This is a special post for quick takes by SorenJ. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
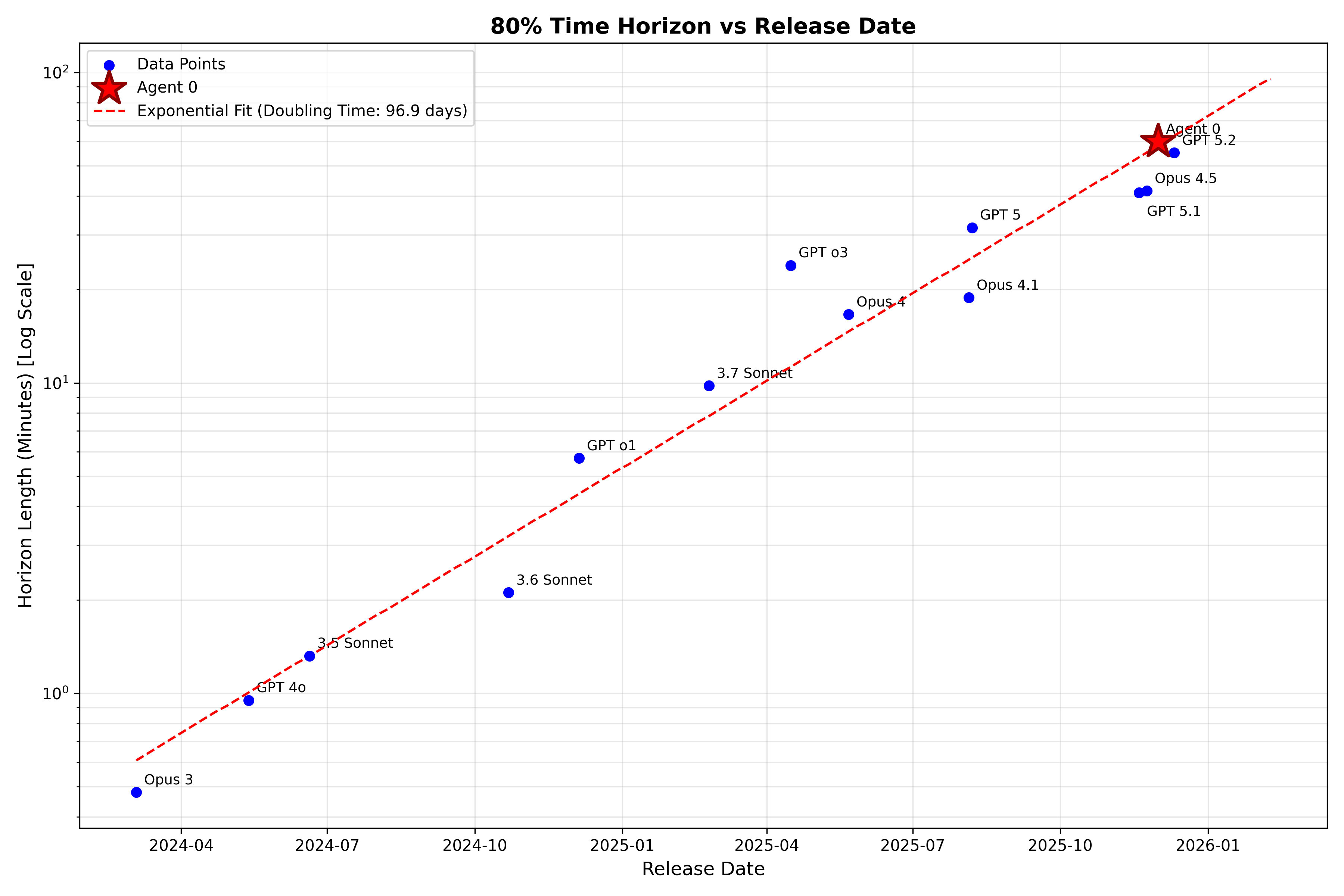
Indeed! Note also that I started the timeline for this fit with Opus 3 as the first model. But I thought this was worth posting, because subjectively it felt like the second half of 2025 went slower than AI2027 prediced (and Daniel even tweeted at one point that he had increased his timelines near EOY 2025), yet by the METR metric we are still pretty close to on track.
Suppose we had a functionally infinite amount of high quality RL-/post-training environments, organized well by “difficulty,” and a functionally infinite amount of high quality data that could be used for pre-training (caveat: from what I understand, the distinction between these may be blurring.) Basically, we no longer needed to do research on discovering/creating new data, creating new RL environments, and we didn’t even have to do the work to label or organize it well (pre/post-training might have some path dependence).
In that case, what pace would one expect for model releases from AI labs in the short term to be? I ask because I see the argument made that AI could help speed up AI development in the near to medium term. But it seems like the main limiting factor is just the amount of time it takes to actually do the training runs.
If your answer is that we’ll have “continual learning” soon, then I have a followup question:
Using the latest hardware, but staying within the same basic architectures, what would one expect the maximum amount of intelligence possible that could be placed on a given N parameter model is? If God skipped the training process and tweaked all the weights individually to reach the global maximum, how smart could, say, GPT 4o be?
For the GPT 4o question, I would expect the global optimum to be at least a medium level of superintelligence, though I have serious doubts that known training methods could ever reach it even with perfectly tuned input.
I realize now that the question wasn’t exactly well formed. God could fill 4o with the complete theory of fundamental physics, knowledge of how to prove the Riemann Hypothesis, etc. That might qualify as super intelligence, but it is not what I was trying to get at. I should have said that the 4o model can only know facts that we already know; i.e., how much fluid intelligence could God pack onto 4o?
I am surprised that you think 4o could reach a medium level of super intelligence. Are you including vision, audio, and the ability to physically control a robot too? I have the intuitive sense that 4o is already crammed to the brim, but I am curious to know what you think.
I'm sure that it is crammed to the brim in one sense, but strongly expect that 99.9% of what it's crammed to the brim with is essentially useless.
Also yes, I was including vision, audio, and motor control in that. It's hard to know exactly where the boundaries lie between facts like "a (dis)proof of the Riemann Hypothesis" and patterns of reasoning that could lead to a (dis)proof of the Riemann Hypothesis if required. I suspect that a lot of what is called "fluid" intelligence is actually pretty crystallized patterns of thought that can be used to generate other thoughts that lead somewhere useful - whether the entity using it is aware of that or not.