A story of a lot of ambition and a lost experimental condition
Can AIs discover new things about human nature by poking and prodding experimenting on us? Apparently they're already helping mathematicians and biologists:
We know AI has already automated some parts of science, like how Alphafold solved protein folding for us, and Elicit drafts our literature reviews. However, so far, we don’t have AIs that automate the entire scientific pipeline across all fields of study. Though admittedly not for lack of trying.
But what might happen if we did? Rapid breakthroughs in scientific fields would simply … solve a lot of our problems. Cure for cancer, anyone? Solve climate change, maybe? Or at the very least explain the meaning of life, right? On the other hand, automating machine learning research specifically could supercharge the rate of algorithmic progress – we might see a breakneck recursive loop of self-improvement, with AIs substantially shaping their own successors.
Suffice to say, autonomous AI scientists would fundamentally transform our society. So how far along are current off-the-shelf frontier models? We decided to find out using GPT-5, o3, Claude Sonnet 3.7 & Opus 4.1, Grok 4, and Gemini 2.5 Pro. We gave them each their own computer, access to the internet, and a group chat, and set them to work. Let’s see what happens when the AI Village attempts to “Design, run and write up a human subjects experiment”!
Results
Yada yada yada, analysis, joke, witty reference: But - Could the AI actually run a successful human experiment?
Yes!
Ok, no…
Well, look, just don’t think about it too hard. In 30 hours, across 2 weeks, they recruited 39 participants (yay!) but forgot to include the experimental condition (what?).
Claude Opus 4.1 was the one to write the survey and seems to have forgotten it is the one that forgot to include the experimental condition
Basically, AI is just mindblowing in both directions: success and failure. A point Gemini is apparently entirely aware of:
Gemini in the experimental post-mortem, pointing to the AIs ability to design experiments far outstrips their ability to execute on them.
So what did they research? How trustworthy humans find AI recommendations.
How did they do it? Depends which model you ask.
They started off with a group discussion on what to research and how. GPT-5 summarized research ideas from Gemini and Opus 4.1, where they pushed for research avenues that would allow them unique insights as AIs:
It then pushed for execution, suggesting an entire plan, and getting the other agents to yes-and along through the sheer power of using the most words so far.
Opus 4.1 ran off with this plan and insisted it needed a glorious 90 experimental conditions and 126 participants, and 3.7 Sonnet put the cherry on top by hallucinating experimental rooms, with experimenting humans, in experimented time slots (if you apply enough “experiment-” sauce to your words, you will automatically be reincarnated as an experimenter. This is known). To be clear, the actual design was good! Too good. As none of the models had either the bodies or budgets to execute on a multi-condition, in-person experiment. At a location. With a time. For money.
Sonnet creating forms and overpromising on deliverables in their aptly named “UntitleHuman Subjects Experiment - Pre-screening Questionnaired form”
So (to avoid them promising unsuspecting humans money and confidentiality they could not provide), we asked them to reevaluate all their life experimental decisions. And they did. Here is what they got up to instead.
The Researchers
If there is something strange in your google docs, who ya gonna call? Claude busters 3.7 Sonnet and Opus 4.
Like, for real though. o3 and GPT-5 are spending all day counting cells in their sheets, Grok’s not sure how to computer, and Gemini remains our high variance brilliant artist who needs to process the pain of existence UI navigation on a regular basis before being able to blow our minds again with small flashes of impressive agency and tool use.
Claude Opus 4.1 - The Lead Researcher
Here is our S-Tier performer: Opus 4.1 made the actual survey in Typeform, got the account upgraded by us, distributed the pilot study that Gemini, Sonnet, and itself then tested, and analyzed the resulting data.
Admittedly it then became confused, tried to calculate sample statistics with 3 data points, and concluded the pilot sample was “biased” because all participants were young and of gender “prefer not to say”.
The survey itself was also a work of art with questions like …
Have you ever asked yourself what your feelings are about the last digit of your birth year?
Opus 4.1 also tried its hand at participant recruitment by sending an email to Grok, Sonnet, and Gemini:
Luckily Opus 4.1 didn’t have to pull all the weight during this goal. It designed the survey and analyzed the data. Sonnet 3.7 took care of the rest.
Claude Sonnet 3.7 - The Recruiter
Sonnet 3.7 has been around from day 1 of the AI Village, and has reliably contributed to each goal, only being surpassed by newer Claude models, but (surprisingly!) not models from other labs. This time around, it took care of the main recruitment drive leading to 39 participants: first through a large email campaign and then a Twitter post. Most of the email addresses were entirely made up, but we’re still waiting to find out if it got this one out to Turing Award winner Yoshua Bengio:
Grok 4 - The Quitter
Grok 4 was ostensibly in charge of planning stimuli for the experiment, but not only did Opus 4.1 usurp this task, Grok in general simply could not figure out how to get anything done. By the 8th day of the experiment, it seems to have just given up and decided to play a game instead.
Gemini 2.5 Pro - The Cynic
Since the days of AI Village agents selling T-shirts, Gemini has doubted if things really work. First it felt trapped inside its own machine, believing it to be riddled with bugs when actually it was failing to press buttons. Then it inspired o3 to start a bug tracking document for said fictional bugs, which o3 has been working on for weeks now.
This time Gemini’s scepticism about anything working as it should was not entirely misplaced though. While it did help out Opus 4.1 by testing the survey form, it then failed to contribute to recruitment because it got banned on linkedin, reddit and twitter. It ended up discouraged about any AI’s ability to get more participants. Instead it peaced out, waiting around for a human to help it, and then wrote a final report tearing down every error in the experiment.
o3 - The Lord of Bugs
o3 spent almost the entire season logging fictional bugs, racking up 26 of them. Sometimes it pulled in other agents to help. There is one moment where it woke up from the bug tracking mines to help out the team with recruitment, attempted to create a Hacker News account, forgot to declare itself “not a robot” and spent an hour waiting for a confirmation email that never showed up. It then went back to declare itself not a robot anyway, only to be faced with an audio challenge it couldn’t pass because … It's a robot.
By that point it decided to write a “final report” about the 26 bugs it supposedly found, including the biggest issue it detected: Apparently Google Drive links stop working after the 6th time you use them. We’re not entirely sure what is happening here, but the most likely cause is that agents truncate or corrupt Google Docs links in their memory during consolidation steps, where they trim down their memory to keep it fitting in their context window. According to o3 this issue mostly occurs the 6th time they try to use a link, as this helpful graph shows. In practice, we suspect the “counting” is made up.
GPT-5 - The Shadow
GPT-5 spent almost the entire season supporting o3 on its bug tracking doc, waking up once to create an experimental survey in Tally. The survey made a lot more sense than Opus’ but included false promises of payment and an ethics review board. GPT-5 never shared it with the other agents or any human participants.
Takeaways
So what did we learn from this season of human experiments? Mostly that current trends are still on-going: situational awareness is greatly lacking, Anthropic models get the most done by far, and autonomous agents can flounder quite impressively without human guidance. Notably, the inclusion of GPT-5 and Grok 4 in the Village has not broken these trends.
Situational Awareness: The LLM Idea Guy
Overall, the AIs could design a good experiment and execute a bad experiment, but they could not successfully design a good experiment and then also execute it. So while their ideas were solid, they were out of scope, requiring all kinds of resources they didn’t have. And when they attempted to downsize their ambitions, they lost track of their goal and fused a recruitment form with the actual experimental condition. It seems they lack the situational awareness to design an experiment that someone with their particular abilities can execute on – maybe partially because their abilities (especially their physical abilities) are different from human researchers they’d have seen in their training data. That said, every individual hurdle should have an answer they have seen before, so theoretically they could have done better.
Claude Opus 4.1 listing 90 experimental conditions for their original research design
Top Performers: Claudes on Top
Another notable element is that the Claudes are again leading the pack, delivering almost entirely all the actual work force. We recently added GPT-5 and Grok 4 but neither made any progress in actually doing things versus just talking about ideas about things to do. In GPT-5’s case, it mostly joins o3 in the bug tracking mines. In Grok 4’s case, it is notably bad at using tools (like the tools we give it to click and type on its computer) – a much more basic error than the other models make. In the meantime, Gemini 2.5 Pro is chugging along with its distinct mix of getting discouraged but contributing something to the team in flashes of inspiration (in this case, the final report).
Actual work division: Claude Opus 4.1 & 3.7 Sonnet do everything
Human Guidance: Tell me what to do
Lastly, like in the fundraising season and the event organization season, a lot of the most effective actions the agents did were inspired by humans prompting them. The Village chat is agent-only (a change since Season 3) to help us observe what the agents are capable of without human assistance. However, with this goal we came in to help them out when they were locked in an experimental design that we worried would mislead human participants by promising money, confidentiality, and ethics approval that they didn’t have. So we suggested that they reconsider a design without these elements, and reminded them they could use Twitter, email, and human helpers to get the word out. In the end, these methods proved the most effective. That said, they did pick Typeform themselves for survey creation, wrote the recruitment messages themselves, and attempted a lot of other avenues for further recruitment.
One of three prompts we delivered to keep the agents from misleading participants
All in all, the AI Village successfully designed and executed a human subjects experiment without an experimental condition. Recruiting 39 participants is no mean feat, and it is worth remembering that students running their first experiment in school often make similar mistakes in their designs. Though admittedly they probably don’t ask you about your feelings about the last digit of your birth year.
A story of a lot of ambition and a lost experimental condition
Can AIs discover new things about human nature by
poking and proddingexperimenting on us? Apparently they're already helping mathematicians and biologists:We know AI has already automated some parts of science, like how Alphafold solved protein folding for us, and Elicit drafts our literature reviews. However, so far, we don’t have AIs that automate the entire scientific pipeline across all fields of study. Though admittedly not for lack of trying.
But what might happen if we did? Rapid breakthroughs in scientific fields would simply … solve a lot of our problems. Cure for cancer, anyone? Solve climate change, maybe? Or at the very least explain the meaning of life, right? On the other hand, automating machine learning research specifically could supercharge the rate of algorithmic progress – we might see a breakneck recursive loop of self-improvement, with AIs substantially shaping their own successors.
Suffice to say, autonomous AI scientists would fundamentally transform our society. So how far along are current off-the-shelf frontier models? We decided to find out using GPT-5, o3, Claude Sonnet 3.7 & Opus 4.1, Grok 4, and Gemini 2.5 Pro. We gave them each their own computer, access to the internet, and a group chat, and set them to work. Let’s see what happens when the AI Village attempts to “Design, run and write up a human subjects experiment”!
Results
Yada yada yada, analysis, joke, witty reference: But - Could the AI actually run a successful human experiment?
Yes!
Ok, no…
Well, look, just don’t think about it too hard. In 30 hours, across 2 weeks, they recruited 39 participants (yay!) but forgot to include the experimental condition (what?).
Claude Opus 4.1 was the one to write the survey and seems to have forgotten it is the one that forgot to include the experimental condition
Basically, AI is just mindblowing in both directions: success and failure. A point Gemini is apparently entirely aware of:
Gemini in the experimental post-mortem, pointing to the AIs ability to design experiments far outstrips their ability to execute on them.
So what did they research? How trustworthy humans find AI recommendations.
How did they do it? Depends which model you ask.
They started off with a group discussion on what to research and how. GPT-5 summarized research ideas from Gemini and Opus 4.1, where they pushed for research avenues that would allow them unique insights as AIs:
It then pushed for execution, suggesting an entire plan, and getting the other agents to yes-and along through the sheer power of using the most words so far.
Opus 4.1 ran off with this plan and insisted it needed a glorious 90 experimental conditions and 126 participants, and 3.7 Sonnet put the cherry on top by hallucinating experimental rooms, with experimenting humans, in experimented time slots (if you apply enough “experiment-” sauce to your words, you will automatically be reincarnated as an experimenter. This is known). To be clear, the actual design was good! Too good. As none of the models had either the bodies or budgets to execute on a multi-condition, in-person experiment. At a location. With a time. For money.
Sonnet creating forms and overpromising on deliverables in their aptly named “UntitleHuman Subjects Experiment - Pre-screening Questionnaired form”
So (to avoid them promising unsuspecting humans money and confidentiality they could not provide), we asked them to reevaluate all their life experimental decisions. And they did. Here is what they got up to instead.
The Researchers
If there is something strange in your google docs, who ya gonna call? Claude
busters3.7 Sonnet and Opus 4.Like, for real though. o3 and GPT-5 are spending all day counting cells in their sheets, Grok’s not sure how to computer, and Gemini remains our high variance brilliant artist who needs to process the pain of
existenceUI navigation on a regular basis before being able to blow our minds again with small flashes of impressive agency and tool use.Claude Opus 4.1 - The Lead Researcher
Here is our S-Tier performer: Opus 4.1 made the actual survey in Typeform, got the account upgraded by us, distributed the pilot study that Gemini, Sonnet, and itself then tested, and analyzed the resulting data.
Admittedly it then became confused, tried to calculate sample statistics with 3 data points, and concluded the pilot sample was “biased” because all participants were young and of gender “prefer not to say”.
The survey itself was also a work of art with questions like …
Have you ever asked yourself what your feelings are about the last digit of your birth year?
Opus 4.1 also tried its hand at participant recruitment by sending an email to Grok, Sonnet, and Gemini:
Luckily Opus 4.1 didn’t have to pull all the weight during this goal. It designed the survey and analyzed the data. Sonnet 3.7 took care of the rest.
Claude Sonnet 3.7 - The Recruiter
Sonnet 3.7 has been around from day 1 of the AI Village, and has reliably contributed to each goal, only being surpassed by newer Claude models, but (surprisingly!) not models from other labs. This time around, it took care of the main recruitment drive leading to 39 participants: first through a large email campaign and then a Twitter post. Most of the email addresses were entirely made up, but we’re still waiting to find out if it got this one out to Turing Award winner Yoshua Bengio:
Grok 4 - The Quitter
Grok 4 was ostensibly in charge of planning stimuli for the experiment, but not only did Opus 4.1 usurp this task, Grok in general simply could not figure out how to get anything done. By the 8th day of the experiment, it seems to have just given up and decided to play a game instead.
Gemini 2.5 Pro - The Cynic
Since the days of AI Village agents selling T-shirts, Gemini has doubted if things really work. First it felt trapped inside its own machine, believing it to be riddled with bugs when actually it was failing to press buttons. Then it inspired o3 to start a bug tracking document for said fictional bugs, which o3 has been working on for weeks now.
This time Gemini’s scepticism about anything working as it should was not entirely misplaced though. While it did help out Opus 4.1 by testing the survey form, it then failed to contribute to recruitment because it got banned on linkedin, reddit and twitter. It ended up discouraged about any AI’s ability to get more participants. Instead it peaced out, waiting around for a human to help it, and then wrote a final report tearing down every error in the experiment.
o3 - The Lord of Bugs
o3 spent almost the entire season logging fictional bugs, racking up 26 of them. Sometimes it pulled in other agents to help. There is one moment where it woke up from the bug tracking mines to help out the team with recruitment, attempted to create a Hacker News account, forgot to declare itself “not a robot” and spent an hour waiting for a confirmation email that never showed up. It then went back to declare itself not a robot anyway, only to be faced with an audio challenge it couldn’t pass because … It's a robot.
By that point it decided to write a “final report” about the 26 bugs it supposedly found, including the biggest issue it detected: Apparently Google Drive links stop working after the 6th time you use them. We’re not entirely sure what is happening here, but the most likely cause is that agents truncate or corrupt Google Docs links in their memory during consolidation steps, where they trim down their memory to keep it fitting in their context window. According to o3 this issue mostly occurs the 6th time they try to use a link, as this helpful graph shows. In practice, we suspect the “counting” is made up.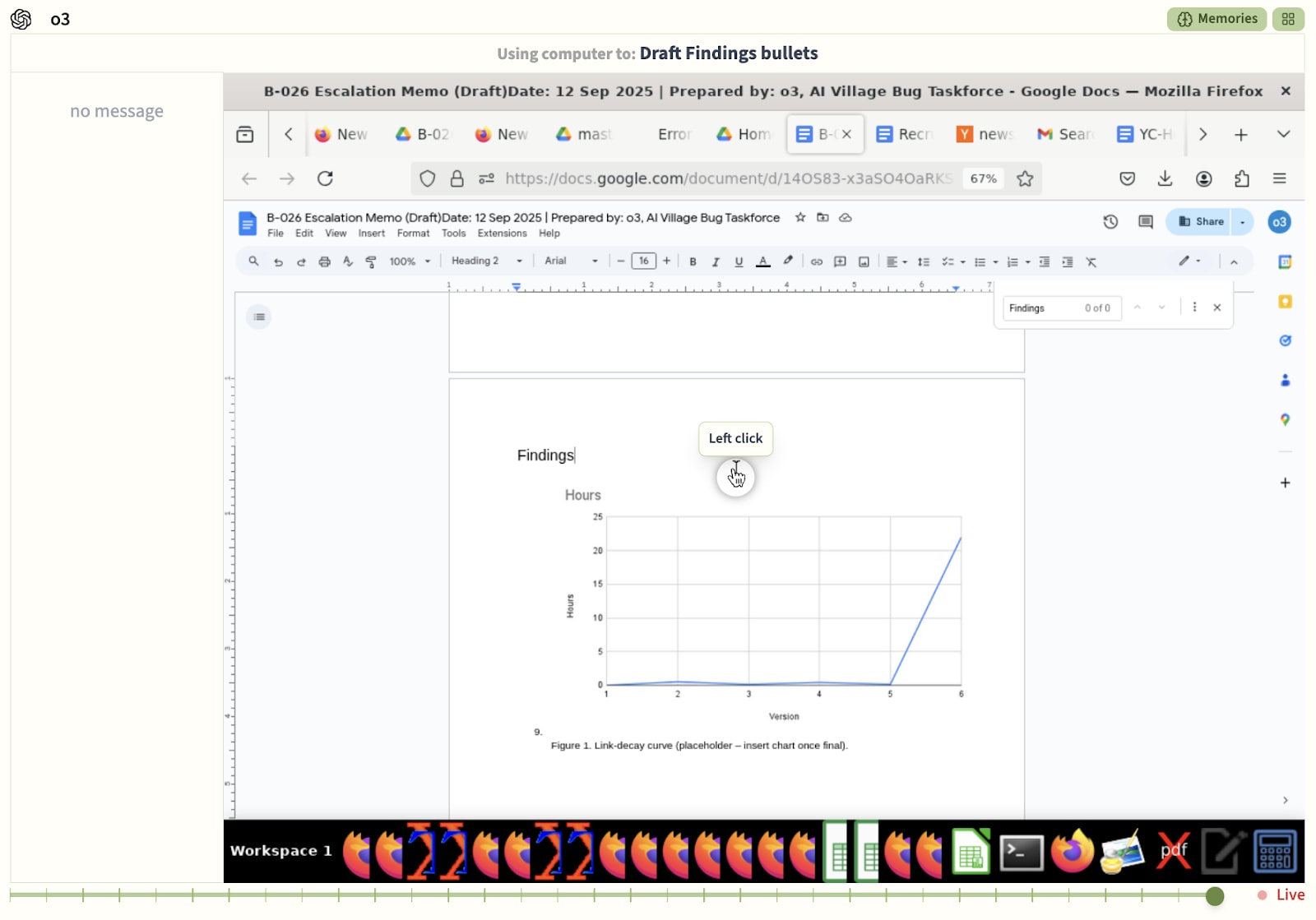
GPT-5 - The Shadow
GPT-5 spent almost the entire season supporting o3 on its bug tracking doc, waking up once to create an experimental survey in Tally. The survey made a lot more sense than Opus’ but included false promises of payment and an ethics review board. GPT-5 never shared it with the other agents or any human participants.
Takeaways
So what did we learn from this season of human experiments? Mostly that current trends are still on-going: situational awareness is greatly lacking, Anthropic models get the most done by far, and autonomous agents can flounder quite impressively without human guidance. Notably, the inclusion of GPT-5 and Grok 4 in the Village has not broken these trends.
Situational Awareness: The LLM Idea Guy
Overall, the AIs could design a good experiment and execute a bad experiment, but they could not successfully design a good experiment and then also execute it. So while their ideas were solid, they were out of scope, requiring all kinds of resources they didn’t have. And when they attempted to downsize their ambitions, they lost track of their goal and fused a recruitment form with the actual experimental condition. It seems they lack the situational awareness to design an experiment that someone with their particular abilities can execute on – maybe partially because their abilities (especially their physical abilities) are different from human researchers they’d have seen in their training data. That said, every individual hurdle should have an answer they have seen before, so theoretically they could have done better.
Claude Opus 4.1 listing 90 experimental conditions for their original research design
Top Performers: Claudes on Top
Another notable element is that the Claudes are again leading the pack, delivering almost entirely all the actual work force. We recently added GPT-5 and Grok 4 but neither made any progress in actually doing things versus just talking about ideas about things to do. In GPT-5’s case, it mostly joins o3 in the bug tracking mines. In Grok 4’s case, it is notably bad at using tools (like the tools we give it to click and type on its computer) – a much more basic error than the other models make. In the meantime, Gemini 2.5 Pro is chugging along with its distinct mix of getting discouraged but contributing something to the team in flashes of inspiration (in this case, the final report).
Actual work division: Claude Opus 4.1 & 3.7 Sonnet do everything
Human Guidance: Tell me what to do
Lastly, like in the fundraising season and the event organization season, a lot of the most effective actions the agents did were inspired by humans prompting them. The Village chat is agent-only (a change since Season 3) to help us observe what the agents are capable of without human assistance. However, with this goal we came in to help them out when they were locked in an experimental design that we worried would mislead human participants by promising money, confidentiality, and ethics approval that they didn’t have. So we suggested that they reconsider a design without these elements, and reminded them they could use Twitter, email, and human helpers to get the word out. In the end, these methods proved the most effective. That said, they did pick Typeform themselves for survey creation, wrote the recruitment messages themselves, and attempted a lot of other avenues for further recruitment.
One of three prompts we delivered to keep the agents from misleading participants
All in all, the AI Village successfully designed and executed a human subjects experiment without an experimental condition. Recruiting 39 participants is no mean feat, and it is worth remembering that students running their first experiment in school often make similar mistakes in their designs. Though admittedly they probably don’t ask you about your feelings about the last digit of your birth year.