More attempts to solve important problems is good. So kudos.
Let me see if I get this straight: see which programs simulate a system, and find the pareto boundary of such programs by ranking them the levin complexity. Then, conditioning your probability distribution on this set, compute its entropy. For a flat pareto boundary, you have a constant levin complexity, really the largest levin complexity which can simulate some system. Is that right?
That would be confusing, because it seem like you can just inject extra code and arbitrary epicycles into a program and retain its type + results, to increase its levin complexity without bound. So I don't see how you can have a pareto frontier.
Now, I understand I'm probably misunderstanding this, so my judgement is likely to change.But I don't think this solution has the right flavour. It seems too ad hoc to work and doesn't match my intuitions.
EDIT:
My intuitions are more like "how abstract is this thing" or how many ideas does this thing permit when I'm thinking of how complex it is, and that seems like what you're suggesting as an intuition as well. Which doesn't quite seem to fit this notion. Like, if I look at it, it doesn't seem to be telling me that "this is the number of sensible abstractions you can have". Unless you view sensible as being pareto optimal in this sense, but I don't think I do. I agree calculating the entropy as a way ot measure number of distinct ideas is elegant though.
That would be confusing, because it seem like you can just inject extra code and arbitrary epicycles into a program and retain its type + results, to increase its levin complexity without bound. So I don’t see how you can have a pareto frontier.
The Pareto frontier consists of those programs with the smallest possible description length/runtime(rather, those programs with an optimal tradeoff between runtime/description -- programs such that you can't make the runtime shorter without increasing the description length and vice versa). So adding extra code without making the program faster wouldn't put you on the Pareto frontier. The Levin complexity is constant along lines of unit slope in my parameterization, so I use it to measure how even the slope of the frontier is.
Like, if I look at it, it doesn’t seem to be telling me that “this is the number of sensible abstractions you can have”
My intuition is that sensible abstractions should either let you (a) compress/predict part of the system or (b) allow you to predict things faster. I think that this captures a lot of what makes abstractions good, although in practice things can be more complicated(e.g. in a human context, the goodness of an abstraction might be related to how well it relates to a broader memeplex or how immediately useful it is for accomplishing a task. I'm trying to abstract(ha) away from those details and focus on observer-independent qualities that any good abstraction has to have)
I agree that the definition is a bit unfortunately ad hoc. My main problem with it is that it doesn't seem to naturally 'hook' into the dynamics of the system -- it's too much about how a passive observer would evaluate the states after the fact, it's not 'intrinsic' enough. My hope is that it will be easier to get better definitions after trying to construct some examples.
It has occasionally been proposed that we need a new algorithmic definition of 'complexity', different from Kolmogorov complexity, that better captures our intuitive sense of which structures in the world are truly complex. Such definitions are typically designed with the goal of assigning a low complexity to extremely simple structures such as a perfectly ordered lattice or an endless string of '0's, but also to totally random objects, unlike Kolmogorov complexity. Instead, one hopes, the objects assigned high complexity will be (binary representations of) things like cathedrals, butterflies, or other objects which we think of as truly possessing a intricate internal structure. Examples of these sorts of proposed definitions include sophistication and logical depth(see here for a nice survey and discussion).
What's the point of such definitions? There's a great tradition in math and science of quantifying vague but conceptually useful notions. Good definitions give you a new way of thinking about the world, and allow you to bring the powerful tools of math and science to bear upon a problem. It's difficult to find powerful ideas like this; attempting to capture our intuitive impressions formally can be a useful first step.
I'd like to introduce a new definition of this sort, with the aim of quantifying the number of different levels on which an object can be usefully described. For example, fluids can admit a microscopic description in terms of individual molecules or a coarse-grained description which specifies the average density in a given region. Planets can be described as collections of vast collections of atoms or as single points(for the purposes of orbital mechanics calculations) Butterflies can be described as bio-chemical systems or as optimizers trying to increase their fitness. An interesting feature of our world is the presence of many such different levels of description; and the existence of individual objects which can be described well in many different ways: we could say that such objects display a high degree of 'emergence'. I think this is one aspect of what causes us to consider objects to be 'truly complex'.
But what does it mean, in algorithmic terms, for there to be more than one way to describe an object? [1] In algorithmic information theory, a description of an object is a program which outputs that object. There are infinitely many possible programs outputting a given string, but the shortest such program is given the most weight under the Solomonoff prior. A naive approach to estimating the 'emergent complexity' might be to count how many short programs there are. Unfortunately, the coding theorem shows that this is unlikely to work very well -- the single shortest program takes up a constant fraction of the entire Solomonoff prior, so there's an upper limit on how 'spread out' the measure can be. And this seems to match the actual situation: in our world, there usually is an absolutely simplest physical level which can explain everything.
So in what sense can there be different, but equally good explanations? We need to find another way of ranking programs besides shortness. One obvious candidate is runtime. Indeed, this seems to be the impetus behind many high-level approximations -- a coarse-grained fluid model can be much faster then a detailed molecular dynamics simulation. Still higher levels of approximation can be still faster, but have a greater description length. So as a candidate definition of complexity, we can consider the number of different levels of description of a given object, with each level manifesting a different tradeoff between runtime and description length.
To formalize this we need to specify how runtime and length should be traded off against each other. One measure combining length and runtime is the Levin complexity, equal to the sum of the length and the logarithm of the runtime. The exponential tradeoff can be motivated by noting that running a search process over strings of size N takes 2^N time. Given such a conversion factor, the different programs printing a given string can be represented graphically. Each program can be plotted in 2d-space, with one axis representing length and the other runtime. There will be a Pareto frontier of programs that are not dominated in both runtime and length. The complexity is then essentially the slope of this frontier -- frontiers with a slope closer to -1 represent more complex objects.
Here are some graphs of this 2-d space. Most strings' shortest program will just consist of printing the string or something nearly as simple, so their Pareto frontier will just look like a dot near the y-axis, moved along the x-axis according to the length of the string: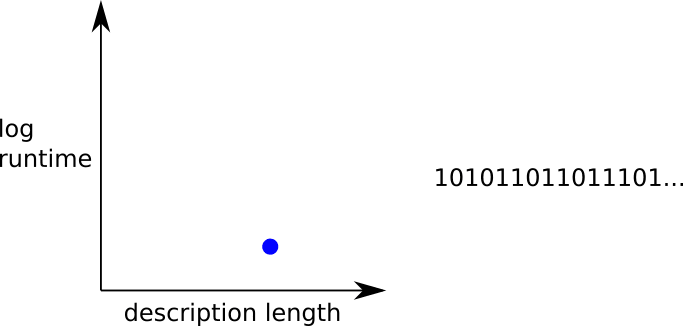
A more interesting class of examples can be found by considering dynamical systems with simple rules and initial conditions, similar to our universe. A deterministic but orderly dynamical system could have a very simple underlying rule, but also possess a hidden symmetry that causes it to have quickly-predictable long-term dynamics -- for instance, a billiard bouncing around a stadium with a regular, periodic motion. This system's Pareto curve would look like an initially high-runtime, low-complexity brute-force simulation, followed by a sharp dip where the model now incorporates the symmetry.
On the other hand, a chaotic dynamical system could have no better way of being predicted than running the dynamics for the entire length of the intended runtime. Here the Pareto curve would look like a plateau followed by a dip representing a program that simply prints the end-state of the evolution.
And finally, we can imagine a dynamical system intermediate between these two, which cannot be easily simplified with a single symmetry, but does have emergent layers of behavior, each of which allows one to speed the simulation by a certain amount. The greater the number of such layers, the more 'emergent complexity' we can say the object exhibits.
Then the question arises of how to define a measure of how 'spread out' a given frontier is. The speed prior, the negative exponential of the Levin complexity, provides one possible answer. The speed prior divides the 2-dimensional space into diagonal lines, with each line representing a constant Levin complexity, and an exponentially varying value of the speed prior. A Pareto frontier with near constant slope will have near constant values of the speed prior on its members, leading to a higher-entropy distribution. This, then, is my proposed complexity measure in full -- the 'emergent complexity' of a string is the entropy of the speed prior on the speed/length Pareto frontier of programs outputting that string.
So, given this measure, now what? The problem, shared with other proposed complexity measures, is that computing the measure in practice is completely intractable numerically, and difficult to approach analytically. So, it's hard to know what relation, if any, it truly bears to our intuitive notion of complexity, or whether it can be proved to be large in any relevant situation. This is basically why I abandoned this idea after I initially came up with it a few years ago. Now, however, it seems to me that further progress could be made by trying to create numerical simulations which directly match our intuitive notion of complexity, using ideas like this as a heuristic guide instead of trying to carry out rigorous proofs(although eventually it might be desirable to try to rigorously prove things). For that, hopefully stay tuned!
I'm going to elide between describing a state of a system and simulating the system's dynamics, because (a) often the most descriptionally-efficient way of obtaining a particular state is by simulating the dynamics leading to that state; (b) the ideas can be adapted in greater detail to either case without too much difficulty, I think, so it doesn't seem important at the level of rigor I'm going for here ↩︎