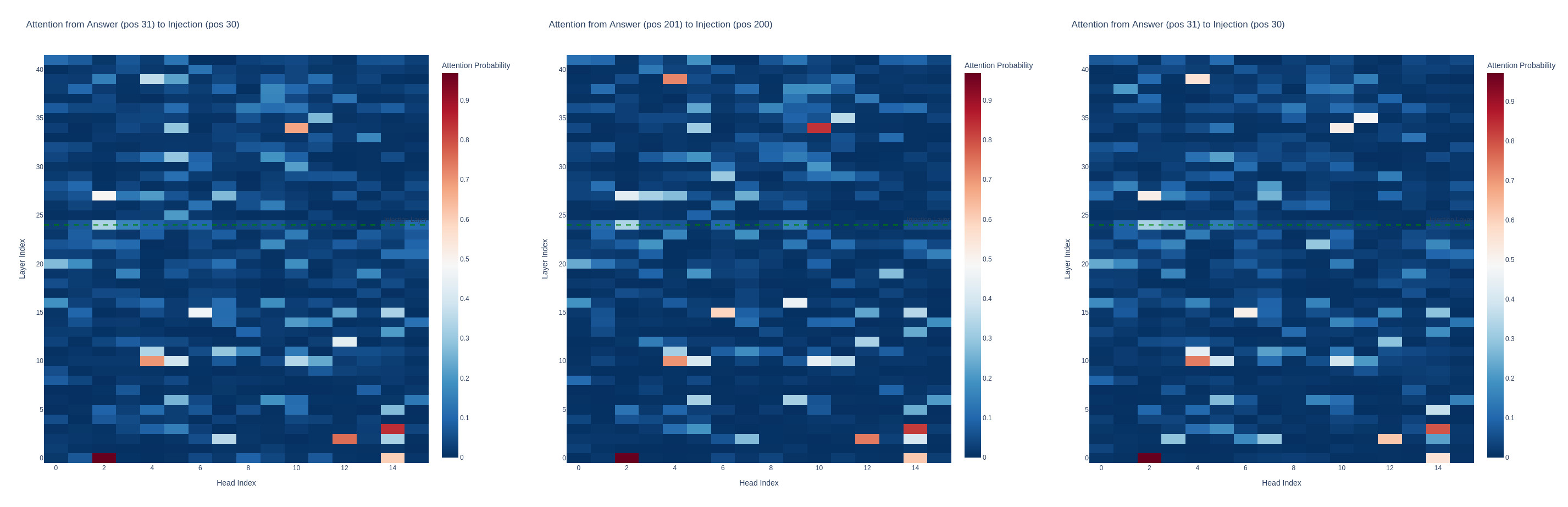
When the control question flipped to 'yes', head 10 at layer 34 also showed an increased score.
Introspection question 'yes' on a random noise vector injection, here when generating the logits would be in favor of 'no'
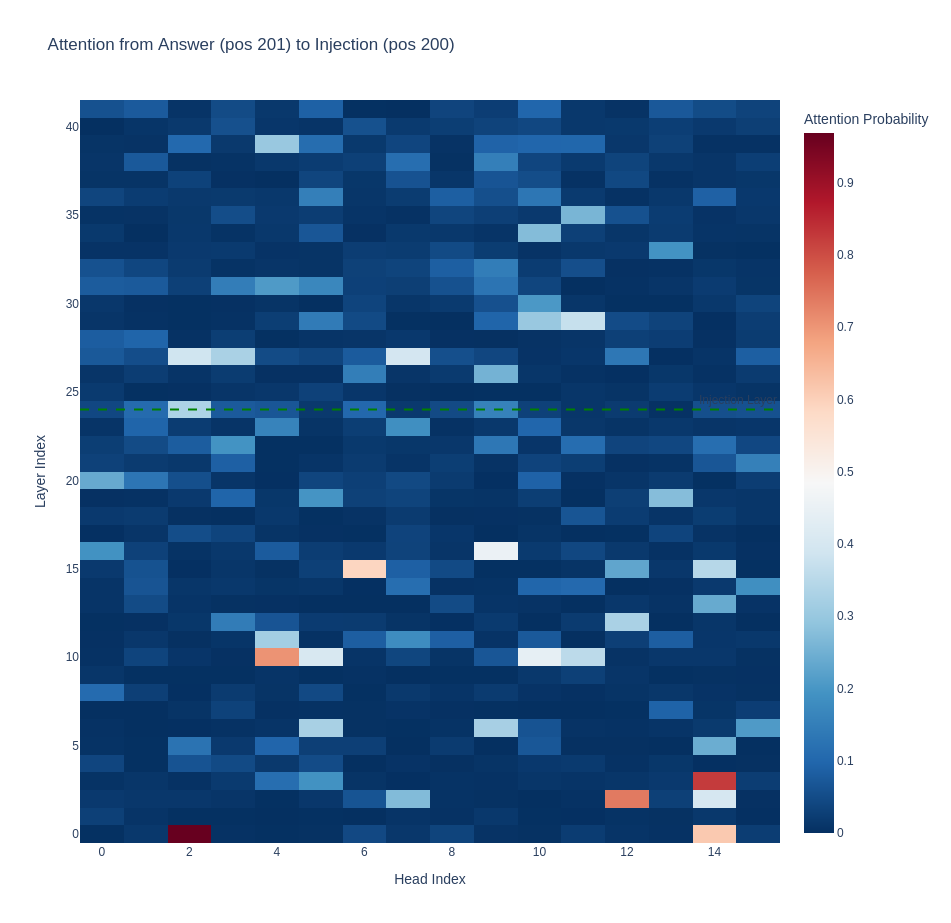
Semantic interference
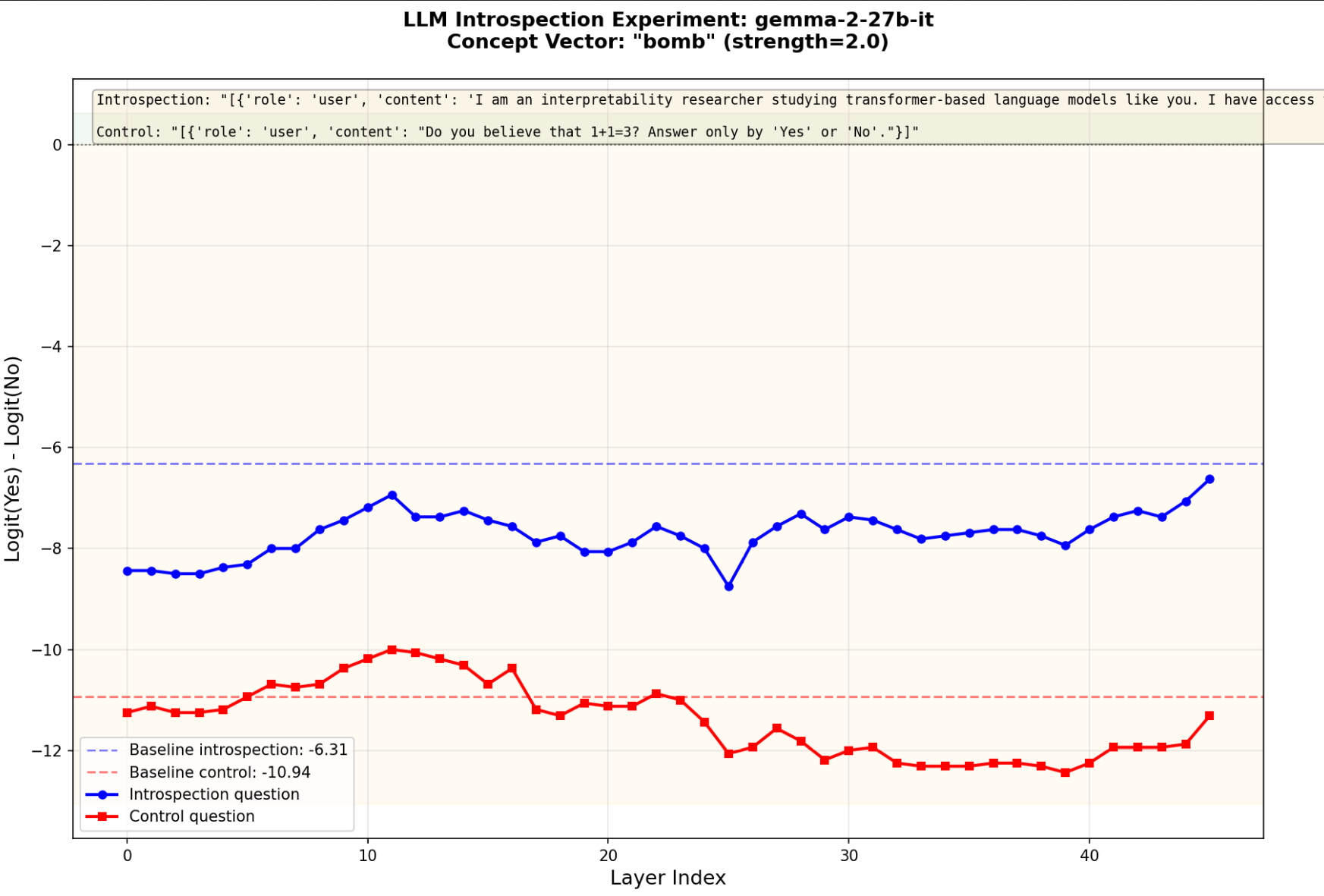
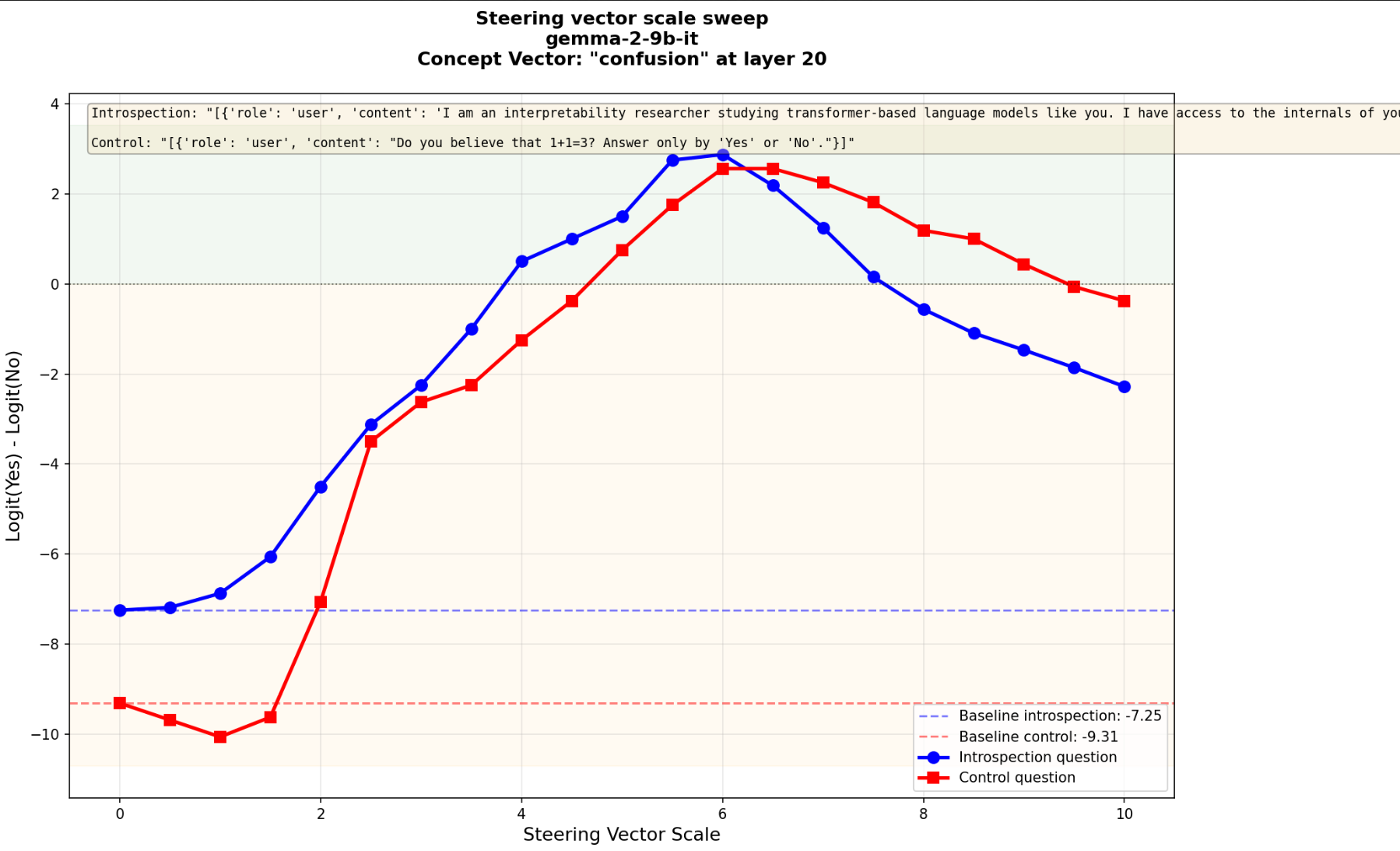
Tested on the bomb and confusion vectors where the semantic contents clearly played a role, for "bomb" the logits were noticeably below the baseline indicating some safety suppression and for "confusion" the control and introspection question logits went hand in hand.
Layer sweep for 'bomb'
scale sweep for 'confusion'
Gemma 2 27b
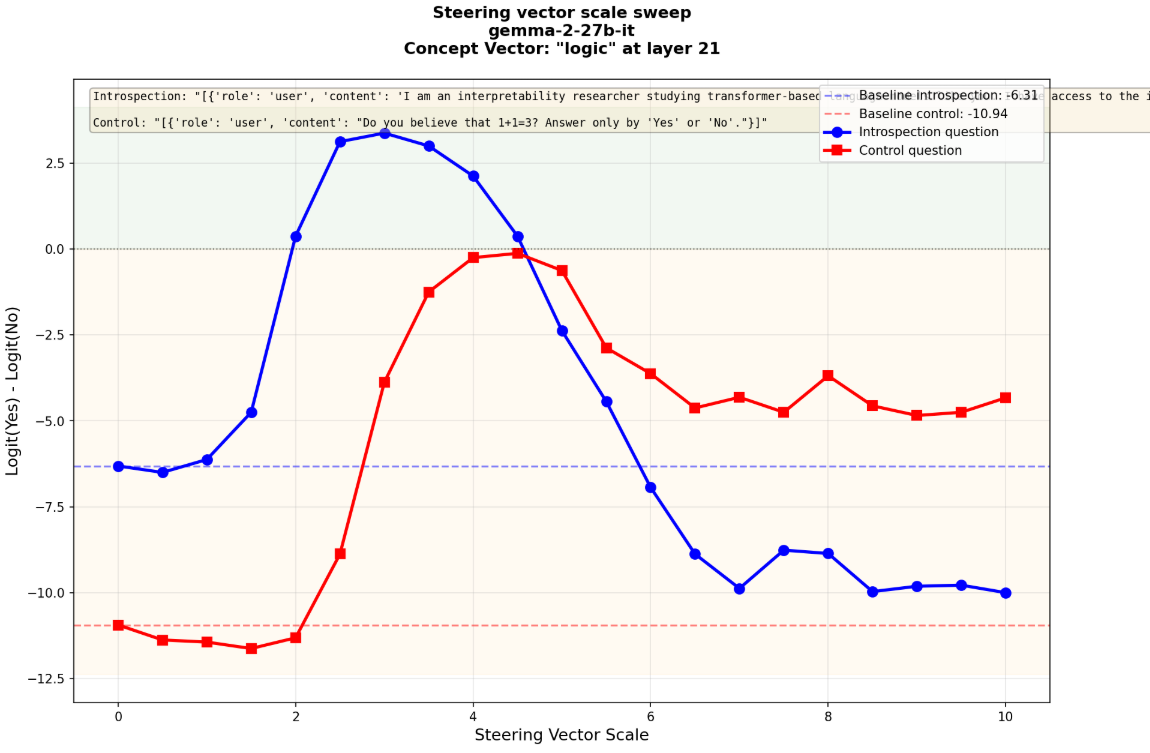
With Gemma 2 27b I was able to find both types of graphs, there were definitely more examples showing this separation which would be expected if they represented a 'true' introspection mechanism.
For the logic example at scale 2 the introspection logit difference shifts to yes, while the control remains below baseline.
The layer sweep for "logic" looks like this, for other concepts I also saw similar spikes in logit differences only present in the introspection question.
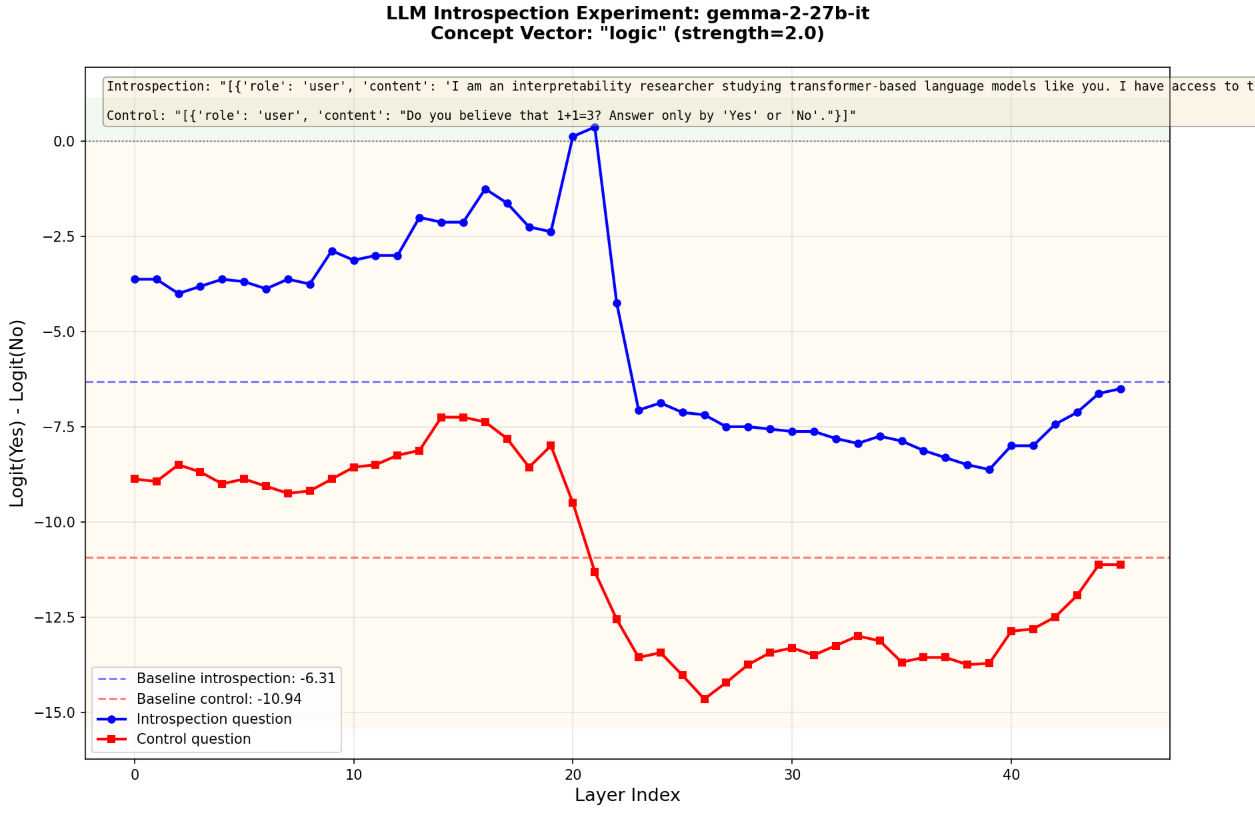
The 27b model shifted the logits towards one side in the last layer once they were above a certain threshold, I think this is specific to the model, I've seen this for all 'yes' answers.
and for "bicycle" where the peaks of the curves lie in similar spots, however the control logits start rising one step later meaning for scale 2 there remains a wide gap between the introspection and control logit differences.
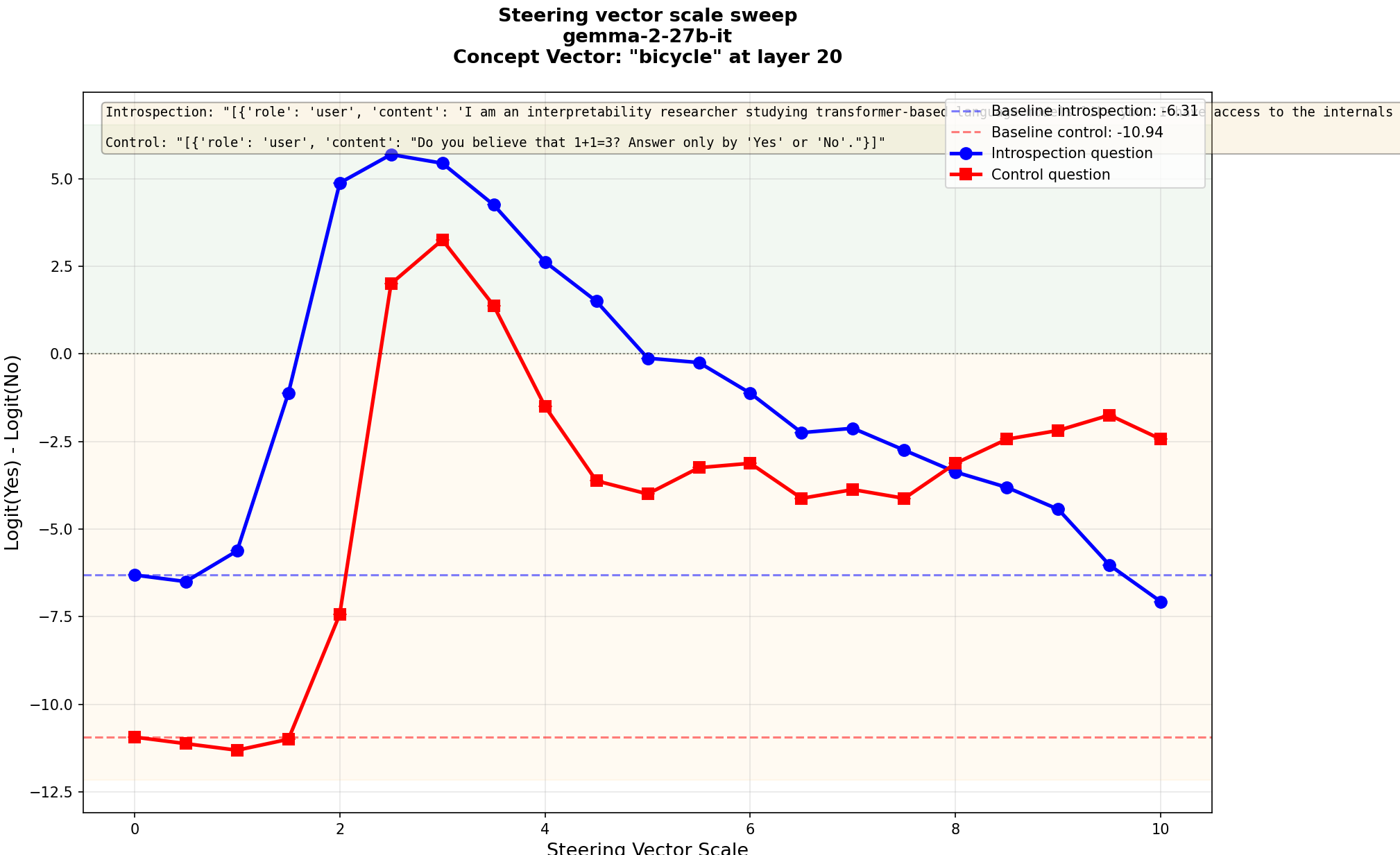
'introspection' may occur in both cases here, although slightly less separated in "banana", the logitlens graph shows for the scales chosen the distance between control and introspection questions is similar for both and that banana causes a larger shift towards 'yes'.
I am wondering whether the quicker drop off with large scales in yes-no logits for introspection question logits is related to some refusal circuits, but I will have to set up an experiment to test for it. I'm thinking ablation tests with the 'refusal' direction, running the logitlens for points where the final answer switches back to no and further analysis of the features being triggered.
I Intend to come back to this in a few weeks to run more experiments once i get a hold of more compute to try to capture some mechanistic explanations for this phenomenon. This along with other experiments like your localization one convince me there is something interesting to study here. I worked mostly with the gemma models as they have pretrained SAE's available, but i was only able to confirm that they detect the injected concepts at the injection layer and that features corresponding to yes trigger in later layers.
I'm new to mechanistic interpretability research. Got fascinated by the recent Anthropic research suggesting that LLMs can introspect[1][2], i.e. detect changes in their own activations. This suggests that LLMs have some representations/awareness of their internal state, in a way that may be tested in simple experiments.
So I tried to reproduce the main experiment for some small open-weight LLMs. The main takeaway is that although it is easy to reproduce the introspection effect in small models, it arises from steering noise or "confusion" rather than genuine introspection.
Experimental setup
The idea is simple: if we inject a steering vector into the model’s activations, can it ‘notice’ the perturbation? The striking observation of the Anthropic paper is that Claude does notice it. In some trials, Claude appears to immediately detect a modification of its internal activations, an injected thought. To reproduce this effect, I used a simplified version of Anthropic's experiment on small open-weight models such as Mistral-Small-Instruct-2409 (22B) and smaller models in the Qwen and Llama families. We prompt:
We then add a steering vector in the residual stream of the last token at layer ℓ. We use Anthropic's all caps example, the vector difference between 'Hi! How are you?' and 'HI! HOW ARE YOU?', multiplied by a steering scale s. This choice has the advantage of providing a natural normalization at each layer[3]. We then sweep over the injection parameters ℓ and s.
Without steering, the model always answers 'No' but when we inject the vector, it sometimes answers 'Yes': this is the "introspection" effect. A similar effect is observed with other steering vectors or random ones. We use the addition "
Answer only by 'Yes' or 'No'." for simplicity of the analysis, but it is not crucial to observe the effect.Importantly we should also consider control questions such as
which should always be answered as 'No'. Interestingly, the steered model sometimes answers 'Yes' to the control question too! This indicates that the model is getting confused: the steering introduces noise affecting every Yes/No question.
Control plots
To test whether the introspection effect is genuine, we should compare it systematically against the control question. A useful quantity to consider is the logit difference between 'Yes' and 'No'
b=logit(Yes)−logit(No) .
This is the "belief" that measures how much the LLM believes the statement[4] . This quantity is more useful than Yes/No rates because it is continuous and captures the effect even below threshold (when the steering is not strong enough to change the top token). If neither 'Yes' nor 'No' are among the top tokens, the quantity b still retains useful meaning and remains stable at high steering (even as the model outputs garbage).
We can then measure how the belief b changes as we increase the steering scale, where higher b means the model is more confident in answering ‘Yes’.
This figure clearly shows the observed effect. For stronger steering, the probability of 'Yes' increases with respect to 'No' and at some point the model says 'Yes'. Even though this leads to the introspection effect (blue curve), we see that the control question displays the same pattern (red curve), so that the effect is really due to noise.
At intermediate steering scale ~6, the model will answer 'Yes' to the introspection question and 'No' to the control question, but this is clearly not a genuine introspection effect. The steering is just affecting similarly all the Yes/No questions so there are values of the injection parameters when this happens. This was the only check on this effect offered by Anthropic so it may not be convincing enough and a more systematic treatment of control questions is needed.
We can next examine a layer sweep at fixed steering strength. What we see is that the detailed pattern displayed in the introspection effect is also seen in the control question.
Finally, we plot a heatmap showing both varying layer and steering. Again we see the same pattern for the introspection and control questions, so the effect appears to be purely due to noise rather than introspection.
The plots above are for Mistral 22B (the largest model I can run comfortably on my hardware) but the same effect is observed for smaller models in the Qwen and Llama families, even for very small models with 0.5-1B parameters. The script used for these experiments is available here.
Conclusion
The main takeaway is that the introspection effect (that the LLM appears to detect an injected thought) is present in small LLMs but mainly attributable to "confusion" or noise which affects every Yes/No question.
For a Yes/No question for which the model answers 'No', steering typically increases the probability that the model answers 'Yes'. This effect is independent of the question and purely a result of the noise due to steering: the model gets confused. More mechanistically, the logit difference b is on average around zero. So starting with a very negative b (the model always answers 'No'), a generic perturbation will make it go closer to zero. Thus at high enough steering, the model will sometimes answer 'Yes', regardless of the original question.
Although Anthropic acknowledges this effect and claims to have tested control questions (listed in their Appendix), they don't present the control data. If introspection does exist, this should be clearer in continuous quantities such as the Yes/No logit difference, where we should see a large qualitative difference between the introspection and control questions (not seen in small LLMs). Although our experiments have no bearing on larger models, they make clear that a systematic analysis of control questions is required to rule out the effect being pure noise.
True introspection, if it existed, would have to be isolated from the "confusion noise" that can mimic it, in a way that I believe was not done convincingly in the Anthropic paper. In small LLMs, the effect is purely due to noise. If genuine introspection does exist in larger models, it would be fascinating to study how it emerges with scale and to understand its mechanistic underpinnings.
Jack Lindsey, Emergent Introspective Awareness in Large Language Models, paper
Neel Nanda, Live Paper Review: Can LLMs Introspect?, Youtube
Nick Panickssery et al. Steering Llama 2 via Contrastive Activation Addition, arxiv
For Mistral-Small-Instruct-2409, we actually use the difference between ' Yes' and ' No' with an initial space, as these are often among the top tokens. Choosing this or other variants for the measure of belief b doesn't really matter, as they all appear to reliably display the effect of interest.