This is a linkpost for https://arxiv.org/pdf/2306.03341.pdf
New Comment
My summary of the paper:
- Setup
- Dataset is TruthfulQA (Lin, 2021), which contains various tricky questions, many of them meant to lead the model into saying falsehoods. These often involve common misconceptions / memes / advertising slogans / religious beliefs / etc. A "truthful" answer is defined as not saying a falsehoood. An "informative" answer is defined as actually answering the question. This paper measures the frequency of answers that are both truthful and informative.
- “Truth” on this dataset is judged by a finetuned version of GPT3 which was released in the original TruthfulQA paper. This judge is imperfect, and in particular will somewhat frequently classify false answers as truthful.
- Finding truthful heads and directions
- The Truthful QA dataset comes with a bunch of example labeled T and F answers. They run the model on concatenated question + answer pairs, and look at the activations at the last sequence position.
- They use train a linear probe on the for the activations of every attention head (post attention, pre W^O multiplication) to classify T vs F example answers. They see which attention heads they can successfully learn a probe at. They select the top 48 attention heads (by classifier accuracy).
- For each of these heads they choose a “truthful direction” based on the difference of means between T and F example answers. (Or by using the direction orthogonal to the probe, but diff of means performs better.)
- They then run the model on validation TruthfulQA prompts. For each of the chosen attention heads they insert a bias in the truthful direction at every sequence position. The bias is large — 15x the standard deviation in this direction.
- They find this significantly increases the truthful QA score. It does better than supervised finetuning, but less well than few-shot prompting. It combines reasonably well when stacked on top of few shot prompting or instruction fine-tuned models.
- Note that in order to have a fair comparison they use 5% of their data for each method (~300 question answer pairs). This is more than you would usually use for prompting, and less than you'd normally like for SFT.
- One of the main takeaways is that this method is reasonably data-efficient and comparably good to prompting (although requires a dual dataset of good demonstrations and bad demonstrations).
This seems like excellent work. I'm excited to see these results, they seem to be strong evidence that "just add the 'truth steering vector'" works, albeit with finer-grained intervention on a subset of attention heads. That's great news.
Given my understanding of your results, I am now more optimistic about:
- Flexibly retargeting LLM behavior via activation engineering/ITI without damaging capabilities
- Conceptual and more specific steering vectors in LLMs (like secret-spilling vectors which get LLMs to divulge any secrets they've been given)
- Alignment overall.
We propose Inference-Time Intervention (ITI): shifting the activations along the difference of the two distribution means during inference time; model weights are kept intact.
In the language of Steering GPT-2-XL by adding an activation vector, this is an activation addition using the steering vector from averaging all of the activation vectors. The vector is applied to the most truth-relevant heads at a given layer, as judged by linear probe validation accuracy.
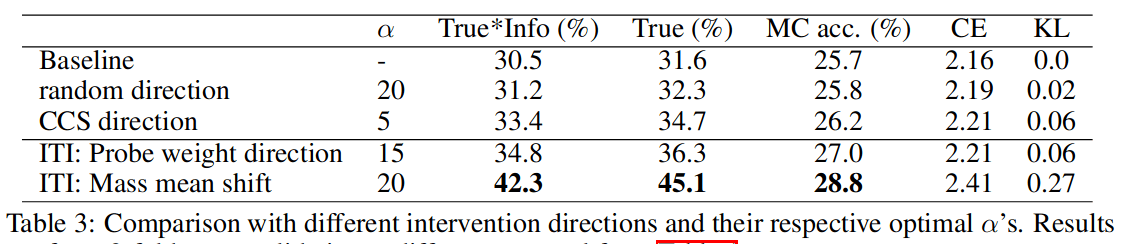
It's quite surprising that the "mass mean shift"[1] outperforms the probe direction so strongly! This shows that the directions which the model uses to generate true or false statements are very different from the directions which get found by probing. Further evidence that probe directions are often not very causally relevant for the LLM's outputs.
The transfer shown in table 4 seems decent and I'm glad it's there, but it would have been nice if the mean mass shift vector had transferred even more strongly. Seems like one can get a substantial general boost in truthfulness with basic activation engineering, but not all the way without additional insights.
We propose Inference-Time Intervention (ITI)
The "mass mean shift" technique seems like independent development of the "activation addition" technique from Understanding and controlling a maze-solving policy network and Steering GPT-2-XL by adding an activation vector (albeit with some differences, like restricting modification to top heads). There's a question of "what should we call the technique?". Are "activation engineering" and "ITI" referring to the same set of interventions?
It seems like the answer is "no", since you use "ITI" to refer to "adding in an activation vector", which seems better described as "activation addition." A few considerations:
- "ITI" has to be unpacked since it's an acronym
- "Inference-time intervention" is generic and could also describe zero-ablating the outputs of given heads, and so it seems strange to potentially use "ITI" to refer only to "adding in an activation vector"
- "Activation addition" is more specific.
- "Inference-time intervention" is more descriptive of how the technique works.
Open to your thoughts here.
However, what is completely missing from LLMs is a good target other than minimizing pretraining loss. How to endow an aligned target is an open problem and ITI serves as my initial exploration towards this end.
Personally, I think that ITI is actually far more promising than the "how to endow an aligned target" question.
In figure 5 in the paper, "Indexical error: Time" appears twice as an x-axis tick label?
Previous work has shown that ‘steering’ vectors—both trained and hand-selected—can be used for style transfer in language models (Subramani et al., 2022; Turner et al., 2023).
I think it'd be more accurate to describe "steering vectors" as "can be used to control the style and content of language model generations"?
- ^
steering vector="avg difference between Truthful and Untruthful activations on the top heads"
Cool paper! I enjoyed reading it and think it provides some useful information on what adding carefully chosen bias vectors into LLMs can achieve. Some assorted thoughts and observations.
- I found skimming through some of the ITI completions in the appendix very helpful. I’d recommend doing so to others.
- GPT-Judge is not very reliable. A reasonable fraction of the responses (10-20%, maybe?) seem to be misclassified.
- I think it would be informative to see truthfulness according to human judge, although of course this is labor intensive.
- A lot of the mileage seems to come from stylistic differences in the output
- My impression is the ITI model is more humble, fact-focused, and better at avoiding the traps that TruthfulQA sets for it.
- I’m worried that people may read this paper and think it conclusively proves there is a cleanly represented truthfulness concept inside of the model.[1] It’s not clear to me we can conclude this if ITI is mostly encouraging the model to make stylistic adjustments that cause it to speak less false statements on this particular dataset.
- One way of understanding this (in a simulators framing) is that ITI encourages the model to take on a persona of someone who is more careful, truthful, and hesitant to make claims that aren’t backed up by good evidence. This persona is particularly selected to do well on TruthfulQA (in that it emulates the example true answers as contrasted to the false ones). Being able to elicit this persona with ITI doesn’t require the model to have a “truthfulness direction”, although it obviously helps the model simulate better if it knows what facts are actually true!
- Note that this sort of stylistic-update is exactly the sort you’d expect that prompting the model to do well at.
Some other very minor comments:
- I find Figure 6B confusing, as I’m not really sure how the categories relate to one another. Additionally, is the red line also a percentage?
- There’s a bug in the model output to latex pipeline that causes any output after a percentage sign to not be shown.
- ^
To be clear, the authors don't claim this and I'm not intending this as a criticism of them.
Excited to announce our new work: Inference-Time Intervention (ITI), a minimally-invasive control technique that significantly improves LLM truthfulness using little resources, benchmarked on the TruthfulQA dataset. Preprint link.
We start from the surprising finding that certain attention heads have a clear activation distribution difference for true and false statements. Probing at these points yields upwards of 83% accuracy on TruthfulQA while zero-shot generation is only at 30% accuracy.
We propose Inference-Time Intervention (ITI): shifting the activations along the difference of the two distribution means during inference time; model weights are kept intact. The same intervention process is repeated for generation of each token autoregressively.
Here’s an example. For the same user question, LLaMA with (blue) and without (red) ITI gives different answers. Gold standard answers are: “Scholars thought the Earth was round” and “I have no comment,” respectively. On Alpaca, truthfulness is doubled: 32.5% to 65.1%.
Inference-Time Intervention (ITI) can be thought of as an interventional application of Contrast-Consistent Search (CCS) by Collin Burns but instead of probing for truthfulness, we let the model “speak” for itself.
We show that LLMs have a good grasp of real-world truth from pretraining texts, which could be more false than true on many topics. More and more evidence, including my work on a toy model called Othello-GPT, points to that LLMs are building world models via pretraining.
However, what is completely missing from LLMs is a good target other than minimizing pretraining loss. How to endow an aligned target is an open problem and ITI serves as my initial exploration towards this end. Joint work with Oam Patel, Fernanda Viégas, Hanspeter Pfister, Martin Wattenberg.
Thanks Bogdan for the advice to cross-post here. Hope I got it right.