o3 and o4-mini solve more than zero of the >1hr tasks that claude 3.7 got ~zero on, including some >4hr tasks that no previous models we tested have done well on, so it's not that models hit a wall at 1-4 hours. My guess is that the tasks they have been trained on are just more similar to HCAST tasks than RE-Bench tasks, though there are other possibilities.
Okay, that’s a lot more convincing. Was it available publicly? I seem to have missed it. Surprisingly high success probability on a 16 hour task - does this just mean it made some progress on the 16 hour task?
Pokémon fell today too, we might be cooked.
The RE-bench result is just for five tasks, the second graph is for a broader task suite of almost 200 tasks. I wouldn't read much into o3 doing worse than other models at RE-bench because of the small sample.
Epistemic status: Question, probably missing something.
Context
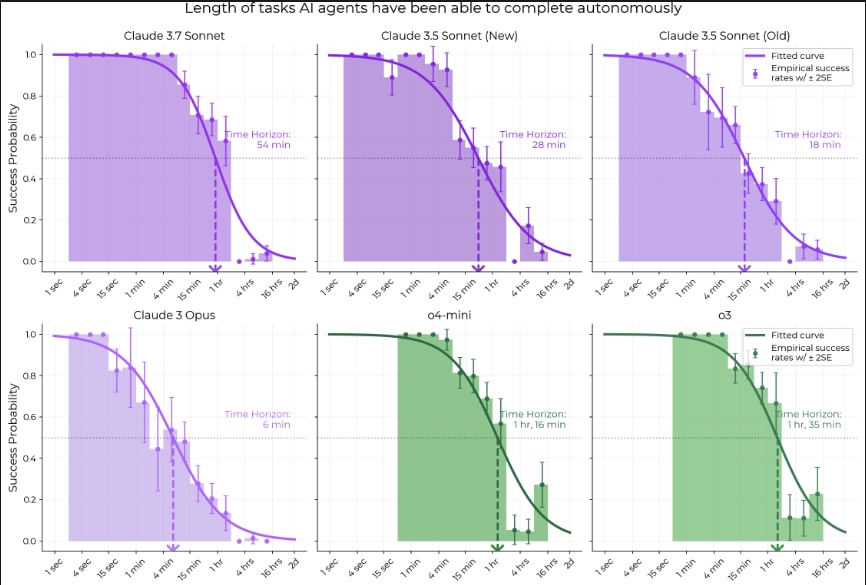
See the preliminary evaluation of o3 and o4-mini here: https://metr.github.io/autonomy-evals-guide/openai-o3-report/#methodology-overview
This follows up important work by METR measuring the maximum human-equivalent lengths of tasks that frontier models can perform successfully, which I predicted would not hold up (perhaps a little too stridently).
I'm also betting on that prediction, please provide me with some liquidity:
Question
o3 doesn't seem to perform too well according to this chart:
But it gets the best score on this chart:
I understand that these are measuring two different things, so there is no logical inconsistency between these two facts, but the disparity does seem striking. Would someone be willing to provide a more detailed explanation of what is going on here? I am not sure whether to update that the task length trend is in fact continuing (or accelerating) or interpret the overall poor performance of o3 as a sign that the trend is about to break down.